
我们在server02服务器上部署nginx服务器,然后安装filebeat,使用filebeat收集nginx日志文件,把收集到的日志发送给logstash,让logstash过滤日志,把过滤完的日志保存到elasticsearch,然后通过kibana展示出来
1、安装nginx
详细安装步骤请看Nginx + Tomcat 构筑Web服务器集群的负载均衡
2、安装filebeat
解压软件包
[root@server02 ~]# tar -zxvf filebeat-7.3.0-linux-x86_64.tar.gz -C /usr/local/
[root@server02 ~]# mv /usr/local/filebeat-7.3.0-linux-x86_64 /usr/local/filebeat修改配置文件
filebeat.yml配置主要有两个部分,一个是日志收集,一个是日志输出的配置
[root@server02 ~]# vim /usr/local/filebeat/filebeat.yml
– type: log # type: log 读取日志文件的每一行(默认)
enabled: true #enabled: true 该配置是否生效,如果改为false,将不收集该配置的日志
paths: # paths: 要抓取日志的全路径
– /usr/local/nginx/logs/*.log #添加收集httpd服务日志
#- /var/log/* #将该行注释掉
#————————– Elasticsearch output ——————————
#output.elasticsearch: # Elasticsearch这部分全部注释掉
# Array of hosts to connect to.
#hosts: [“localhost:9200”]
#—————————– Logstash output ——————————–
output.logstash: #取消注释,把日志放到logstash中
# The Logstash hosts
hosts: [“192.168.121.10:5044”] #取消注释,输出到Logstash的地址和端口
#logging.level: warning #调整日志级别
启动服务
[root@server02 filebeat]# cd /usr/local/filebeat/
[root@server02 filebeat]# ./filebeat &
[root@server02 filebeat]# ./filebeat -e -c filebeat.yml &
-e: 记录到stderr(标准输出(设备)文件,对应终端的屏幕),并禁用syslog 文件输出
-c: 指定用于Filebeat的配置文件, 如果未指定-c标志,则使用默认配置文件filebeat.yml
查看进程
[root@server02 filebeat]# ps -ef | grep filebeat![]()
![]()
设置开机自启动
echo "cd /usr/local/filebeat/ && ./filebeat -e -c filebeat.yml & " >> /etc/rc.localchmod +x /etc/rc.local3、logstash配置
配置logstash文件
[root@server01 ~]# vim /usr/local/logstash-7.3.0/config/http_logstash.confinput{
beats { #从Elastic beats接收事件
codec => plain{charset => “UTF-8”} #设置编解码器为utf8
port => “5044” #要监听的端口
}
}
output {
stdout { #标准输出,把收集的日志在当前终端显示,方便测试服务连通性
codec => “rubydebug” #编解码器为rubydebug
}
elasticsearch { #把收集的日志发送给elasticsearch
hosts => [ “192.168.121.10:9200” ] # elasticsearch的服务器地址
index => “nginx-logs-%{+YYYY.MM.dd}” #创建索引
}
}
启动logstash
[root@server01 ~]# logstash -f /usr/local/logstash-7.3.0/config/http_logstash.conf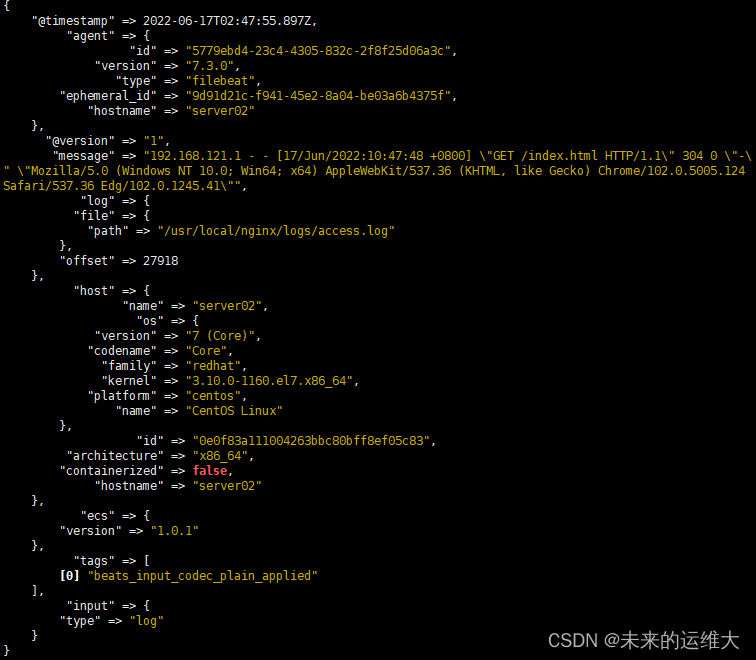
这里可以看到file beat发送过来的消息,如果没有新消息,可以去刷新nginx网页
如果报错:

杀死上一个logstash进程,因为我们之前已经启用了一个logstash,所以杀死之前的进程,再启动logstash。或者使用选项–path.data=/dir为要启动的logstash实例指定一个路径。
开机自启动
[root@server01 ~]# echo "nohup logstash -f /usr/local/logstash-7.3.0/config/http_logstash.conf &" >> /etc/rc.localkibana配置
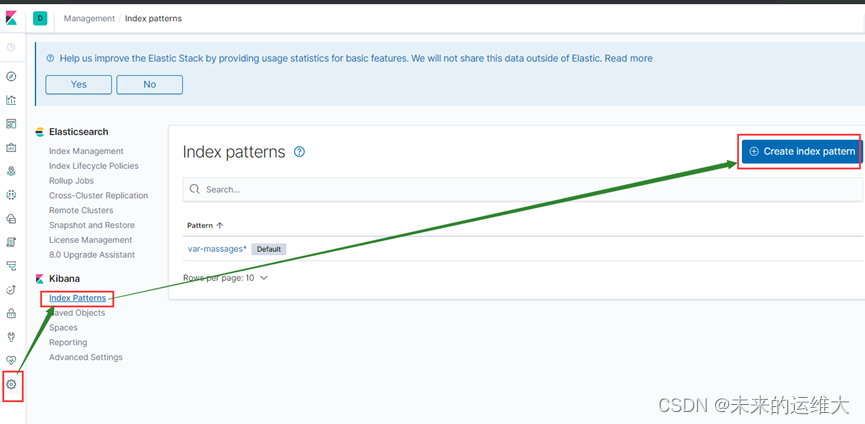
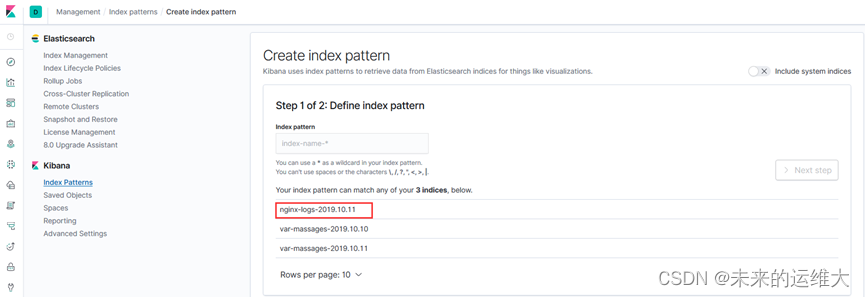
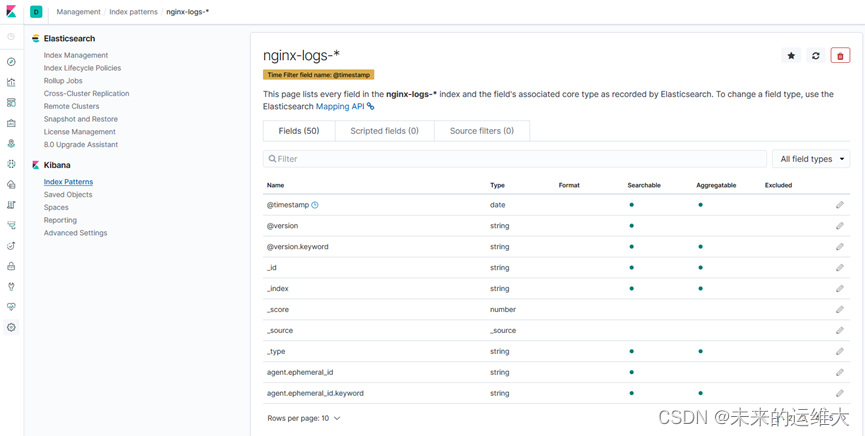
创建索引
在浏览器输入121.168.121.10:5601
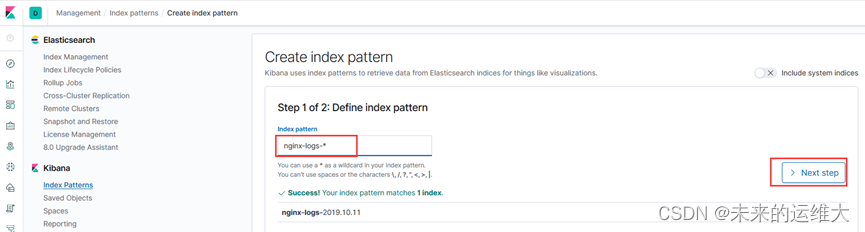
添加时间过滤器
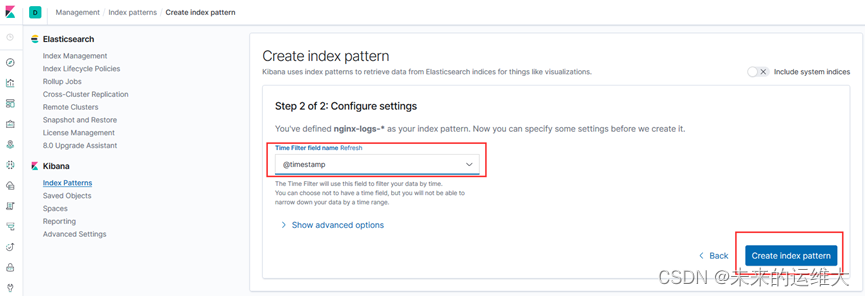
查看日志
打开新建的索引去查看收集到的日志,可以通过刚才添加的时间过滤器查看你想要的看到的日志。
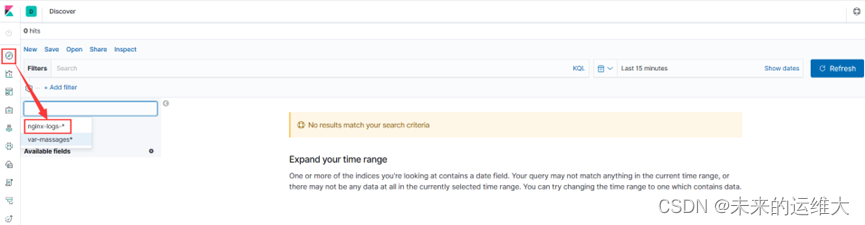
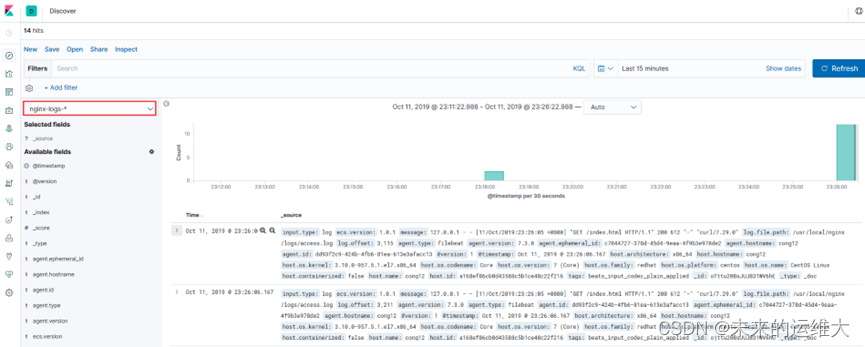
添加过滤器
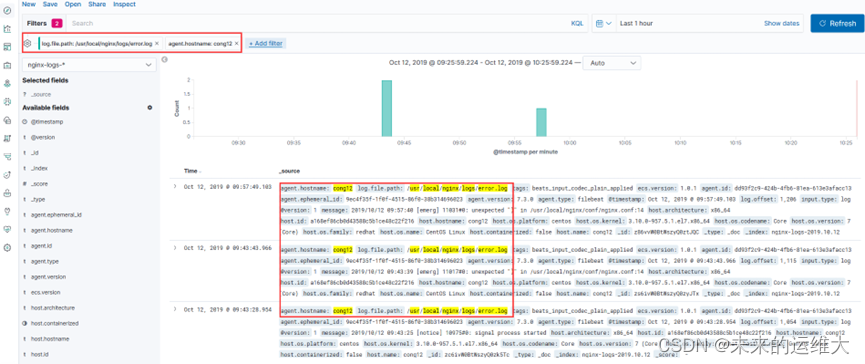
我们可以在搜到的日志添加过滤器,过滤出我们想要的内容,比如,我想看下nginx的错误日志,那么添加一个log.file.path为/usr/local/nginx/logs/error.log的过滤器,如果我们监控的服务器比较多,我可以查看特定的主机的nginx错误日志
1、添加类型为log.file.path的过滤器
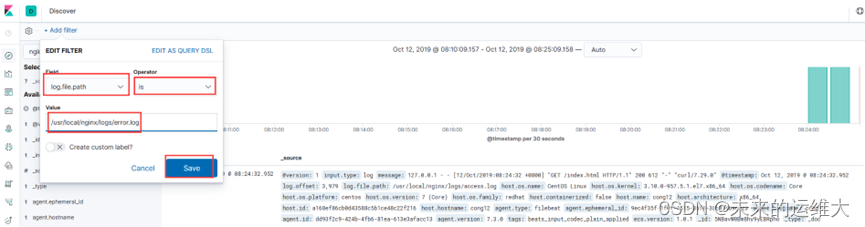
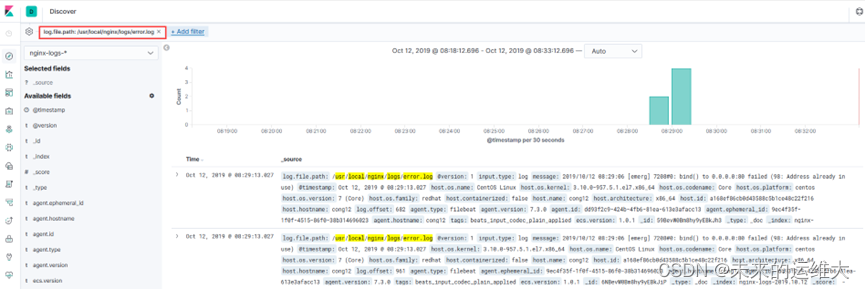
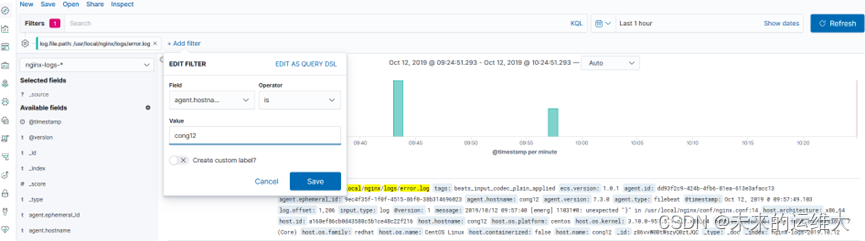
2、过滤出cong12这台主机的nginx错误日志
过滤主机的字段名称叫agent.hostname,添加agent.hostname为cong12的过滤器,所有的过滤器字段在显示的日志上面可以看到
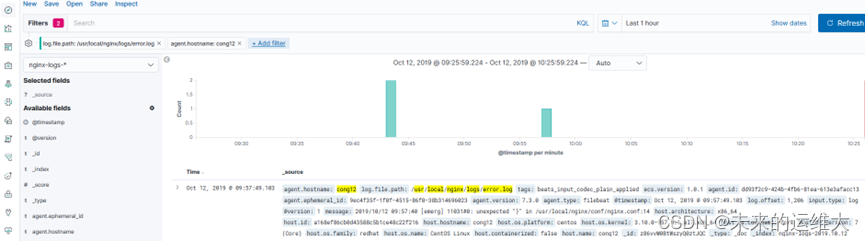
到这里ELK+filebeat部署完成
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/22230.html

