
堆排序
1. 基本介绍
(1)堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为 O(nlogn),它也是不稳定排序。
稳定和不稳定排序的定义:
假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些
记录的相对次序保持不变,即在原序列中,r[i]=r[j],且 r[i]在 r[j]之前,而在排序后的序列中,r[i]仍在 r[j]之前, 则称这种排序算法是稳定的;否则称为不稳定的。
(2) 堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆。
满二叉树定义:高度为h,由2^h-1个节点构成的二叉树称为满二叉树。特点是所有叶子节点都在树的最后一层。如下图为满二叉树

完全二叉树定义:完全二叉树是由满二叉树而引出来的,若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数(即1~h-1层为一个满二叉树),第 h 层所有的结点都连续集中在最左边,这就是完全二叉树。
特点:除了最后一层不满外,所有层的节点都是满的。最后一层的叶子节点在左边连续,倒数第二层的叶子节点在右边连续。如下图为完全二叉树
如下图则为不完全二叉树:
大顶堆示例图:
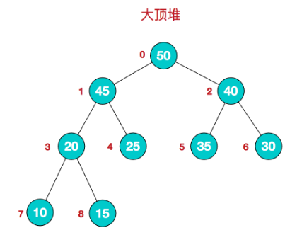
我们对堆中的结点按层进行编号,映射到数组中就是下面这个样子:

数组满足的不等式:arr[i] >= arr[2i+1] && arr[i] >= arr[2i+2] 。不等式中 i 对应第几个节点,i从0开始编号。
注意 : 堆的定义没有要求结点的左孩子的值和右孩子的值的大小关系。
(3)每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。小顶堆示例图:
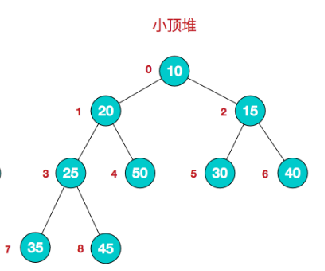
我们对堆中的结点按层进行编号,映射到数组中就是下面这个样子:

数组满足的不等式: arr[i] <= arr[2i+1] && arr[i] <= arr[2i+2]。不等式中 i 对应第几个节点,i从0开始编号。
2. 基本思想
堆排序的基本思想是:
将待排序序列构造成一个大顶堆,此时,整个序列的最大值就是堆顶的根节点。
将其与末尾元素进行交换,此时末尾就为最大值。
然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列了。
3. 排序步骤示例
以一个无序的数组为例:[4,6,8,5,9]
3.1 步骤一:构造初始堆
将给定的无序序列构造成一个大顶堆(一般升序采用大顶堆,降序采用小顶堆)。
(1) 给定的无序序列结构如下;
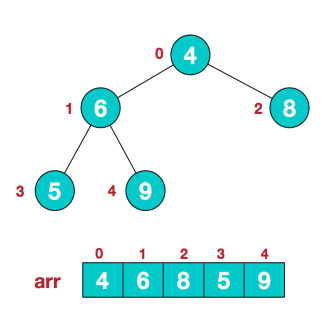
(2) 此时我们从最后一个非叶子结点开始(叶结点自然不用调整,第一个非叶子结点 arr.length/2-1=5/2-1=1,也就是下面的6结点),从左至右,从下至上进行调整。
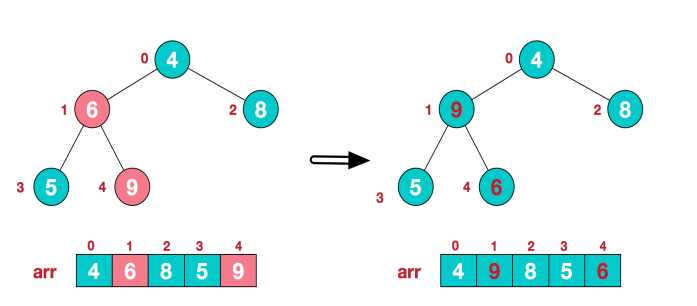
(3) 找到第二个非叶节点4,由于[4,9,8]中9元素最大,4和9交换。
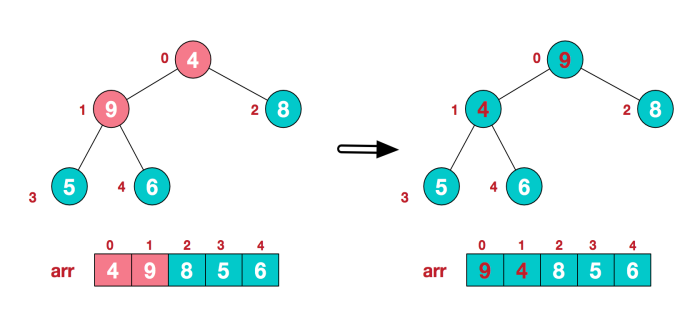
(4) 上一步的操作,使得节点下标为1的子树结构混乱,不符合大顶堆的定义。继续进行调整。
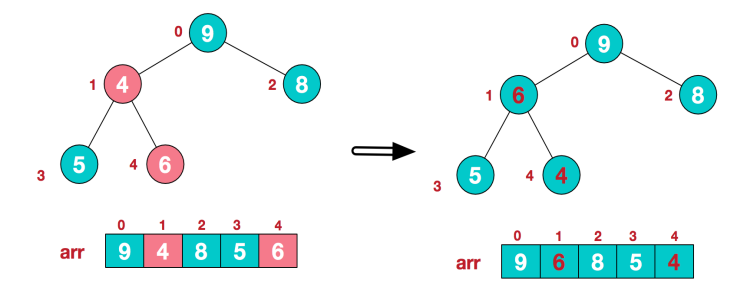
此时得到的就是一个大顶堆结构。
3.2 步骤二:交换和调整元素
将堆顶元素与末尾元素进行交换,使末尾元素最大。然后继续调整堆,再将堆顶元素与末尾元素交换,得到第二大元素。如此反复进行交换、重建、交换。
(1).将堆顶元素9和末尾元素4进行交换
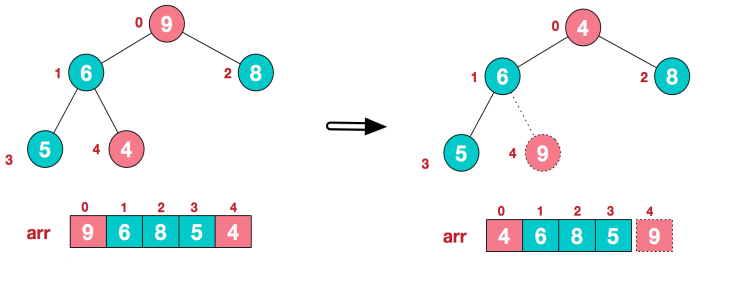
(2)重新调整结构,使其重新满足大顶堆的定义
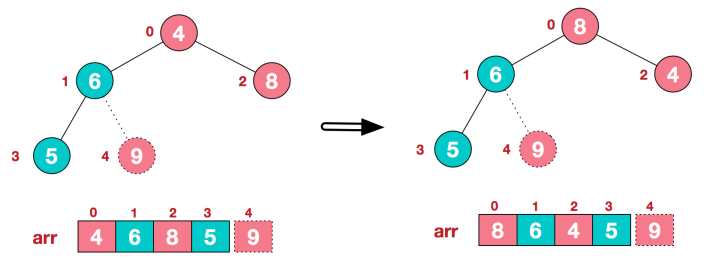
(3) 再将堆顶元素8与末尾元素5进行交换,得到第二大元素8。
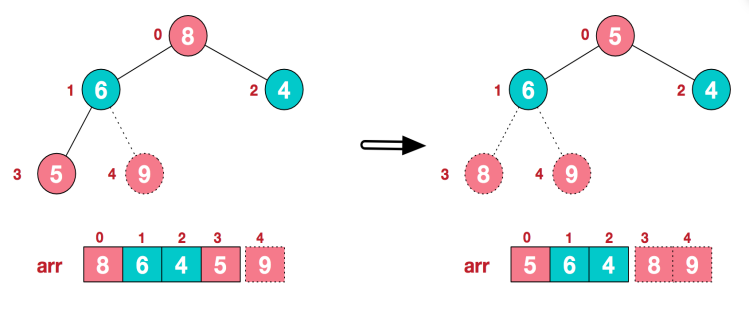
(4)后续过程,继续进行调整,交换,如此反复进行,最终使得整个序列有序。
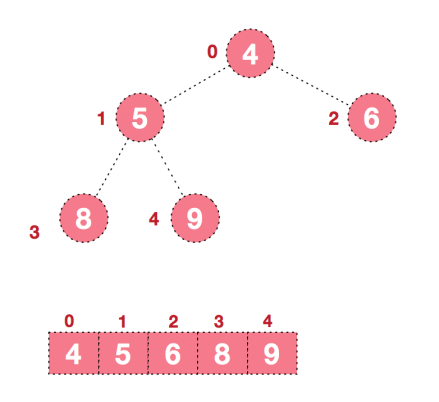
可以看到在构建大顶堆和交换、调整元素的过程中,元素的个数逐渐减少,最后就得到一个有序序列了.。
总结
堆排序的基本步骤如下:
1).将无序序列构建成一个堆,根据升序降序需求选择大顶堆或小顶堆;
2).将堆顶元素与末尾元素交换,将最大元素”沉”到数组末端;
3).重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤,直到整个序列有序。
4. 算法实现
public void heapSort(int[] arr){
int temp;
//步骤1:初始化,将无序序列构建成一个堆,根据升序降序需求选择大顶堆或小顶堆
//这里的i取值为当前树最底层的非叶子节点的索引
for (int i = arr.length/2-1; i >=0; i--) {
adjustHeap(arr,i,arr.length);
}
//步骤2:将堆顶元素与末尾元素进行交换,使末尾元素最大。然后继续调整堆,再将堆顶元素与末尾元素交换,得到第二大元素。如此反复进行交换、重建、交换。
for (int i = arr.length-1; i >0 ; i--) {
//将堆顶元素与末尾元素交换,将最大的元素放到数组末端
temp=arr[i];
arr[i]=arr[0];
arr[0]=temp;
adjustHeap(arr,0,i);
}
}
/**
* 作用:将以i对应的非叶子节点的树调整成大顶堆
* 举例:
* int arr[] = {4, 6, 8, 5, 9}; => i = 1 => adjustHeap => 得到 {4, 9, 8, 5, 6}
* 如果我们再次调用 adjustHeap 传入的是 i = 0 => 得到 {4, 9, 8, 5, 6} => {9,6,8,5, 4}
*
* @param arr 待调整的数组
* @param i 表示需要调整的非叶子节点在数组的索引
* @param length 表示对多少个元素继续调整,length是逐渐减少的
*/
public static void adjustHeap(int[] arr,int i,int length){
//先取出当前元素的值,保存在临时变量
int temp=arr[i];
//开始调整,k=i*2+1是i结点的左子节点
for (int k = i*2+1; k < length ; k=k*2+1) {
//先找到子节点的最大值,如果左子节点的值小于右子节点的值
if(k+1<length&&arr[k]<arr[k+1]){
//k指向右子节点
k++;
}
//如果子节点大于父节点
if (arr[k]>temp){
//将父节点所在索引的值设置为当前k所在结点的值
arr[i]=arr[k];
//完成了一层的大顶堆构造。i指向k,继续循环,构造大顶堆
i=k;
}
//上述两个条件不满足,则可以结束循环。
// 因为由调用方法heapSort(),决定堆从从左到右,从下到上开始构建,如果当前这一层局部满足了大/小顶堆堆定义,则后续的结点则不需要比较了
else{
break;
}
}
//当for循环结束后,将原本i的值放到调整后的位置
arr[i]=temp;
}```
测试:生成包含80000 个随机数的数组,进行堆排序,统计执行时间
public class HeapSort {
public static void main(String[] args) {
//要求将数组进行升序排序
int[] simpleArr = {4, 6, 8, 5, 9};
heapSort(simpleArr);
System.out.println(Arrays.toString(simpleArr));
// 创建要给 80000 个随机数的数组
int[] arr = new int[8000000];
for (int i = 0; i < 8000000; i++) {
arr[i] = (int) (Math.random() * 8000000);
}
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss:SSS");
String date1Str = simpleDateFormat.format(new Date());
System.out.println("排序前的时间是=" + date1Str);
heapSort(arr);
String date2Str = simpleDateFormat.format(new Date());
System.out.println("排序后的时间是=" + date2Str);
}
}
代码执行结果,控制台输出:
[4, 5, 6, 8, 9]
排序前的时间是=2021-01-28 23:23:27:160
排序后的时间是=2021-01-28 23:23:29:609
5. 总结
堆排序运行的最坏,最好,平均时间复杂度为 O(N*logN),尽管相比快速排序略慢,但它比快速排序优越的一点是它对初始数据的分布不敏感。在关键字按某种排序顺序的情况下,快速排序的时间复杂度可以降到O(n^2)。然而堆排序对任意排列的数据,其排序的时间复杂度都是 O(N*logN)。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/44307.html

