
delete和Vue.delete删除数组的区别?
delete只是被删除的元素变成了empty/undefined其他的元素的键值还是不变。Vue.delete直接删除了数组 改变了数组的键值。
var a=[1,2,3,4]
var b=[1,2,3,4]
delete a[0]
console.log(a) //[empty,2,3,4]
this.$delete(b,0)
console.log(b) //[2,3,4]
Vue路由hash模式和history模式
1. hash模式
早期的前端路由的实现就是基于 location.hash 来实现的。其实现原理很简单,location.hash 的值就是 URL中 # 后面的内容。比如下面这个网站,它的 location.hash 的值为 '#search'
https://interview2.poetries.top#search
hash 路由模式的实现主要是基于下面几个特性
URL中hash值只是客户端的一种状态,也就是说当向服务器端发出请求时,hash部分不会被发送;hash值的改变,都会在浏览器的访问历史中增加一个记录。因此我们能通过浏览器的回退、前进按钮控制hash的切换;- 可以通过
a标签,并设置href属性,当用户点击这个标签后,URL的hash值会发生改变;或者使用JavaScript来对loaction.hash进行赋值,改变URL的hash值; - 我们可以使用
hashchange事件来监听hash值的变化,从而对页面进行跳转(渲染)
window.addEventListener("hashchange", funcRef, false);
每一次改变 hash(window.location.hash),都会在浏览器的访问历史中增加一个记录利用 hash 的以上特点,就可以来实现前端路由“更新视图但不重新请求页面”的功能了
特点 :兼容性好但是不美观
2. history模式
history采用HTML5的新特性;且提供了两个新方法: pushState(), replaceState()可以对浏览器历史记录栈进行修改,以及popState事件的监听到状态变更
window.history.pushState(null, null, path);
window.history.replaceState(null, null, path);
这两个方法有个共同的特点:当调用他们修改浏览器历史记录栈后,虽然当前 URL 改变了,但浏览器不会刷新页面,这就为单页应用前端路由“更新视图但不重新请求页面”提供了基础。
history 路由模式的实现主要基于存在下面几个特性:
pushState和repalceState两个API来操作实现URL的变化 ;- 我们可以使用
popstate事件来监听url的变化,从而对页面进行跳转(渲染); history.pushState()或history.replaceState()不会触发popstate事件,这时我们需要手动触发页面跳转(渲染)。
特点 :虽然美观,但是刷新会出现 404 需要后端进行配置
Vue中修饰符.sync与v-model的区别
sync的作用
.sync修饰符可以实现父子组件之间的双向绑定,并且可以实现子组件同步修改父组件的值,相比较与v-model来说,sync修饰符就简单很多了- 一个组件上可以有多个
.sync修饰符
<!-- 正常父传子 -->
<Son :a="num" :b="num2" />
<!-- 加上sync之后的父传子 -->
<Son :a.sync="num" :b.sync="num2" />
<!-- 它等价于 -->
<Son
:a="num"
:b="num2"
@update:a="val=>num=val"
@update:b="val=>num2=val"
/>
<!-- 相当于多了一个事件监听,事件名是update:a, -->
<!-- 回调函数中,会把接收到的值赋值给属性绑定的数据项中。 -->
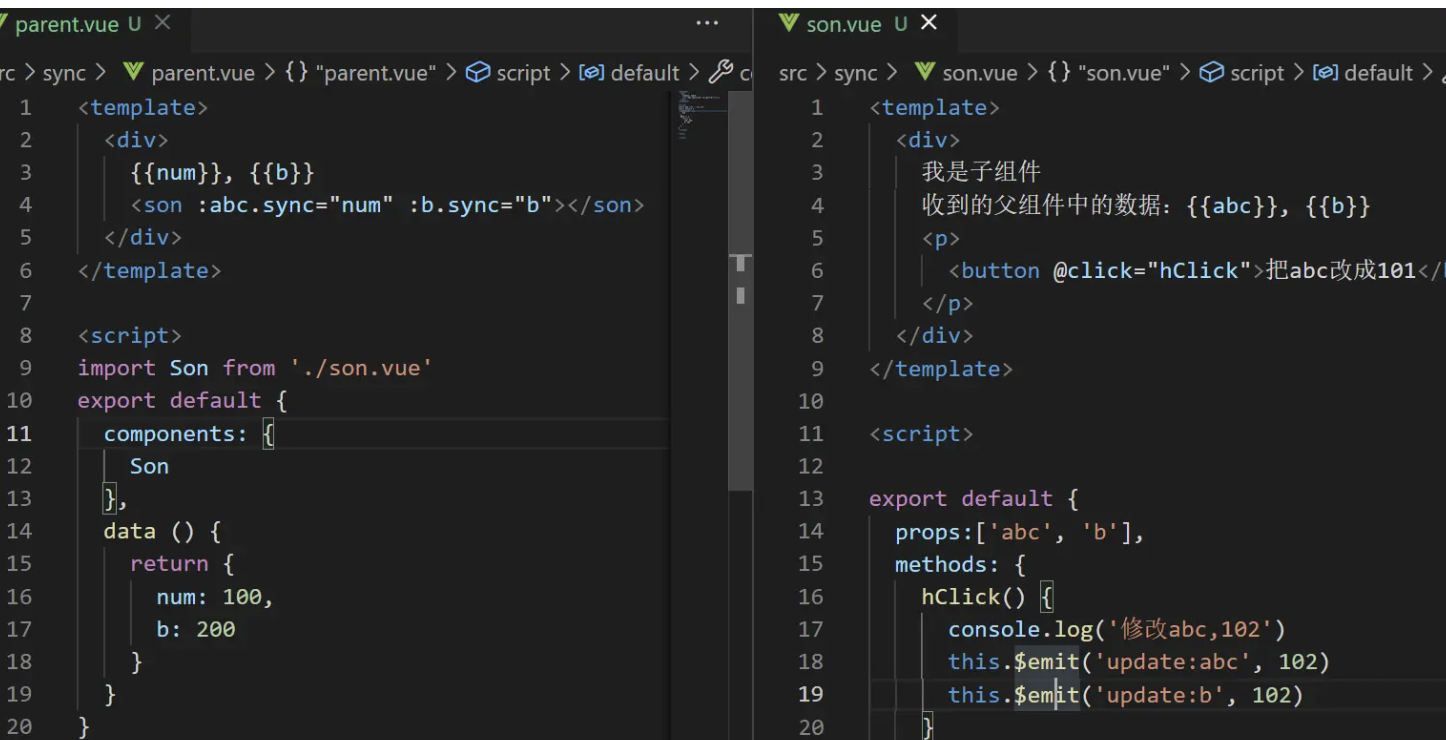

v-model的工作原理
<com1 v-model="num"></com1>
<!-- 等价于 -->
<com1 :value="num" @input="(val)=>num=val"></com1>
- 相同点
- 都是语法糖,都可以实现父子组件中的数据的双向通信
- 区别点
- 格式不同:
v-model="num",:num.sync="num" v-model:@input + value:num.sync:@update:numv-model只能用一次;.sync可以有多个
- 格式不同:
keep-alive 使用场景和原理
keep-alive是Vue内置的一个组件, 可以实现组件缓存 ,当组件切换时不会对当前组件进行卸载。 一般结合路由和动态组件一起使用 ,用于缓存组件- 提供
include和exclude属性, 允许组件有条件的进行缓存 。两者都支持字符串或正则表达式,include表示只有名称匹配的组件会被缓存,exclude表示任何名称匹配的组件都不会被缓存 ,其中exclude的优先级比include高 - 对应两个钩子函数
activated和deactivated,当组件被激活时,触发钩子函数activated,当组件被移除时,触发钩子函数deactivated keep-alive的中还运用了LRU(最近最少使用) 算法,选择最近最久未使用的组件予以淘汰
<keep-alive></keep-alive>包裹动态组件时,会缓存不活动的组件实例,主要用于保留组件状态或避免重新渲染- 比如有一个列表和一个详情,那么用户就会经常执行打开详情=>返回列表=>打开详情…这样的话列表和详情都是一个频率很高的页面,那么就可以对列表组件使用
<keep-alive></keep-alive>进行缓存,这样用户每次返回列表的时候,都能从缓存中快速渲染,而不是重新渲染
关于keep-alive的基本用法
<keep-alive>
<component :is="view"></component>
</keep-alive>
使用includes和exclude:
<keep-alive include="a,b">
<component :is="view"></component>
</keep-alive>
<!-- 正则表达式 (使用 `v-bind`) -->
<keep-alive :include="/a|b/">
<component :is="view"></component>
</keep-alive>
<!-- 数组 (使用 `v-bind`) -->
<keep-alive :include="['a', 'b']">
<component :is="view"></component>
</keep-alive>
匹配首先检查组件自身的 name 选项,如果 name 选项不可用,则匹配它的局部注册名称 (父组件 components 选项的键值),匿名组件不能被匹配
设置了 keep-alive 缓存的组件,会多出两个生命周期钩子(activated与deactivated):
- 首次进入组件时:
beforeRouteEnter>beforeCreate>created>mounted>activated> … … >beforeRouteLeave>deactivated - 再次进入组件时:
beforeRouteEnter>activated> … … >beforeRouteLeave>deactivated
使用场景
使用原则:当我们在某些场景下不需要让页面重新加载时我们可以使用keepalive
举个栗子:
当我们从首页–>列表页–>商详页–>再返回,这时候列表页应该是需要keep-alive
从首页–>列表页–>商详页–>返回到列表页(需要缓存)–>返回到首页(需要缓存)–>再次进入列表页(不需要缓存),这时候可以按需来控制页面的keep-alive
在路由中设置keepAlive属性判断是否需要缓存
{
path: 'list',
name: 'itemList', // 列表页
component (resolve) {
require(['@/pages/item/list'], resolve)
},
meta: {
keepAlive: true,
title: '列表页'
}
}
使用<keep-alive>
<div id="app" class='wrapper'>
<keep-alive>
<!-- 需要缓存的视图组件 -->
<router-view v-if="$route.meta.keepAlive"></router-view>
</keep-alive>
<!-- 不需要缓存的视图组件 -->
<router-view v-if="!$route.meta.keepAlive"></router-view>
</div>
思考题:缓存后如何获取数据
解决方案可以有以下两种:
beforeRouteEnter:每次组件渲染的时候,都会执行beforeRouteEnter
beforeRouteEnter(to, from, next){
next(vm=>{
console.log(vm)
// 每次进入路由执行
vm.getData() // 获取数据
})
},
actived:在keep-alive缓存的组件被激活的时候,都会执行actived钩子
// 注意:服务器端渲染期间avtived不被调用
activated(){
this.getData() // 获取数据
},
扩展补充:LRU 算法是什么?
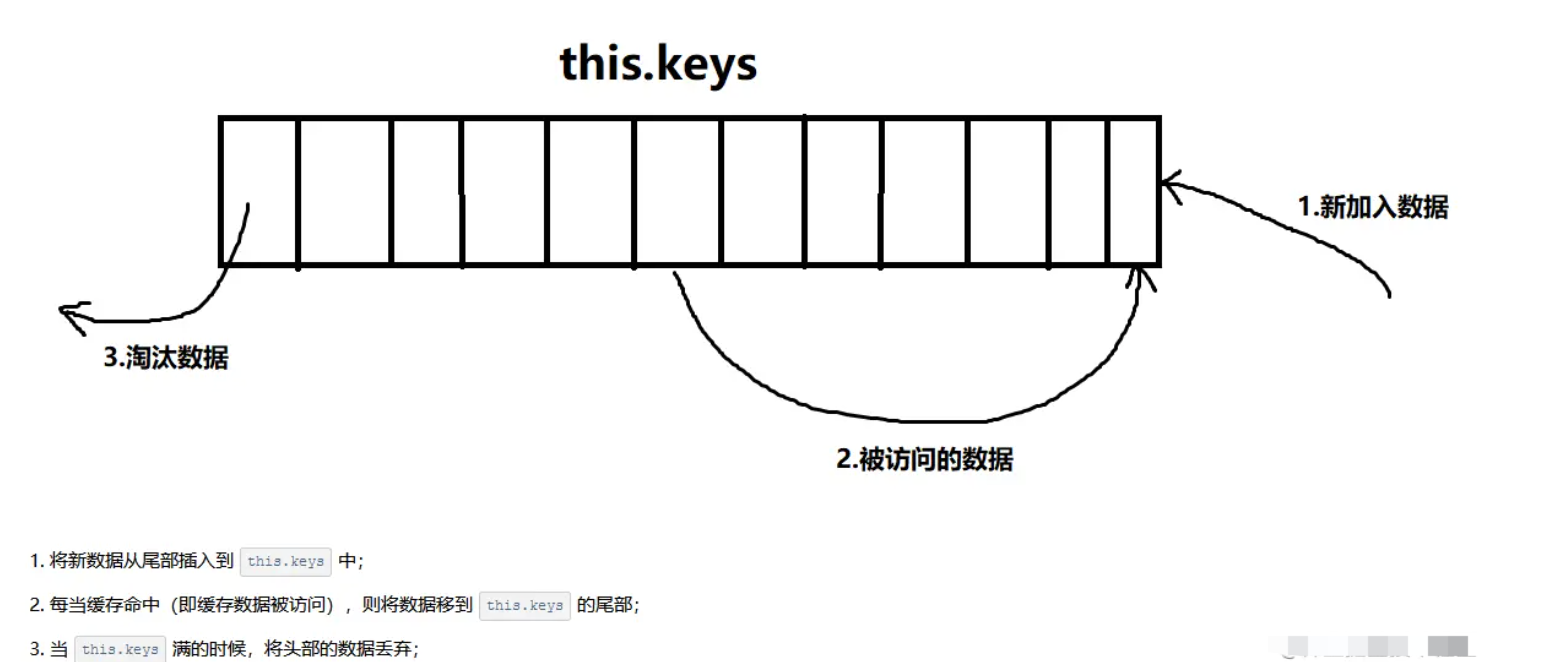
LRU的核心思想是如果数据最近被访问过,那么将来被访问的几率也更高,所以我们将命中缓存的组件key重新插入到this.keys的尾部,这样一来,this.keys中越往头部的数据即将来被访问几率越低,所以当缓存数量达到最大值时,我们就删除将来被访问几率最低的数据,即this.keys中第一个缓存的组件
相关代码
keep-alive是vue中内置的一个组件
源码位置:src/core/components/keep-alive.js
export default {
name: "keep-alive",
abstract: true, //抽象组件
props: {
include: patternTypes, //要缓存的组件
exclude: patternTypes, //要排除的组件
max: [String, Number], //最大缓存数
},
created() {
this.cache = Object.create(null); //缓存对象 {a:vNode,b:vNode}
this.keys = []; //缓存组件的key集合 [a,b]
},
destroyed() {
for (const key in this.cache) {
pruneCacheEntry(this.cache, key, this.keys);
}
},
mounted() {
//动态监听include exclude
this.$watch("include", (val) => {
pruneCache(this, (name) => matches(val, name));
});
this.$watch("exclude", (val) => {
pruneCache(this, (name) => !matches(val, name));
});
},
render() {
const slot = this.$slots.default; //获取包裹的插槽默认值 获取默认插槽中的第一个组件节点
const vnode: VNode = getFirstComponentChild(slot); //获取第一个子组件
// 获取该组件节点的componentOptions
const componentOptions: ?VNodeComponentOptions =
vnode && vnode.componentOptions;
if (componentOptions) {
// 获取该组件节点的名称,优先获取组件的name字段,如果name不存在则获取组件的tag
const name: ?string = getComponentName(componentOptions);
const { include, exclude } = this;
// 不走缓存 如果name不在inlcude中或者存在于exlude中则表示不缓存,直接返回vnode
if (
// not included 不包含
(include && (!name || !matches(include, name))) ||
// excluded 排除里面
(exclude && name && matches(exclude, name))
) {
//返回虚拟节点
return vnode;
}
const { cache, keys } = this;
// 获取组件的key值
const key: ?string =
vnode.key == null
? // same constructor may get registered as different local components
// so cid alone is not enough (#3269)
componentOptions.Ctor.cid +
(componentOptions.tag ? `::${componentOptions.tag}` : "")
: vnode.key;
// 拿到key值后去this.cache对象中去寻找是否有该值,如果有则表示该组件有缓存,即命中缓存
if (cache[key]) {
//通过key 找到缓存 获取实例
vnode.componentInstance = cache[key].componentInstance;
// make current key freshest
remove(keys, key); //通过LRU算法把数组里面的key删掉
keys.push(key); //把它放在数组末尾
} else {
cache[key] = vnode; //没找到就换存下来
keys.push(key); //把它放在数组末尾
// prune oldest entry //如果超过最大值就把数组第0项删掉
if (this.max && keys.length > parseInt(this.max)) {
pruneCacheEntry(cache, keys[0], keys, this._vnode);
}
}
vnode.data.keepAlive = true; //标记虚拟节点已经被缓存
}
// 返回虚拟节点
return vnode || (slot && slot[0]);
},
};
可以看到该组件没有template,而是用了render,在组件渲染的时候会自动执行render函数
this.cache是一个对象,用来存储需要缓存的组件,它将以如下形式存储:
this.cache = {
'key1':'组件1',
'key2':'组件2',
// ...
}
在组件销毁的时候执行pruneCacheEntry函数
function pruneCacheEntry (
cache: VNodeCache,
key: string,
keys: Array<string>,
current?: VNode
) {
const cached = cache[key]
/* 判断当前没有处于被渲染状态的组件,将其销毁*/
if (cached && (!current || cached.tag !== current.tag)) {
cached.componentInstance.$destroy()
}
cache[key] = null
remove(keys, key)
}
在mounted钩子函数中观测 include 和 exclude 的变化,如下:
mounted () {
this.$watch('include', val => {
pruneCache(this, name => matches(val, name))
})
this.$watch('exclude', val => {
pruneCache(this, name => !matches(val, name))
})
}
如果include 或exclude 发生了变化,即表示定义需要缓存的组件的规则或者不需要缓存的组件的规则发生了变化,那么就执行pruneCache函数,函数如下
function pruneCache (keepAliveInstance, filter) {
const { cache, keys, _vnode } = keepAliveInstance
for (const key in cache) {
const cachedNode = cache[key]
if (cachedNode) {
const name = getComponentName(cachedNode.componentOptions)
if (name && !filter(name)) {
pruneCacheEntry(cache, key, keys, _vnode)
}
}
}
}
在该函数内对this.cache对象进行遍历,取出每一项的name值,用其与新的缓存规则进行匹配,如果匹配不上,则表示在新的缓存规则下该组件已经不需要被缓存,则调用pruneCacheEntry函数将其从this.cache对象剔除即可
关于keep-alive的最强大缓存功能是在render函数中实现
首先获取组件的key值:
const key = vnode.key == null?
componentOptions.Ctor.cid + (componentOptions.tag ? `::${componentOptions.tag}` : '')
: vnode.key
拿到key值后去this.cache对象中去寻找是否有该值,如果有则表示该组件有缓存,即命中缓存,如下:
/* 如果命中缓存,则直接从缓存中拿 vnode 的组件实例 */
if (cache[key]) {
vnode.componentInstance = cache[key].componentInstance
/* 调整该组件key的顺序,将其从原来的地方删掉并重新放在最后一个 */
remove(keys, key)
keys.push(key)
}
直接从缓存中拿 vnode 的组件实例,此时重新调整该组件key的顺序,将其从原来的地方删掉并重新放在this.keys中最后一个
this.cache对象中没有该key值的情况,如下:
/* 如果没有命中缓存,则将其设置进缓存 */
else {
cache[key] = vnode
keys.push(key)
/* 如果配置了max并且缓存的长度超过了this.max,则从缓存中删除第一个 */
if (this.max && keys.length > parseInt(this.max)) {
pruneCacheEntry(cache, keys[0], keys, this._vnode)
}
}
表明该组件还没有被缓存过,则以该组件的key为键,组件vnode为值,将其存入this.cache中,并且把key存入this.keys中
此时再判断this.keys中缓存组件的数量是否超过了设置的最大缓存数量值this.max,如果超过了,则把第一个缓存组件删掉
谈一谈对Vue组件化的理解
- 组件化开发能大幅提高开发效率、测试性、复用性等
- 常用的组件化技术:属性、自定义事件、插槽
- 降低更新频率,只重新渲染变化的组件
- 组件的特点:高内聚、低耦合、单向数据流
Watch中的deep:true是如何实现的
当用户指定了
watch中的deep属性为true时,如果当前监控的值是数组类型。会对对象中的每一项进行求值,此时会将当前watcher存入到对应属性的依赖中,这样数组中对象发生变化时也会通知数据更新
源码相关
get () {
pushTarget(this) // 先将当前依赖放到 Dep.target上
let value
const vm = this.vm
try {
value = this.getter.call(vm, vm)
} catch (e) {
if (this.user) {
handleError(e, vm, `getter for watcher "${this.expression}"`)
} else {
throw e
}
} finally {
if (this.deep) { // 如果需要深度监控
traverse(value) // 会对对象中的每一项取值,取值时会执行对应的get方法
}popTarget()
}
双向绑定的原理是什么
我们都知道 Vue 是数据双向绑定的框架,双向绑定由三个重要部分构成
- 数据层(Model):应用的数据及业务逻辑
- 视图层(View):应用的展示效果,各类UI组件
- 业务逻辑层(ViewModel):框架封装的核心,它负责将数据与视图关联起来
而上面的这个分层的架构方案,可以用一个专业术语进行称呼:MVVM这里的控制层的核心功能便是 “数据双向绑定” 。自然,我们只需弄懂它是什么,便可以进一步了解数据绑定的原理
理解ViewModel
它的主要职责就是:
- 数据变化后更新视图
- 视图变化后更新数据
当然,它还有两个主要部分组成
- 监听器(
Observer):对所有数据的属性进行监听 - 解析器(
Compiler):对每个元素节点的指令进行扫描跟解析,根据指令模板替换数据,以及绑定相应的更新函数
Vue-router基本使用
mode
hashhistory
跳转
- 编程式(js跳转)
this.$router.push('/') - 声明式(标签跳转)
<router-link to=""></router-link>
vue路由传参数
- 使用
query方法传入的参数使用this.$route.query接受 - 使用
params方式传入的参数使用this.$route.params接受
占位
<router-view></router-view>
为什么要使用异步组件
- 节省打包出的结果,异步组件分开打包,采用
jsonp的方式进行加载,有效解决文件过大的问题。 - 核心就是包组件定义变成一个函数,依赖
import()语法,可以实现文件的分割加载。
components:{
AddCustomerSchedule:(resolve)=>import("../components/AddCustomer") // require([])
}
原理
export function ( Ctor: Class<Component> | Function | Object | void, data: ?VNodeData, context: Component, children: ?Array<VNode>, tag?: string ): VNode | Array<VNode> | void {
// async component
let asyncFactory
if (isUndef(Ctor.cid)) {
asyncFactory = Ctor
Ctor = resolveAsyncComponent(asyncFactory, baseCtor) // 默认调用此函数时返回 undefiend
// 第二次渲染时Ctor不为undefined
if (Ctor === undefined) {
return createAsyncPlaceholder( // 渲染占位符 空虚拟节点
asyncFactory,
data,
context,
children,
tag
)
}
}
}
function resolveAsyncComponent ( factory: Function, baseCtor: Class<Component> ): Class<Component> | void {
if (isDef(factory.resolved)) {
// 3.在次渲染时可以拿到获取的最新组件
return factory.resolved
}
const resolve = once((res: Object | Class<Component>) => {
factory.resolved = ensureCtor(res, baseCtor)
if (!sync) {
forceRender(true) //2. 强制更新视图重新渲染
} else {
owners.length = 0
}
})
const reject = once(reason => {
if (isDef(factory.errorComp)) {
factory.error = true forceRender(true)
}
})
const res = factory(resolve, reject)// 1.将resolve方法和reject方法传入,用户调用 resolve方法后
sync = false
return factory.resolved
}
组件中写name属性的好处
可以标识组件的具体名称方便调试和查找对应属性
// 源码位置 src/core/global-api/extend.js
// enable recursive self-lookup
if (name) {
Sub.options.components[name] = Sub // 记录自己 在组件中递归自己 -> jsx
}
Vue computed 实现
- 建立与其他属性(如:
data、Store)的联系; - 属性改变后,通知计算属性重新计算
实现时,主要如下
- 初始化
data, 使用Object.defineProperty把这些属性全部转为getter/setter。 - 初始化
computed, 遍历computed里的每个属性,每个computed属性都是一个watch实例。每个属性提供的函数作为属性的getter,使用Object.defineProperty转化。 Object.defineProperty getter依赖收集。用于依赖发生变化时,触发属性重新计算。- 若出现当前
computed计算属性嵌套其他computed计算属性时,先进行其他的依赖收集
怎么缓存当前的组件?缓存后怎么更新
缓存组件使用keep-alive组件,这是一个非常常见且有用的优化手段,vue3中keep-alive有比较大的更新,能说的点比较多
思路
- 缓存用
keep-alive,它的作用与用法 - 使用细节,例如缓存指定/排除、结合
router和transition - 组件缓存后更新可以利用
activated或者beforeRouteEnter - 原理阐述
回答范例
- 开发中缓存组件使用
keep-alive组件,keep-alive是vue内置组件,keep-alive包裹动态组件component时,会缓存不活动的组件实例,而不是销毁它们,这样在组件切换过程中将状态保留在内存中,防止重复渲染DOM
<keep-alive>
<component :is="view"></component>
</keep-alive>
- 结合属性
include和exclude可以明确指定缓存哪些组件或排除缓存指定组件。vue3中结合vue-router时变化较大,之前是keep-alive包裹router-view,现在需要反过来用router-view包裹keep-alive
<router-view v-slot="{ Component }">
<keep-alive>
<component :is="Component"></component>
</keep-alive>
</router-view>
- 缓存后如果要获取数据,解决方案可以有以下两种
beforeRouteEnter:在有vue-router的项目,每次进入路由的时候,都会执行beforeRouteEnter
beforeRouteEnter(to, from, next){
next(vm=>{
console.log(vm)
// 每次进入路由执行
vm.getData() // 获取数据
})
},
actived:在keep-alive缓存的组件被激活的时候,都会执行actived钩子
activated(){
this.getData() // 获取数据
},
keep-alive是一个通用组件,它内部定义了一个map,缓存创建过的组件实例,它返回的渲染函数内部会查找内嵌的component组件对应组件的vnode,如果该组件在map中存在就直接返回它。由于component的is属性是个响应式数据,因此只要它变化,keep-alive的render函数就会重新执行
Vue.extend 作用和原理
官方解释:
Vue.extend使用基础Vue构造器,创建一个“子类”。参数是一个包含组件选项的对象。
其实就是一个子类构造器 是 Vue 组件的核心 api 实现思路就是使用原型继承的方法返回了 Vue 的子类 并且利用 mergeOptions 把传入组件的 options 和父类的 options 进行了合并
extend是构造一个组件的语法器。然后这个组件你可以作用到Vue.component这个全局注册方法里还可以在任意vue模板里使用组件。 也可以作用到vue实例或者某个组件中的components属性中并在内部使用apple组件。Vue.component你可以创建 ,也可以取组件。
相关代码如下
export default function initExtend(Vue) {
let cid = 0; //组件的唯一标识
// 创建子类继承Vue父类 便于属性扩展
Vue.extend = function (extendOptions) {
// 创建子类的构造函数 并且调用初始化方法
const Sub = function VueComponent(options) {
this._init(options); //调用Vue初始化方法
};
Sub.cid = cid++;
Sub.prototype = Object.create(this.prototype); // 子类原型指向父类
Sub.prototype.constructor = Sub; //constructor指向自己
Sub.options = mergeOptions(this.options, extendOptions); //合并自己的options和父类的options
return Sub;
};
}
谈一下对 vuex 的个人理解
vuex 是专门为 vue 提供的全局状态管理系统,用于多个组件中数据共享、数据缓存等。(无法持久化、内部核心原理是通过创造一个全局实例 new Vue)
主要包括以下几个模块:
- State:定义了应用状态的数据结构,可以在这里设置默认的初始状态。
- Getter:允许组件从 Store 中获取数据,mapGetters 辅助函数仅仅是将 store 中的 getter 映射到局部计算属性。
- Mutation:是唯一更改 store 中状态的方法,且必须是同步函数。
- Action:用于提交 mutation,而不是直接变更状态,可以包含任意异步操作。
- Module:允许将单一的 Store 拆分为多个 store 且同时保存在单一的状态树中。
请说明Vue中key的作用和原理,谈谈你对它的理解
key是为Vue中的VNode标记的唯一id,在patch过程中通过key可以判断两个虚拟节点是否是相同节点,通过这个key,我们的diff操作可以更准确、更快速diff算法的过程中,先会进行新旧节点的首尾交叉对比,当无法匹配的时候会用新节点的key与旧节点进行比对,然后检出差异- 尽量不要采用索引作为
key - 如果不加
key,那么vue会选择复用节点(Vue的就地更新策略),导致之前节点的状态被保留下来,会产生一系列的bug - 更准确 :因为带
key就不是就地复用了,在sameNode函数a.key === b.key对比中可以避免就地复用的情况。所以会更加准确。 - 更快速 :
key的唯一性可以被Map数据结构充分利用,相比于遍历查找的时间复杂度O(n),Map的时间复杂度仅仅为O(1),比遍历方式更快。
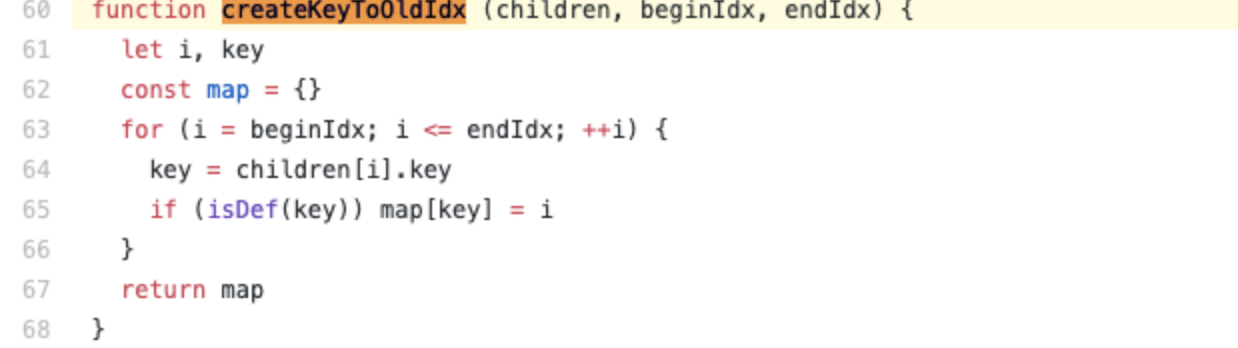
源码如下:
function createKeyToOldIdx (children, beginIdx, endIdx) {
let i, key
const map = {}
for (i = beginIdx; i <= endIdx; ++i) {
key = children[i].key
if (isDef(key)) map[key] = i
}
return map
}
回答范例
分析
这是一道特别常见的问题,主要考查大家对虚拟DOM和patch细节的掌握程度,能够反映面试者理解层次
思路分析:
- 给出结论,
key的作用是用于优化patch性能 key的必要性- 实际使用方式
- 总结:可从源码层面描述一下
vue如何判断两个节点是否相同
回答范例:
key的作用主要是为了更高效的更新虚拟DOMvue在patch过程中 判断两个节点是否是相同节点是key是一个必要条件 ,渲染一组列表时,key往往是唯一标识,所以如果不定义key的话,vue只能认为比较的两个节点是同一个,哪怕它们实际上不是,这导致了频繁更新元素,使得整个patch过程比较低效,影响性能- 实际使用中在渲染一组列表时
key必须设置,而且必须是唯一标识,应该避免使用数组索引作为key,这可能导致一些隐蔽的bug;vue中在使用相同标签元素过渡切换时,也会使用key属性,其目的也是为了让vue可以区分它们,否则vue只会替换其内部属性而不会触发过渡效果 - 从源码中可以知道,
vue判断两个节点是否相同时主要判断两者的key和标签类型(如div)等,因此如果不设置key,它的值就是undefined,则可能永远认为这是两个相同节点,只能去做更新操作,这造成了大量的dom更新操作,明显是不可取的
如果不使用
key,Vue会使用一种最大限度减少动态元素并且尽可能的尝试就地修改/复用相同类型元素的算法。key是为Vue中vnode的唯一标记,通过这个key,我们的diff操作可以更准确、更快速
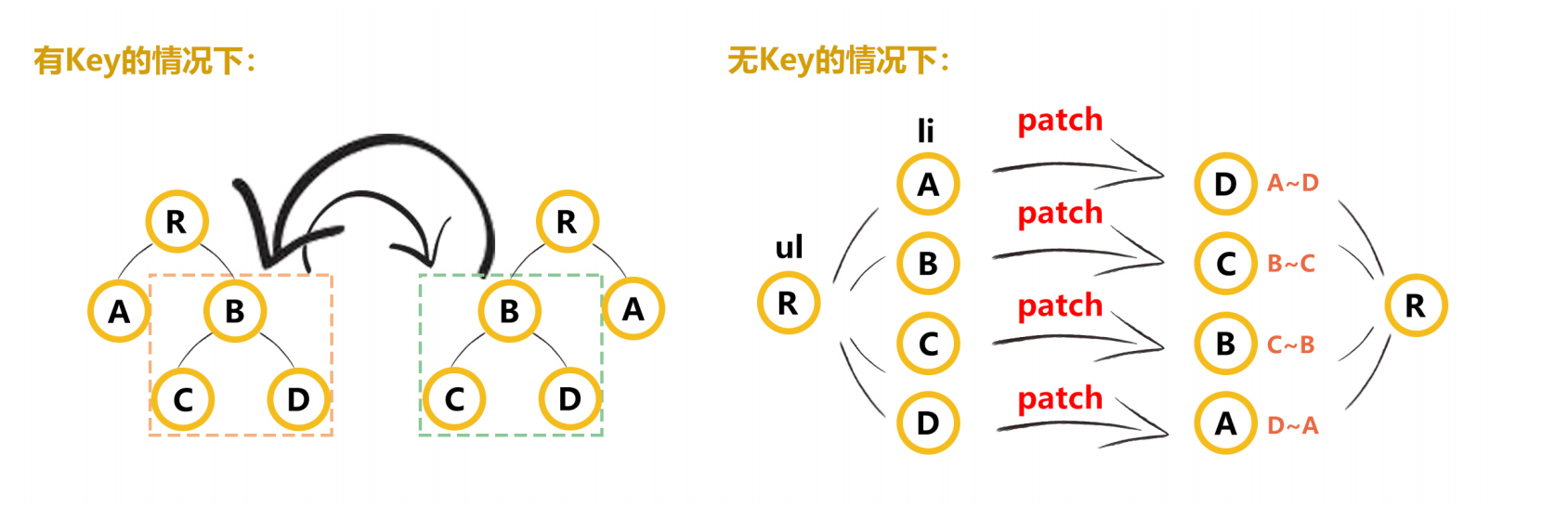
diff程可以概括为:
oldCh和newCh各有两个头尾的变量StartIdx和EndIdx,它们的2个变量相互比较,一共有4种比较方式。如果4种比较都没匹配,如果设置了key,就会用key进行比较,在比较的过程中,变量会往中间靠,一旦StartIdx>EndIdx表明oldCh和newCh至少有一个已经遍历完了,就会结束比较,这四种比较方式就是首、尾、旧尾新头、旧头新尾
相关代码如下
// 判断两个vnode的标签和key是否相同 如果相同 就可以认为是同一节点就地复用
function isSameVnode(oldVnode, newVnode) {
return oldVnode.tag === newVnode.tag && oldVnode.key === newVnode.key;
}
// 根据key来创建老的儿子的index映射表 类似 {'a':0,'b':1} 代表key为'a'的节点在第一个位置 key为'b'的节点在第二个位置
function makeIndexByKey(children) {
let map = {};
children.forEach((item, index) => {
map[item.key] = index;
});
return map;
}
// 生成的映射表
let map = makeIndexByKey(oldCh);
如何从真实DOM到虚拟DOM
涉及到Vue中的模板编译原理,主要过程:
- 将模板转换成
ast树,ast用对象来描述真实的JS语法(将真实DOM转换成虚拟DOM) - 优化树
- 将
ast树生成代码
为什么要用 Vuex 或者 Redux
由于传参的方法对于多层嵌套的组件将会非常繁琐,并且对于兄弟组件间的状态传递无能为力。我们经常会采用父子组件直接引用或者通过事件来变更和同步状态的多份拷贝。以上的这些模式非常脆弱,通常会导致代码无法维护。
所以需要把组件的共享状态抽取出来,以一个全局单例模式管理。在这种模式下,组件树构成了一个巨大的”视图”,不管在树的哪个位置,任何组件都能获取状态或者触发行为。
另外,通过定义和隔离状态管理中的各种概念并强制遵守一定的规则,代码将会变得更结构化且易维护。
虚拟DOM的优劣如何?
优点:
- 保证性能下限: 虚拟DOM可以经过diff找出最小差异,然后批量进行patch,这种操作虽然比不上手动优化,但是比起粗暴的DOM操作性能要好很多,因此虚拟DOM可以保证性能下限
- 无需手动操作DOM: 虚拟DOM的diff和patch都是在一次更新中自动进行的,我们无需手动操作DOM,极大提高开发效率
- 跨平台: 虚拟DOM本质上是JavaScript对象,而DOM与平台强相关,相比之下虚拟DOM可以进行更方便地跨平台操作,例如服务器渲染、移动端开发等等
缺点:
- 无法进行极致优化: 在一些性能要求极高的应用中虚拟DOM无法进行针对性的极致优化,比如VScode采用直接手动操作DOM的方式进行极端的性能优化
diff算法
时间复杂度: 个树的完全 diff 算法是一个时间复杂度为 O(n*3) ,vue进行优化转化成 O(n) 。
理解:
- 最小量更新,
key很重要。这个可以是这个节点的唯一标识,告诉diff算法,在更改前后它们是同一个DOM节点- 扩展
v-for为什么要有key,没有key会暴力复用,举例子的话随便说一个比如移动节点或者增加节点(修改DOM),加key只会移动减少操作DOM。
- 扩展
- 只有是同一个虚拟节点才会进行精细化比较,否则就是暴力删除旧的,插入新的。
- 只进行同层比较,不会进行跨层比较。
diff算法的优化策略:四种命中查找,四个指针
- 旧前与新前(先比开头,后插入和删除节点的这种情况)
- 旧后与新后(比结尾,前插入或删除的情况)
- 旧前与新后(头与尾比,此种发生了,涉及移动节点,那么新前指向的节点,移动到旧后之后)
- 旧后与新前(尾与头比,此种发生了,涉及移动节点,那么新前指向的节点,移动到旧前之前)
Vue为什么没有类似于React中shouldComponentUpdate的生命周期?
考点: Vue的变化侦测原理
前置知识: 依赖收集、虚拟DOM、响应式系统
根本原因是Vue与React的变化侦测方式有所不同
React是pull的方式侦测变化,当React知道发生变化后,会使用Virtual Dom Diff进行差异检测,但是很多组件实际上是肯定不会发生变化的,这个时候需要用shouldComponentUpdate进行手动操作来减少diff,从而提高程序整体的性能.
Vue是pull+push的方式侦测变化的,在一开始就知道那个组件发生了变化,因此在push的阶段并不需要手动控制diff,而组件内部采用的diff方式实际上是可以引入类似于shouldComponentUpdate相关生命周期的,但是通常合理大小的组件不会有过量的diff,手动优化的价值有限,因此目前Vue并没有考虑引入shouldComponentUpdate这种手动优化的生命周期.
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/51186.html

