
环境配置
软件版本
这里使用较新的7.3.0版本,ELK所有的组件最好选择相同的版本
时间同步
[root@cong11 ~]# ntpdate ntp1.aliyun.com![]()
![]()
ELK部署
上传软件包


安装jdk
由于ELK 的3个软件都需要JDK支持,所以只要安装Elasticsearch + Logstash + Kibana的服务器都要装JDK,jdk版本至少1.8
解压jdk软件包
[root@localhost ~]# tar -zxvf jdk-8u171-linux-x64.tar.gz -C /usr/local/
配置jdk环境变量
[root@localhost ~]# vim /etc/profile
JAVA_HOME=/usr/local/jdk1.8.0_171
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar
export PATH JAVA_HOME CLASSPATH
[root@localhost ~]# source /etc/profile
查看java环境
[root@localhost ~]# java -version
安装elasticsearch
我们这里开始安装Elasticsearch,这里做实验配置用的是Elasticsearch单节点部署,生产环境中应该部署Elasticsearch集群,保证高可用。
解压软件包
[root@localhost ~]# tar -zxvf elasticsearch-7.3.0-linux-x86_64.tar.gz -C /usr/local/
创建用户
源码包安装Elasticsearch不能用root启动,需要新建一个用户来启动ElasticSearch,这里创建普通用户elk
[root@localhost ~]# useradd elk
给文件授权
[root@localhost ~]# chown -R elk:elk /usr/local/elasticsearch-7.3.0/
设置内核参数
修改系统参数,确保系统有足够资源启动ES
[root@localhost ~]# vim /etc/sysctl.confvm.max_map_count=655360
执行sysctl -p,确保生效配置生效
![]()
![]()
注:
vm.max_map_count这个参数就是允许一个进程在VMA(Virtual Memory Areas,虚拟内存区域)拥有最大数量,虚拟内存区域是一个连续的虚拟地址空间区域。在进程的生命周期中,每当程序尝试在内存中映射文件,链接到共享内存段,或者分配堆空间的时候,这些区域将被创建。调优这个值将限制进程可拥有VMA的数量,当达到vm.max_map_count了就是返回out of memory errors。
这个数据通过下面的命令可以查看: cat /proc/sys/vm/max_map_count
可以通过命令cat /proc/{pids}/maps |wc -l来监控,当前进程使用到的vm映射数量
设置资源参数
vim /etc/security/limits.conf# 表示任何一个用户可以打开的最大的文件数量
* soft nofile 65536
* hard nofile 65536
# 表示任何一个用户可以打开的最大的进程数
* soft nproc 65536
* hard nproc 65536
切换到elk用户
使用普通用户去启动elasticsearch,这是软件强制规定的
su - elkcd /usr/local/elasticsearch-7.3.0/ vim config/elasticsearch.yml#如果是集群修改如下配置,集群是通过cluster.name自动在9300端口上寻找节点信息的。
cluster.name: my-application #集群名称,同一个集群的标识
node.name: node-1 #节点名称path.data: /data/elk/data #数据存储位置
path.logs: /data/elk/logs #日志文件的路径
#如果系统为centos6.x操作系统,不支持SecComp,而elasticsearch默认bootstrap.system_call_filter为true进行检测,所以导致检测失败,失败后直接导致ES不能启动。
# 解决办法:在elasticsearch.yml中添加配置项:bootstrap.system_call_filter为false
bootstrap.memory_lock: false
bootstrap.system_call_filter: falsenetwork.host: 0.0.0.0 # ES的监听地址,这样别的机器也可以访问
http.port: 9200 #监听端口,ES节点和外部通讯使用,默认的端口号是9200。
cluster.initial_master_nodes: [“node-1”] #设置一系列符合主节点条件的节点的主机名或IP地址来引导启动集群。
创建数据和日志目录
exit mkdir -pv /data/elk/{data,logs}
chown -R elk:elk /data/elk/
su - elk
cd /usr/local/elasticsearch-7.3.0/
vim config/jvm.options
启动Elasticsearch
[elk@cong11 elasticsearch-7.3.0]$ ./bin/elasticsearch
elasticsearch测试
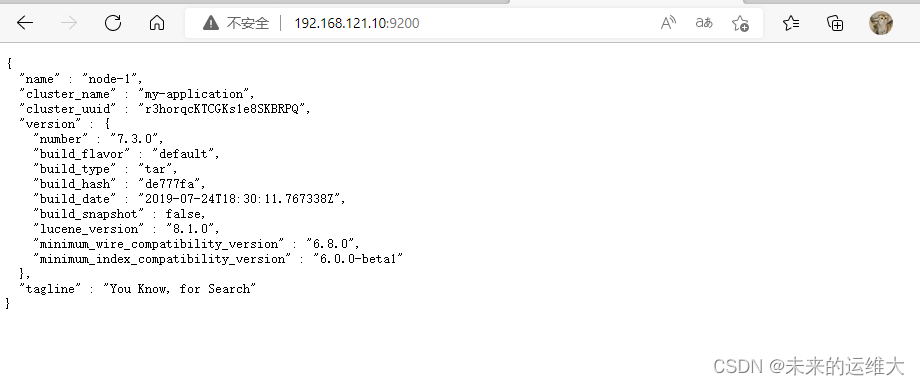
加入开机自启动
[elk@cong11 elasticsearch-7.3.0]$ su - root [root@cong11 ~]# vim /etc/init.d/elasticsearch#!/bin/sh
#chkconfig: 2345 80 05
#description: elasticsearchexport JAVA_BIN=/usr/local/jdk1.8.0_171/bin
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME JAVA_BIN PATH CLASSPATH
case “$1” in
start)
su elk<<!
cd /usr/local/elasticsearch-7.3.0/
./bin/elasticsearch -d
!
echo “elasticsearch startup”
;;
stop)
es_pid=`jps | grep Elasticsearch | awk ‘{print $1}’`
kill -9 $es_pid
echo “elasticsearch stopped”
;;
restart)
es_pid=`jps | grep Elasticsearch | awk ‘{print $1}’`
kill -9 $es_pid
echo “elasticsearch stopped”
su elk<<!
cd /usr/local/elasticsearch-7.3.0/
./bin/elasticsearch -d
!
echo “elasticsearch startup”
;;
*)
echo “start|stop|restart”
;;
esacexit $?
注意:
以上脚本的用户为elk,如果你的用户不是,则需要替换
以上脚本的JAVA_BIN以及elasticsearch_home如果不同请替换
[root@cong11 ~]# chmod +x /etc/init.d/elasticsearch #给脚本添加权限
[root@cong11 ~]# chkconfig --add /etc/init.d/elasticsearch #添加开机自启动
测试脚本
[root@cong11 ~]# systemctl restart elasticsearch
[root@cong11 ~]# ps -aux | grep elasticsearch

安装logstash
解压安装包
[root@cong11 ~]# tar -zxvf logstash-7.3.0.tar.gz -C /usr/local/Logstash管道有两个必需的元素,input和output,以及一个可选的元素,filter。输入插件从数据源那里消费数据,过滤器插件根据你的期望修改数据,输出插件将数据写入目的地。
首先,我们通过运行最基本的Logstash管道来测试您的Logstash安装
/usr/local/logstash-7.3.0/bin/logstash -e 'input {stdin{}} output {stdout{}}'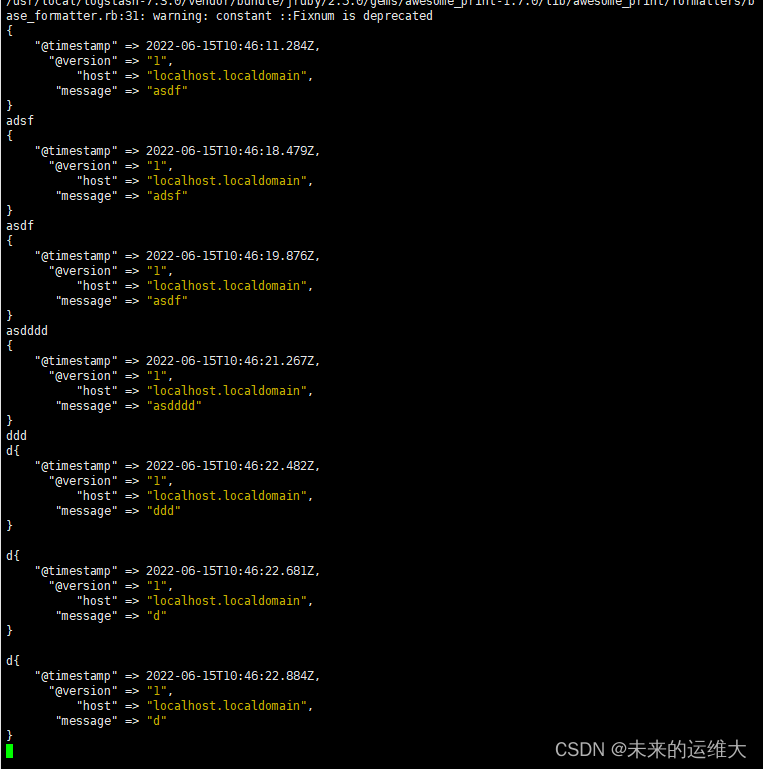
注:stdin 标准输入,stdout标准输出。
我们可以看到,我们输入什么内容,logstash按照某种格式输出,其中-e参数允许Logstash直接通过命令行接受设置。这点尤其快速的帮助我们反复的测试配置是否正确而不用写配置文件。使用CTRL-C命令可以退出之前运行的Logstash。
生成配置文件
使用-e参数在命令行中指定配置是很常用的方式,不过如果需要配置更多设置则需要很长的内容。这种情况,我们首先创建一个简单的配置文件,并且指定logstash使用这个配置文件。例如:在logstash安装目录下创建配置文件logstash.conf,文件内容如下:
[root@cong11 ~]# vim /usr/local/logstash-7.3.0/config/logstash.confinput { #input plugin让logstash可以读取特定的事件源。
file { #file 从文件读取数据
path => “/var/log/messages” #收集来源,这里从输入的文件路径收集系统日志。可以用/var/log/*.log,/var/log/**/*.log,如果是/var/log则是/var/log/*.log。
type => “messages_log” #通用选项. 用于激活过滤器。
start_position => “end” #start_position 选择logstash开始读取文件的位置,begining或者end。默认是end,end从文件的末尾开始读取,也就是说,仅仅读取新添加的内容。对于一些更新的日志类型的监听,通常直接使用end就可以了;相反,beginning就会从一个文件的头开始读取。但是如果记录过文件的读取信息,这个配置也就失去作用了。
}
}
filter { #过滤器插件,对事件执行中间处理、过滤,为空不过滤。
}
output { #输出插件,将事件发送到特定目标。
elasticsearch { #将事件发送到es,在es中存储日志
hosts => [“192.168.1.11:9200”]
index => “var-massages-%{+yyyy.MM.dd}” #index表示事件写入的索引。可以按照日志来创建索引,以便于删旧数据和按时间来搜索日志
}
stdout { codec => rubydebug } # stdout标准输出,输出到当前终端显示屏
}
[root@cong11 ~]# cat /usr/local/logstash-7.3.0/config/logstash.conf input {
file {
path => “/var/log/messages”
type => “messages_log”
start_position => “beginning”
}
}
filter {
}
output {
elasticsearch {
hosts => [“192.168.1.11:9200”]
index => “var-massages-%{+yyyy.MM.dd}”
}
stdout { codec => rubydebug }
}
注:上述文件复制时必须去除多余空格,保持yml文件规范。这个配置文件只是简单测试logstash收集日志功能
做软连接
[root@cong11 ~]# ln -s /usr/local/logstash-7.3.0/bin/* /usr/local/bin/启动logstash
[root@cong11 ~]# logstash -f /usr/local/logstash-7.3.0/config/logstash.conf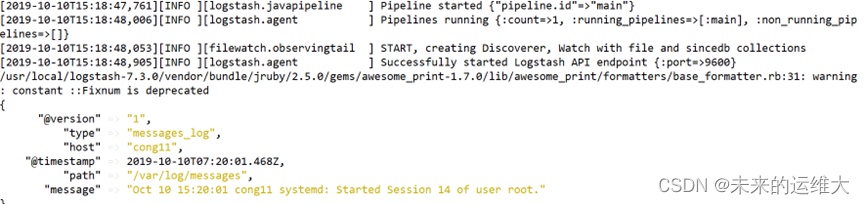
使用echo命令模拟写入日志,另外打开一个终端,执行下面的命令
[root@cong11 ~]# echo "$(date) hello world" >> /var/log/messages命令执行后看到如下图的信息:
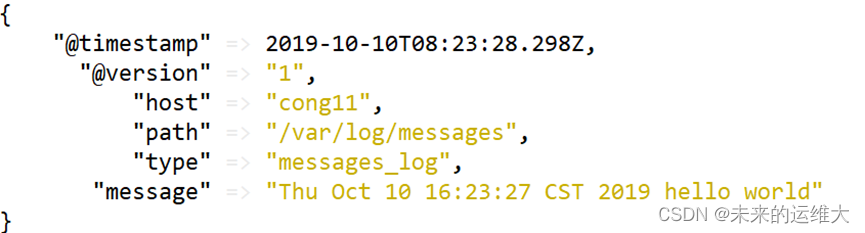
我们可以使用curl命令发送请求来查看ES是否接收到了数据:
[root@cong11 ~]# curl http://192.168.1.11:9200/_search?pretty后台启动
[root@cong11 ~]# nohup logstash -f /usr/local/logstash-7.3.0/config/logstash.conf &开机自启动
[root@cong11 ~]# echo "source /etc/profile" >> /etc/rc.local #让开机加载java环境
[root@cong11 ~]# echo "nohup logstash -f /usr/local/logstash-7.3.0/config/logstash.conf &" >> /etc/rc.local
[root@cong11 ~]# chmod +x /etc/rc.local
安装Kibana
[root@cong11 ~]# tar -zxvf kibana-7.3.0-linux-x86_64.tar.gz -C /usr/local/修改配置文件
[root@cong11 ~]# vim /usr/local/kibana-7.3.0-linux-x86_64/config/kibana.yml#开启以下选项并修改
server.port: 5601
server.host: “192.168.121.10”
elasticsearch.hosts: [“http://192.168.121.10:9200”] #修改elasticsearch地址,多个服务器请用逗号隔开。
注意: host:与IP地址中间有个空格不能删除,否则报错。
启动服务
[root@cong11 ~]# /usr/local/kibana-7.3.0-linux-x86_64/bin/kibana [root@cong11 ~]# /usr/local/kibana-7.3.0-linux-x86_64/bin/kibana --allow-root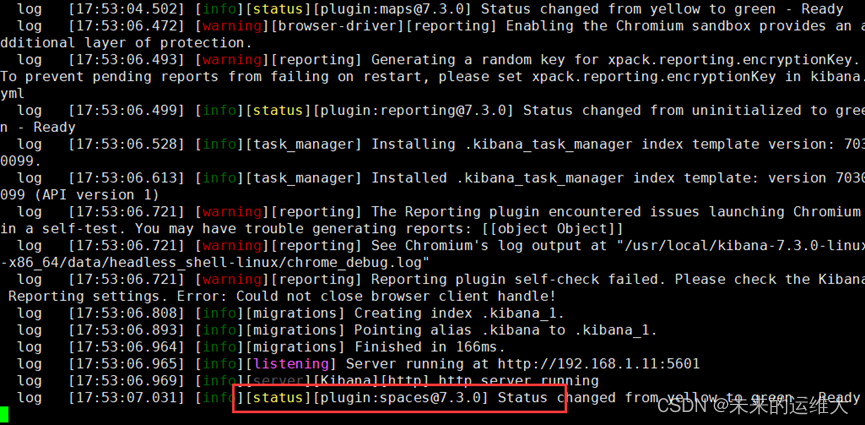
kibana 设置后台启动,使用nohup 配合
[root@cong11 ~]# nohup /usr/local/kibana-7.3.0-linux-x86_64/bin/kibana --allow-root &
[root@cong11 ~]# netstat -anptl | grep :5601
添加开机自启动
[root@cong11 ~]# echo "nohup /usr/local/kibana-7.3.0-linux-x86_64/bin/kibana --allow-root &" >> /etc/rc.local测试
登录后,首先,配置一个索引,打开发现,可以在仪表盘上看到我们在建logstash上创建的索引,添加索引,创建就可以。
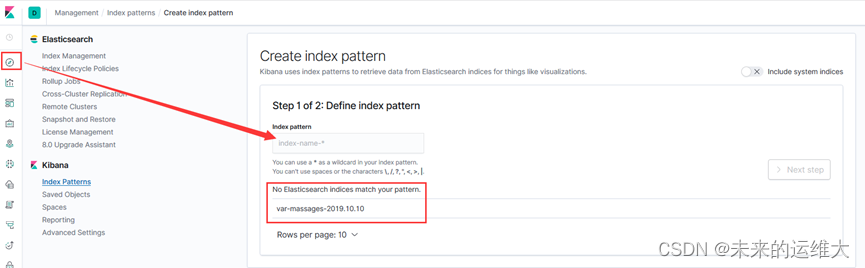
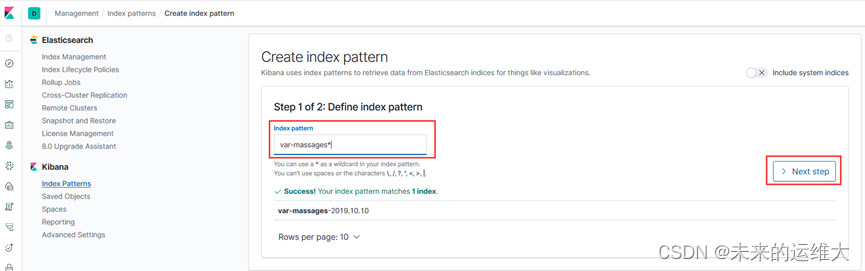
选择时间过滤器
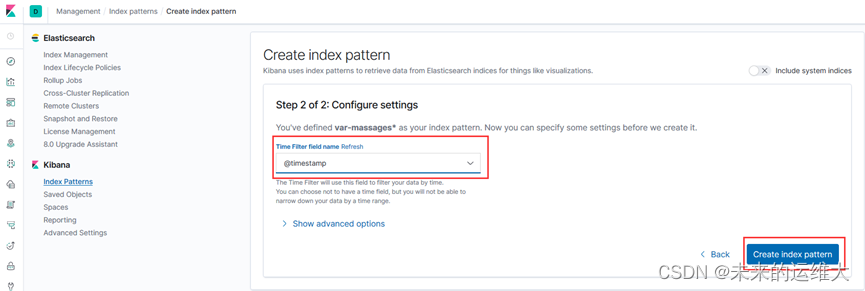
索引参数配置
看到如下界面说明索引创建完成。使用默认就可以
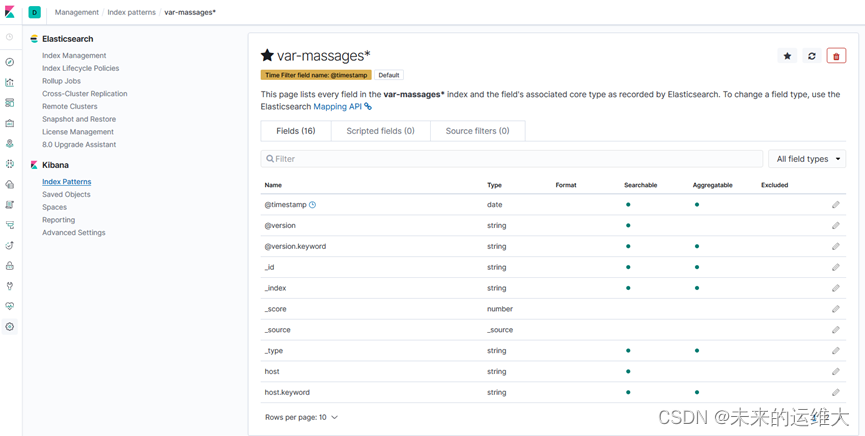
查看收集上来的日志
点击“Discover”,可以搜索和浏览Elasticsearch中的数据

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/22231.html

