
目录
一、阻塞队列
在学习Kafka之前,我们需要先了解阻塞队列、以及生产者和消费者模式。

图中:Thread-1为生产者,put往队列里存数据,当队列已满时,该方法将阻塞; Thread-2为消费者,take从队列里取数据,当队列已空时,该方法将阻塞;
阻塞队列用于解决线程异步通信的问题,同时在生产者和消费者之间建立了缓冲,提高了系统的性能。
阻塞队列BlockingQueue是一个接口,我们需要通过其实现类来调用。具体实现如下:
【生产者线程】
class Producer implements Runnable {
// 传入阻塞队列,把线程交予阻塞队列管理
private BlockingQueue<Integer> queue;
public Producer(BlockingQueue<Integer> queue){
this.queue = queue;
}
@Override
public void run() {
try {
for (int i = 0; i < 100; i++) {
Thread.sleep(20);
queue.put(i);// 将数据交予队列
System.out.println(Thread.currentThread().getName() + "生产:" + queue.size());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}【消费者线程】
class Consumer implements Runnable {
// 传入阻塞队列,把线程交予阻塞队列管理
private BlockingQueue<Integer> queue;
public Consumer(BlockingQueue<Integer> queue){
this.queue = queue;
}
@Override
public void run() {
try {
while(true) {
Thread.sleep(new Random().nextInt(1000));
queue.take();// 使用队列中的数据
System.out.println(Thread.currentThread().getName() + "消费:" + queue.size());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}【main函数实例化阻塞队列、生产者和消费者】
public static void main(String[] args) {
// 实例化阻塞队列,生产者和消费者共用一个阻塞队列
BlockingQueue queue = new ArrayBlockingQueue(10);// 默认长度为10
// 实例化生产者线程
new Thread(new Producer(queue)).start();
// 实例化消费者线程
new Thread(new Consumer(queue)).start();
new Thread(new Consumer(queue)).start();
new Thread(new Consumer(queue)).start();
}运行main函数,观察输出结果:

二、Kafka入门
2.1 Kafka概念
【Kafka简介】
Kafka是一个分布式的流媒体平台。
应用:消息系统、日志收集、用户行为追踪、流式处理
【Kafka特点】
- 高吞吐量:处理数据的能力强,可以处理TB级的海量数据,即使是非常普通的硬件Kafka也可以支持每秒数百万的消息
- 消息持久化:通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。 有人会有疑问:读取硬盘中的数据岂不是比读取内存中的数据慢很多?为什么还能保持高性能呢? 实际上,读写硬盘数据性能的高与低,取决于对硬盘的使用,对硬盘的顺序读写的性能其实是很高的,甚至高于内存对数据的随机读写。而Kafka就是采用了对硬盘的顺序读写。
- 高可靠性:分布式服务器,可以做集群部署,有容错的能力。
- 高扩展性:简单的配置即可增加服务器
【Kafka消费模式】
Kafka的消费模式主要有两种:一种是一对一的消费,也即点对点的通信,即一个发送一个接收。第二种为一对多的消费,即一个消息发送到消息队列,消费者根据消息队列的订阅拉取消息消费。
一对一 消息生产者发布消息到Queue队列中,通知消费者从队列中拉取消息进行消费。消息被消费之后则删除,Queue支持多个消费者,但对于一条消息而言,只有一个消费者可以消费,即一条消息只能被一个消费者消费。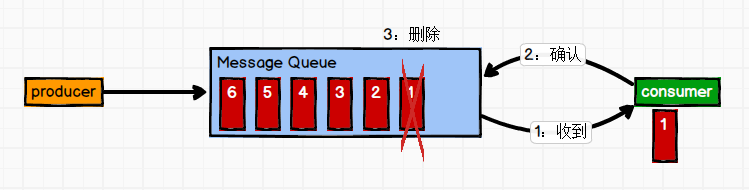
一对多 这种模式也称为发布/订阅模式,即利用Topic存储消息,消息生产者将消息发布到Topic中,同时有多个消费者订阅此topic,消费者可以从中消费消息,注意发布到Topic中的消息会被多个消费者消费,消费者消费数据之后,数据不会被清除,Kafka会默认保留一段时间,然后再删除。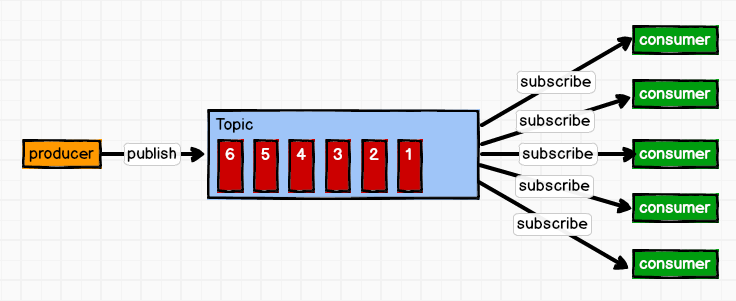
【Kafka术语】

- Broker:Kafka集群包含一个或多个服务器,这种服务器被称为broker
- Topic:主题。生产者把消息发布到的位置/空间,可以理解为一个文件夹,用于存放消息的位置
- Partition:分区。对主题位置的一个分区。每个分区都从队尾追加数据
- offset:索引。消息在分区内存放的索引。
- Consumer Group:消费者组。消费者组则是一组中存在多个消费者。消费者消费Broker中当前Topic的不同分区中的消息,消费者组之间互不影响,所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。某一个分区中的消息只能够一个消费者组中的一个消费者所消费。
- Leader Replica:主副本。对分区数据做备份,提高容错率。当消费者尝试获取数据时,可以做出响应,提供数据。
- Follower Replica:随从副本。只是备份,不做响应。实时的从Leader中同步数据,保持和Leader数据的同步,Leader发生故障的时候,某个Follower会成为新的Leader。
- Zookeeper:独立的软件,管理Kafka的集群
2.2 Kafka下载及配置
【下载】
官网下载地址:

根据建议点击链接即可下载。之后解压到某一文件夹即可。
【配置】
配置config/zookeeper.properties文件
配置config/server.properties文件
【启动】
启动zookeeper(内置):打开命令行,cd到kafka安装目录下,输入以下命令:
bin\windows\zookeeper-server-start.bat config\zookeeper.properties启动Kafka:再打开一个命令行,cd到kafka安装目录下,输入以下命令
bin\windows\kafka-server-start.bat config\server.properties三、Spring整合Kafka
【引入依赖】
<!-- https://mvnrepository.com/artifact/org.springframework.kafka/spring-kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.8.2</version>
</dependency>
【配置Kafka】 在application.properties中添加如下配置:
# KafkaProperties
spring.kafka.bootstrap-servers=localhost:9092
spring.kafka.consumer.group-id=test-consumer-group
spring.kafka.consumer.enable-auto-commit=true
spring.kafka.consumer.auto-commit-interval=3000【测试代码】
Kafka生产者:
@Component
class KafkaProducer {
@Autowired
private KafkaTemplate kafkaTemplate;
public void sendMessage(String topic, String content) {
kafkaTemplate.send(topic, content);
}
}Kafka消费者:
@Component
class KafkaConsumer {
@KafkaListener(topics = {"test"})
public void handleMessage(ConsumerRecord record) {
System.out.println(record.value());
}
}实现功能:
@Autowired
private KafkaProducer kafkaProducer;
@Test
public void testKafka() {
kafkaProducer.sendMessage("test", "你好");
kafkaProducer.sendMessage("test", "在吗");
try {
Thread.sleep(1000 * 10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/2160.html

