
🌵爬虫之Scrapy系列文章
🌱欢迎点赞评论学习交流~
🌴各位看官多多关注哦😘~
目录
🍉Scrapy框架的介绍

原本是设计用来屏幕抓取(更精确的说,是网络抓取),但它也可以用来访问
API来提取数据。
🌴Scrapy框架的模块
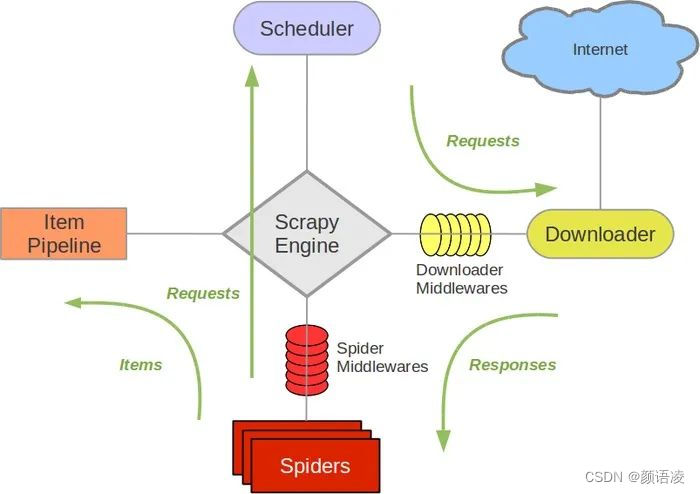
这张图片完整的概括了Scrapy框架是如何运作的以及它包括的五大组件分别为:Spiders(爬虫),Scheduler(调度器),Downloader(下载器),ItemPipeline(管道),当然还有最最核心的ScrapyEngine(引擎)。哈哈,图片看起来好像挺难的,其实原理挺简单的。首先,Scrapy框架的入口是Spiders(爬虫),通过爬虫我们能够获取到网址链接之类的,之后把获取的结果通过引擎给调度器大哥,大哥通过整理把结果给了下载器小弟,这可不是给它下载的哦,而是小弟向服务器发送请求获取相应的响应,下载器通过引擎将响应再还给爬虫,然后爬虫将我们需要获取的内容给到管道下载,含有二级网址链接再循环以上步骤。听我这么一讲是不是更迷糊了呢?下面更有详细的步骤😉。
🌴Scrapy模块的运作
框架运行流程:

🍉创建项目
🌴前期准备
我们在了解完Scrapy框架各个模块以及其运作流程后,我们要开始创建项目了~
🌱环境安装
查找历史版本:https://pypi.org/project/Scrapy/#history
pip install scrapy
🌱项目搭建
win + R 打开命令行窗口输入以下命令
scrapy startproject xxxx
🌱创建爬虫
xxxx 为你创建项目的路径
cd xxxx
scrapy genspider 爬虫名称 网站域名
🌱项目介绍
输入完以上命令后程序自动在指定目录生成项目文件,恭喜你,到此你已经完成了项目的一半了。
说明:
- scrapy.cfg:它是 Scrapy 项目的配置文件,其内定义了项目的配置文件路径、部署相关信息等内容。
- items.py:它定义 Item 数据结构,所有的 Item 的定义都可以放这里。
- pipelines.py:它定义 Item Pipeline 的实现,所有的 Item Pipeline 的实现都可以放这里。
- settings.py:它定义项目的全局配置。
- middlewares.py:它定义 Spider Middlewares 和 Downloader Middlewares 的实现。
- spiders:其内包含一个个 Spider 的实现,每个 Spider 都有一个文件。
🍉setting设置
记录了几条需要修改的设置
# 遵循robots.txt中的爬虫规则,一般需要手动改为True
ROBOTSTXT_OBEY
=
True#
相同网站两个请求之间的间隔时间,默认是
0s
。相当于
time.sleep()DOWNLOAD_DELAY
=
3#
禁用
cookie
,默认是
True
,可用可不用COOKIES_ENABLED
=
False#
请求头设置,这里基本上不用DEFAULT_REQUEST_HEADERS
= {
‘Accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8’,‘Accept-Language’: ‘en’,}#
配置启用
Pipeline
用来持久化数据,这个在下载数据时要开启ITEM_PIPELINES
= {‘ScrapyDemo.pipelines.ScrapydemoPipeline’
:
300
,}
🍉执行爬虫
🍄 运行爬虫
在命令行窗口输入以下命令:
scrapy crawl xxxx
🍄指令运行
新建一个py文件写入:
from scrapy import cmdlinecmdline.execute(“scrapy crawl xxxx”.split())
🍉demo
🌵配置存储结构
import scrapy
class demoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
content = scrapy.Field()🌵配置spider
class CrawlSpider(scrapy.Spider):
name = 'crawl'
allowed_domains = ['baidu.com']
start_urls = ['https://www.baidu.com']
def parse(self, response):
item = items.demoItem()
item['content'] = response.text
yield item🌵存储文件编写
class demoPipeline:
def open_spider(self, spider):
self.file = open('baidu.html', 'w',encoding='utf-8')
def process_item(self, item, spider):
self.file.write(item['content'])
return item
def close_spider(self, spider):
self.file.close()🍉结束

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/61455.html

