
线程池
线程池简介
线程池(thread pool):一种线程的使用模式。线程过多会带来调度的开销,进而影响局部和整体性能。而线程池维护多个线程,等待着监督管理者分派并发执行的任务。这避免了在处理短时间任务时创建和销毁线程的代价。线程池不仅能够保证内核的充分使用,还能防止过分调度线程。
10多年前的单核CPU电脑,其实是假的多线程,是线程的切换,实现的”多线程”,因为一个CPU核心同一时刻执行只能有一个线程执行。现在是多核CPU的电脑,多个线程运行在CPU的多个核心上,不用切换,效率高。
线程池优势
线程池的功能就是控制运行的线程的数量,处理过程中将任务放入队列,然后在线程创建后执行这些任务,如果线程数量超过了线程池定义时的最大数量,超出的执行任务的等候,只有线程池中的线程有执行完毕后,才能从线程池中取出线程,用于执行任务。
线程池特点
- 1.降低资源消耗,通过重复利用已创建的线程,降低线程创建和销毁的资源消耗。
- 2.提高响应速度,当任务到达时,有空闲线程的话,不需要等待线程创建就会立即执行。
- 3.提高了线程的可管理性,线程是稀缺资源,不能无限制的创建,使用线程池可用进行统一的分配,调优和监控。
线程池架构
Java中的线程池,是通过Executor框架实现的,该框架中用到了Executor,Executors,ExecutorService,ThreadPoolExecutor这几个类。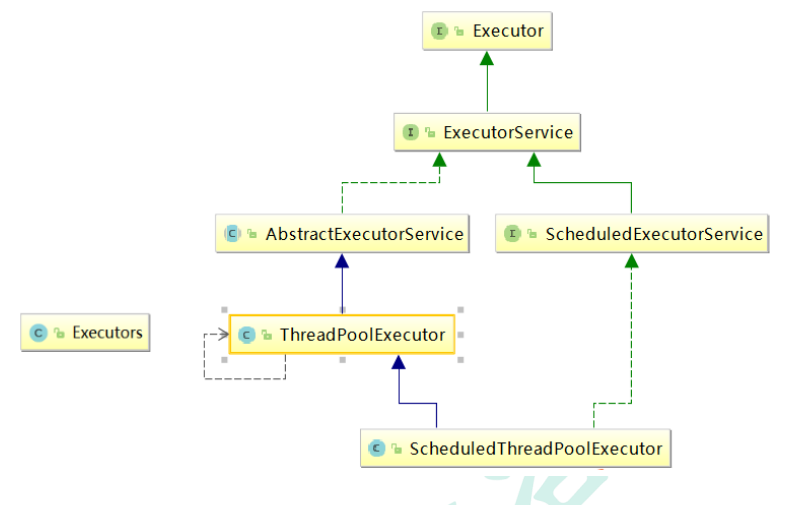
线程池使用方式
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* @author 长名06
* @version 1.0
*/
public class ThreadPoolDemo1 {
public static void main(String[] args) {
//一池N线程池 可自定义数量
ExecutorService threadPool1 = Executors.newFixedThreadPool(5);
//一池1线程池
ExecutorService threadPool2 = Executors.newSingleThreadExecutor();
//可扩容线程池
ExecutorService threadPool3 = Executors.newCachedThreadPool();
try{
for (int i = 0; i < 20; i++) {
//为什么是在执行时,参数是实现了一个Runnable的接口类对象?
//这只是传递一个实现了Runnable的类型的对象。并没有启动线程,也就是说没有创建线程
//只是利用这个参数,将要执行的任务,通过一个Runnable接口实现类的run方法传递给线程池,
//有线程池调度线程执行该任务
//thread.start0()启动线程时,会执行到Thread#run()
/*
@Override
public void run() {
if (target != null) {
target.run();run方法执行的就是target的run()方法,可能在线程池底层,一个线程执行任务
就是将这个要执行的任务对象,赋值给空闲线程的target,当然只是我的猜测,没有看过底层源码
}
}
Exectutors$DefaultThreadFactory#newThread()
public Thread newThread(Runnable r) {//将Runnable r对象赋给一个new Thread
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
*/
threadPool3.execute(() -> {
System.out.println(Thread.currentThread().getName() + "办理业务");
});
}
}catch (Exception e){
e.printStackTrace();
}finally {
threadPool3.shutdown();
}
}
}
线程池的七个参数
以上三个线程池的底层都是ThreadPoolExecutor类
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)构造方法
参数介绍
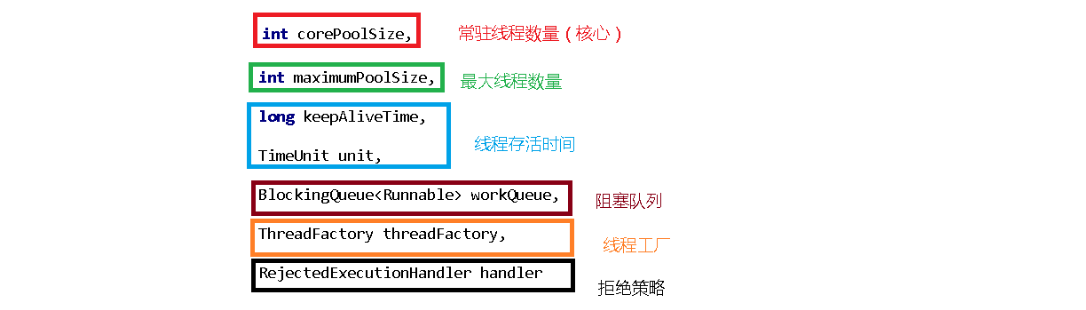
unit是设定存活时间的单位
工作流程和拒绝策略
线程池的拒绝策略,由三个核心参数决定corePoolSize,maximumPoolSize,workQueue
工作流程
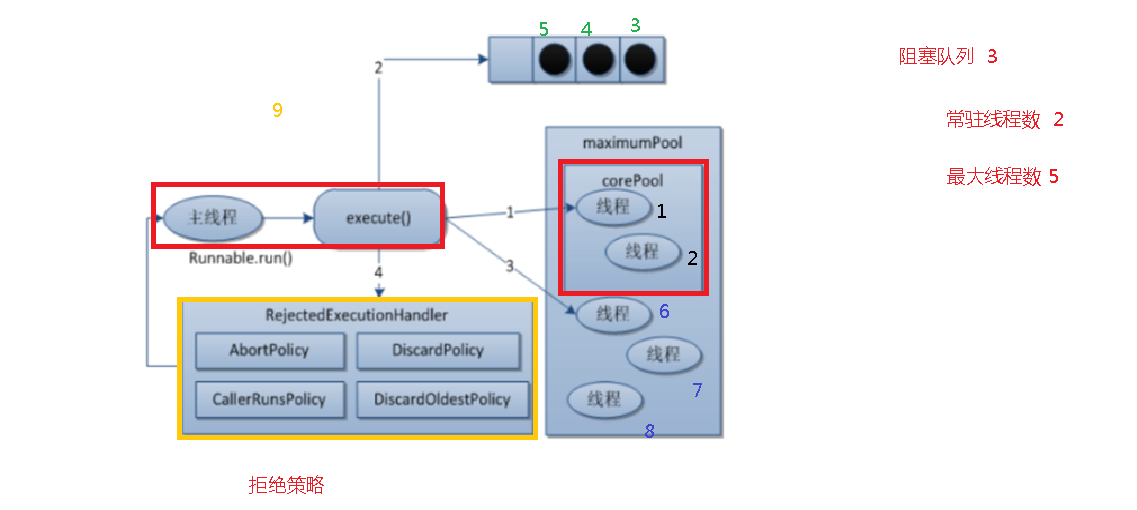
- 1.在创建了线程池后,线程池的线程数为0。
- 2.当调用execute()方法添加一个请求任务时,线程池,会做出如下判断:
2.1 如果正在运行的线程数量小于corePoolSize,那么马上创建线程运行这个任务。
2.2 如果正在运行的线程数量大于或等于corePoolSize,但是阻塞队列没满,那么将这个任务放入队列。
2.3 如果这个时候队列满了且正在运行的线程数量还小于maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务。
2.4 如果队列满了且正在运行的线程数量大于或等于maximunPoolSize,那么线程池会安装拒绝策略执行。 - 3.当一个线程完成任务时,会从队列中取下一任务执行。
- 4.当一个线程无事可做超过keepAliveTime时,线程会判断:
4.1 如果当前运行的线程数大于corePoolSize,该线程会被停掉。
4.2 所以线程池的任务完成后,线程数,会收缩到corePoolSize大小。
JDK内置的拒绝策略

自定义线程池
为什么不使用JDK自带的线程池,原因如下图
代码
public class ThreadPoolDemo2 {
public static void main(String[] args) {
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(
2,//线程池常驻线程数
5,//线程池最大线程数
10L,//存活时间
TimeUnit.SECONDS,//存活时间单位
new LinkedBlockingQueue<Runnable>(10),//阻塞队列
Executors.defaultThreadFactory(),//线程工厂,用以创建线程
new ThreadPoolExecutor.AbortPolicy()//拒绝策略
);
try {
for (int i = 0; i < 10; i++) {
poolExecutor.execute(() -> {
System.out.println(Thread.currentThread().getName() + "办理业务");
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
poolExecutor.shutdown();
}
}
}
只是为了记录自己的学习历程,且本人水平有限,不对之处,请指正。##
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/213051.html

