
思维导图大纲
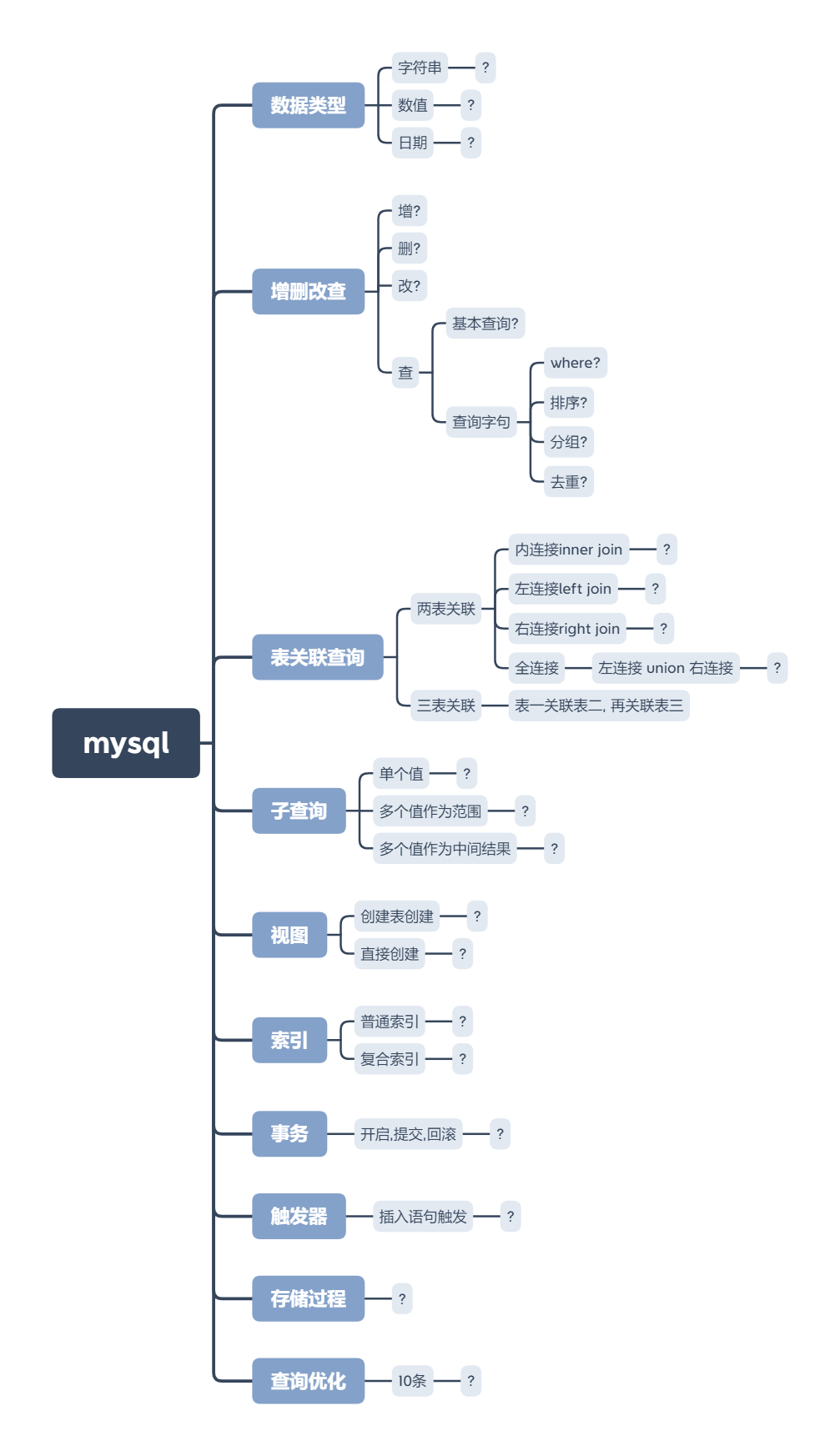

下面我将根据思维导图来复习
MySQL基本数据类型
常见的其实就分为3种:
字符串:char[字符型],varchar[可变字符型]
数值型:int[整数型],bigint[长整型],float[小数型]
日期型:date[日期型],DATETIME[时间日期型],TIMESTAMP[时间轴]
增删改查
做这件事情之前我们要先建库建表,否则无法操作
–建库CREATE DATABASE IF NOT EXISTS WORKS DEFAULT CHARSET UTF8;
创建了一个名为works的库指定默认字符集为utf8;
–指定库USE WORKS;
指定从这个库进行操作;
–创建表
我这里创建了三张表(如下)
点击查看代码
-- ----------------------------
-- Table structure for studentsinfo(学生信息表)
-- ----------------------------
DROP TABLE
IF
EXISTS `studentsinfo`;
CREATE TABLE `studentsinfo` (
`S_ID` INT NOT NULL AUTO_INCREMENT COMMENT '主键id',
`S_NO` BIGINT NULL DEFAULT NULL COMMENT '学号',
`S_NAME` VARCHAR ( 50 ) CHARACTER
SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '姓名',
`S_AGE` INT NOT NULL COMMENT '年龄',
`S_GENDER` VARCHAR ( 8 ) CHARACTER
SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '性别',
`S_BIRTHDAY` date NULL DEFAULT NULL COMMENT '生日',
`S_PHONE` VARCHAR ( 15 ) CHARACTER
SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '手机号码',
PRIMARY KEY ( `S_ID` ) USING BTREE
) ENGINE = INNODB CHARACTER
SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for courseinfo(课程表)
-- ----------------------------
DROP TABLE
IF
EXISTS `courseinfo`;
CREATE TABLE `courseinfo` (
`C_ID` INT NOT NULL AUTO_INCREMENT COMMENT '主键',
`C_SID` INT NULL DEFAULT NULL COMMENT '学生表外键',
`C_NAME` VARCHAR ( 30 ) CHARACTER
SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '课程名称',
`C_CNO` VARCHAR ( 50 ) CHARACTER
SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '课程编号',
PRIMARY KEY ( `C_ID` ) USING BTREE
) ENGINE = INNODB AUTO_INCREMENT = 1001 CHARACTER
SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for resultsinfo(成绩表)
-- ----------------------------
DROP TABLE
IF
EXISTS `resultsinfo`;
CREATE TABLE `resultsinfo` ( `R_CID` INT NULL DEFAULT NULL COMMENT '课程表外键', `R_SID` INT NULL DEFAULT NULL COMMENT '学生表外键', `R_SCORE` FLOAT NULL DEFAULT NULL COMMENT '分数' ) ENGINE = INNODB CHARACTER
SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
下面我将对这三个表进行增删改查的操作
–插入数据(增)
—————学生信息表—————
点击查看代码
-- ----------------------------
-- Records of studentsinfo
-- ----------------------------
INSERT INTO `studentsinfo`
VALUES
( 1, 202042501001, '张三', 18, '男', '2002-01-01', '18798850452' );
INSERT INTO `studentsinfo`
VALUES
( 2, 202042501002, '李四', 22, '男', '1999-05-01', '18298850452' );
INSERT INTO `studentsinfo`
VALUES
( 3, 202042501003, '王五', 31, '男', '1980-11-01', '18698850452' );
INSERT INTO `studentsinfo`
VALUES
( 4, 202042501004, '李大钊', 17, '男', '2003-01-01', '18498850452' );
INSERT INTO `studentsinfo`
VALUES
( 5, 202042501005, '陈独秀', 19, '男', '2001-01-01', '18998850452' );
INSERT INTO `studentsinfo`
VALUES
( 6, 202042501006, '金城武', 20, '男', '2000-01-11', '18898850452' );
INSERT INTO `studentsinfo`
VALUES
( 7, 202042501007, '郭德纲', 24, '男', '1999-01-01', '18098850452' );
INSERT INTO `studentsinfo`
VALUES
( 8, 202042501008, '旺仔小乔', 21, '男', '2000-07-01', '18298850452' );
—————课程表—————
点击查看代码
-- ----------------------------
-- Records of courseinfo
-- ----------------------------
INSERT INTO `courseinfo`
VALUES
( 1001, NULL, '语文', '#3C645' );
INSERT INTO `courseinfo`
VALUES
( 1002, NULL, '数学', '#4567C' );
INSERT INTO `courseinfo`
VALUES
( 1003, NULL, '英语', '#445CC' );
INSERT INTO `courseinfo`
VALUES
( 1004, NULL, '计算机', '#65789' );
INSERT INTO `courseinfo`
VALUES
( 1005, NULL, '普通话', '#4CFRD' );
—————成绩表—————
点击查看代码
-- ----------------------------
-- Records of resultsinfo
-- ----------------------------
INSERT INTO `resultsinfo`
VALUES
( NULL, NULL, 87.9 );
INSERT INTO `resultsinfo`
VALUES
( NULL, NULL, 99.6 );
INSERT INTO `resultsinfo`
VALUES
( NULL, NULL, 95 );
INSERT INTO `resultsinfo`
VALUES
( NULL, NULL, 87 );
INSERT INTO `resultsinfo`
VALUES
( NULL, NULL, 89.5 );
–删除数据(删)
删除学生表叫张三的学生DELETE FROM STUDENTSINFO WHERE S_NAME = '张三';
–修改数据(改)
把学生表姓名叫旺仔小乔的学生,性别修改成女UPDATE STUDENTSINFO SET S_GENDER = '女' WHERE S_NAME = '旺仔小乔';
–查询数据(查)
基本查询(查询全表)SELECT * FROM STUDENTSINFO;
条件查询:
查询所有的女生SELECT * FROM STUDENTSINFO WHERE S_GENDER = '女';
查询男生的数量SELECT COUNT(*) FROM STUDENTSINFO WHERE S_GENDER = '男';
排序(升序)SELECT * FROM STUDENTSINFO ORDER BY ( S_ID ) ASC;
排序(降序)SELECT * FROM STUDENTSINFO ORDER BY ( S_ID ) DESC;
分组(按照姓名进行分组,并统计数量)SELECT S_NAME, COUNT(*) FROM STUDENTSINFO GROUP BY S_NAME;
去重(因为没有重复数据,这里仅作语法展示)SELECT DISTINCT S_NAME,S_AGE FROM STUDENTSINFO;
表关联查询
二表关联:
内连接:SELECT S.*,C.* FROM STUDENTSINFO S INNER JOIN COURSEINFO C ON S.S_ID=C.C_SID;
左连接:SELECT S.*,C.* FROM STUDENTSINFO S LEFT JOIN COURSEINFO C ON S.S_ID=C.C_SID;
右连接:SELECT S.*,C.* FROM STUDENTSINFO S RIGHT JOIN COURSEINFO C ON S.S_ID=C.C_SID;
全连接:SELECT S.*,C.* FROM STUDENTSINFO S LEFT JOIN COURSEINFO C ON S.S_ID=C.C_SID UNION SELECT S.*,C.* FROM STUDENTSINFO S RIGHT JOIN COURSEINFO C ON S.S_ID=C.C_SID;
三表关联:SELECT S.*, C.*, R.* FROM STUDENTSINFO S LEFT JOIN COURSEINFO C ON S.S_ID = C.C_SID LEFT JOIN RESULTSINFO R ON S.S_ID = R.R_SID;
子查询
单值:SELECT * FROM STUDENTSINFO WHERE S_AGE = (SELECT R_SCORE FROM RESULTSINFO WHERE R_SCORE = 87);
多值:SELECT * FROM STUDENTSINFO WHERE ( 'S_ID', 'S_AGE' ) = ( SELECT R_SID, R_SCORE FROM RESULTSINFO WHERE R_SCORE = 87 );
视图
为学生表创建一个视图CREATE VIEW v_students AS SELECT * FROM studentsinfo WITH CHECK OPTION;
索引
创建普通索引:CREATE INDEX index_students_name ON studentsinfo(S_NAME);
创建复合索引:CREATE INDEX index_students_composite ON studentsinfo(S_BIRTHDAY,S_AGE);
事务
开启事务:BEGIN;
提交事务:COMMIT;
事务回滚:ROLLBACK;
触发器
点击查看代码
DELIMITER $
CREATE TRIGGER stu_cj
AFTER INSERT ON studentsinfo FOR EACH ROW
BEGIN
INSERT INTO studentsinfo (S_NAME,S_AGE) VALUES (new.S_NAME,new.S_AGE);
END $
DELIMITER;
存储过程
创建存储过程:
点击查看代码
DELIMITER $
CREATE PROCEDURE SPROCEDURE()
BEGIN
#声明变量类型
DECLARE UN VARCHAR(50) DEFAULT '';
#给USERNAME变量赋值
SET UN='李白';
#将查询结果赋值给UN变量
SELECT S_NAME INTO UN FROM STUDENTSINFO WHERE S_ID = 2;
#查询UN变量,返回
SELECT UN;
END $
DELIMITER;
调用存储过程:CALL SPROCEDURE();
查询优化
点击查看代码
1.对查询进行优化
应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
2.应尽量避免在 where 子句中对字段进行 null 值判断,
否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0
3.应尽量避免在 where 子句中使用!=或<>操作符,否则引擎将放弃使用索引而进行全表扫描。
SELECT id FROM employee WHERE id != “B%”
4.应尽量避免在 where 子句中使用or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
可以这样查询:
select id from t where num=10 union all select id from t where num=20
5.in 和 not in 也要慎用,否则会导致全表扫描,
如:select id from t where num in(1,2,3) 对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
6.下面的查询也将导致全表扫描:
select id from t where name like '李%'
若要提高效率,可以考虑全文检索。
如果在 where 子句中使用参数,也会导致全表扫描。
因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然 而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描:
select id from t where num=@num
可以改为强制查询使用索引:
select id from t with(index(索引名)) where num=@num
8.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100
应改为:
select id from t where num=100*2
9.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where substring(name,1,3)='abc'
name以abc开头的id,应改为:
select id from t where name like 'abc%'
10.不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
SELECT * FROM T1 WHERE processid+11=10
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/5923.html

