
Redis 哈希(Hash)
1. 简介
Redis hash 是一个键值对集合。
Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。类似 Java 里面的 Map<String,Object>。
用户 ID 为查找的 key,存储的 value 用户对象包含姓名,年龄,生日等信息,如果用普通的 key/value 结构来存储。
主要有以下 2 种存储方式:
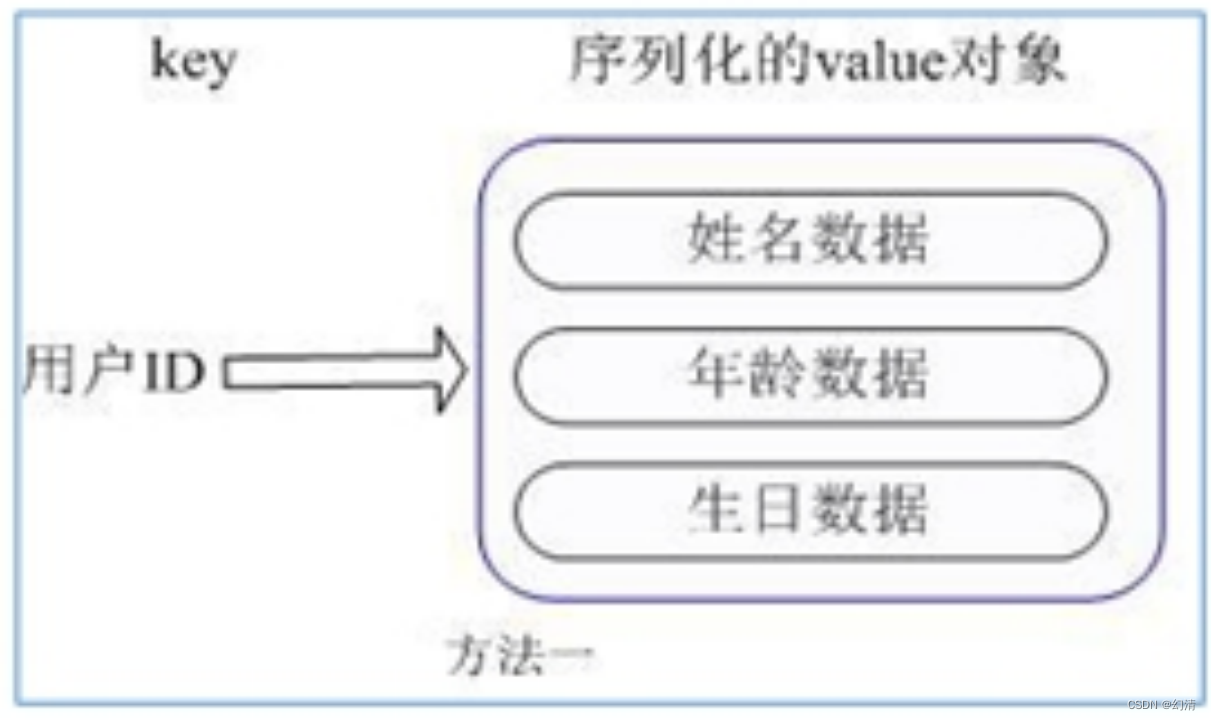

每次修改用户的某个属性需要,先反序列化改好后再序列化回去。开销较大。
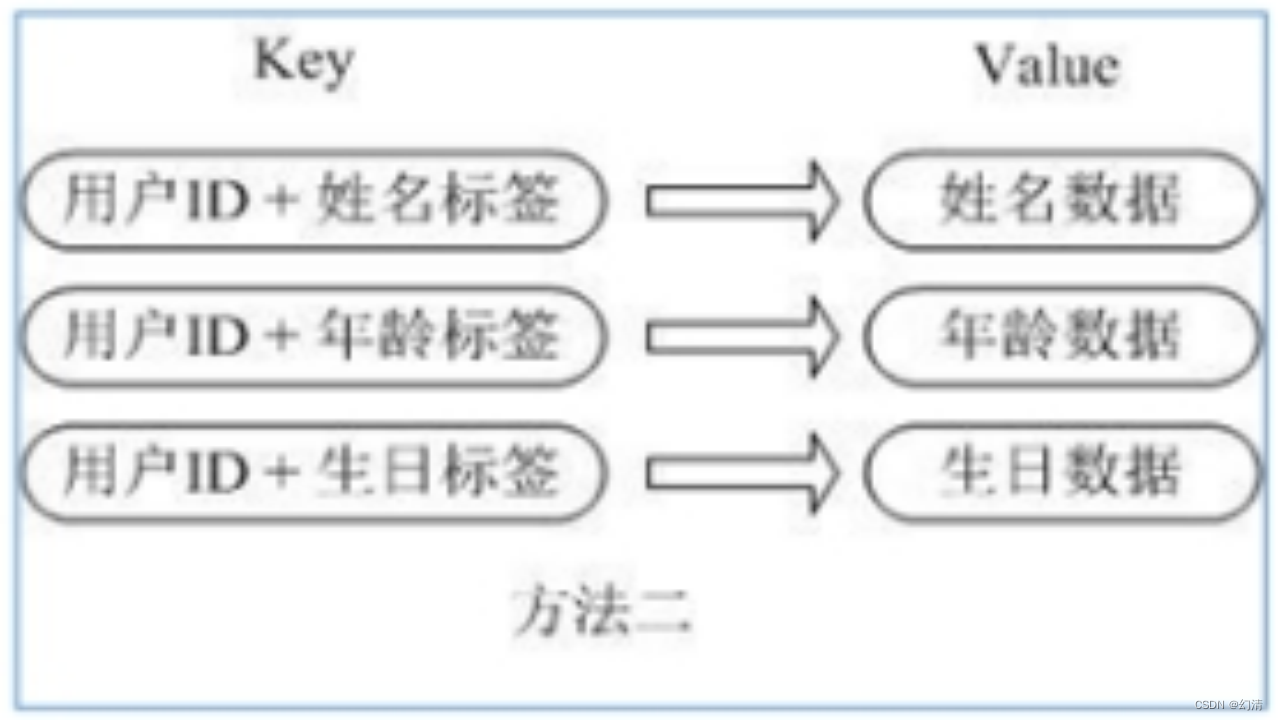
用户ID数据冗余
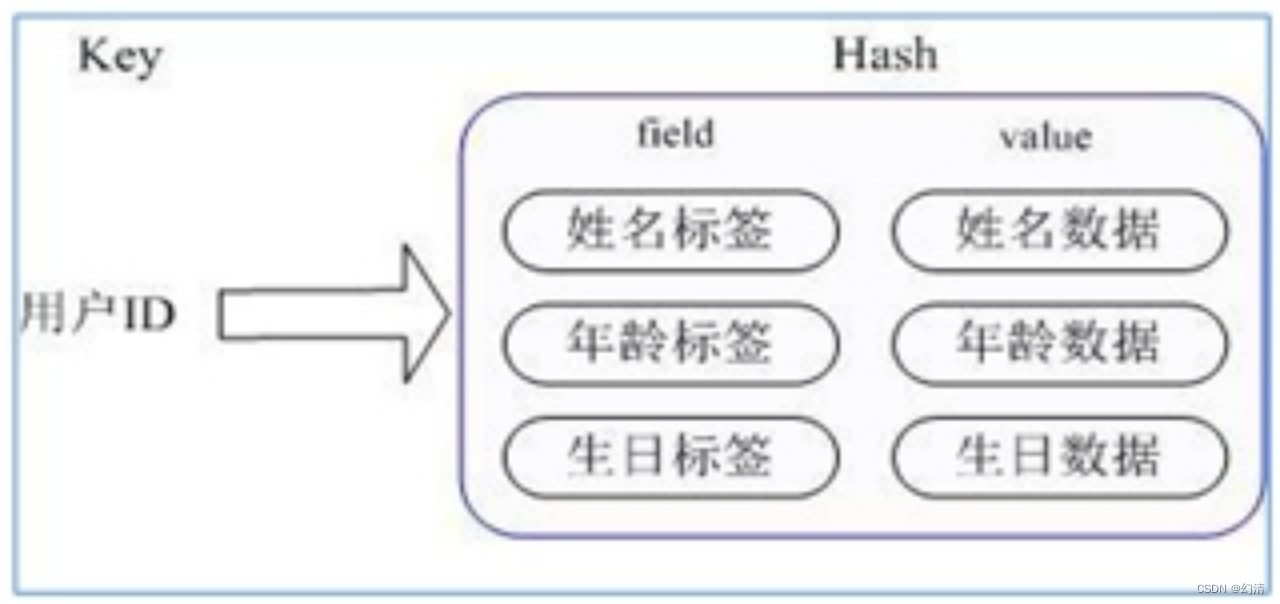
通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题。
2. 常用命令
hset <key><field><value>给<key>集合中的 <field>键赋值<value> ;
hget <key1><field>从<key1>集合<field>取出 value ;
hmset <key1><field1><value1><field2><value2>... 批量设置 hash 的值;
hexists<key1><field>查看哈希表 key 中,给定域 field 是否存在。
hkeys <key>列出该 hash 集合的所有 ;
field hvals <key>列出该 hash 集合的所有 value;
hincrby <key><field><increment>为哈希表 key 中的域 field 的值加上增量 1 -1 ;
hsetnx <key><field><value>将哈希表 key 中的域field的值设置为 value ,当且仅当域 field 不存在。
3.数据结构
Hash 类型对应的数据结构是两种:ziplist(压缩列表),hashtable(哈希表)。当 field-value 长度较短且个数较少时,使用 ziplist,否则使用 hashtable。
Redis 有序集合 Zset(sorted set)
1. 简介
Redis 有序集合 zset 与普通集合 set 非常相似,是一个没有重复元素的字符串集合。 不同之处是有序集合的每个成员都关联了一个评分(score),这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了。因为元素是有序的, 所以你也可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。 访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
2. 常用命令
zadd <key><score1><value1><score2><value2>… 将一个或多个 member 元素及其 score 值加入到有序集 key 当中。
zrange <key><start><stop> [WITHSCORES] 返回有序集 key 中,下标在
之间的元素 带 WITHSCORES,可以让分数一起和值返回到结果集。
zrangebyscore key minmax [withscores] [limit offset count] 返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。 有序集成员按 score 值递增(从小到大)次序排列。
zrevrangebyscore key maxmin [withscores] [limit offset count] 同上,改为从大到小排列。
zincrby <key><increment><value> 为元素的 score 加上增量 。
zrem <key><value>删除该集合下,指定值的元素。
zcount <key><min><max>统计该集合,分数区间内的元素个数zrank 返回该值在集合中的排名,从 0 开始。
3. 数据结构
SortedSet(zset)是 Redis 提供的一个非常特别的数据结构,一方面它等价于 Java 的 数据结构 Map<String, Double>,可以给每一个元素 value 赋予一个权重 score,另一方 面它又类似于 TreeSet,内部的元素会按照权重 score 进行排序,可以得到每个元素的名次,还可以通过 score 的范围来获取元素的列表。
zset 底层使用了两个数据结构
(1)hash,hash 的作用就是关联元素 value 和权重 score,保障元素 value 的唯一性,可以通过元素 value 找到相应的 score 值。
(2)跳跃表,跳跃表的目的在于给元素 value 排序,根据 score 的范围获取元素列表。
4. 跳跃表(跳表)
1、简介
有序集合在生活中比较常见,例如根据成绩对学生排名,根据得分对玩家排名 等。对于有序集合的底层实现,可以用数组、平衡树、链表等。数组不便元素的插入、 删除;平衡树或红黑树虽然效率高但结构复杂;链表查询需要遍历所有效率低。Redis 采用的是跳跃表。跳跃表效率堪比红黑树,实现远比红黑树简单。
2、实例
对比有序链表和跳跃表,从链表中查询出 51
(1) 有序链表

要查找值为51的元素,需要从第一个元素开始依次查找、比较才能找到。共需要6次比较。
(2)跳跃表
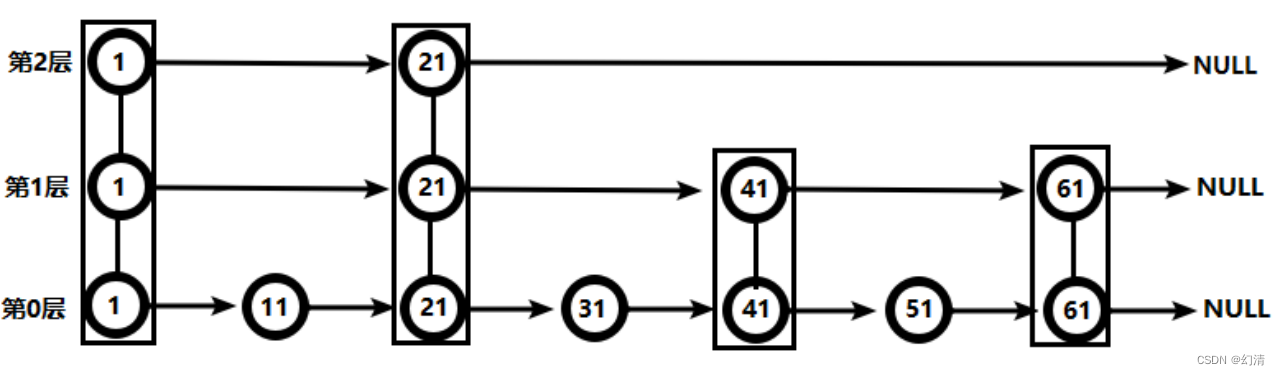
从第2层开始,1节点比51节点小,向后比较。
21节点比51节点小,继续向后比较,后面就是NULL了,所以从21节点向下到第1层。
在第1层,41节点比51节点小,继续向后,61节点比51节点大,所以从41向下。
在第0层,51节点为要查找的节点,节点被找到,共查找4次。
从此可以看出跳跃表比有序链表效率要高
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/63323.html

