
1.概述
Zipkin 是一个分布式追踪系统。它有助于收集解决服务架构中的延迟问题所需的时间数据。功能包括收集和查找此数据。
如果您在日志文件中有跟踪 ID,则可以直接跳转到它。否则,您可以根据服务、操作名称、标签和持续时间等属性进行查询。会为你总结一些有趣的数据,比如在服务中花费的时间百分比,以及操作是否失败。
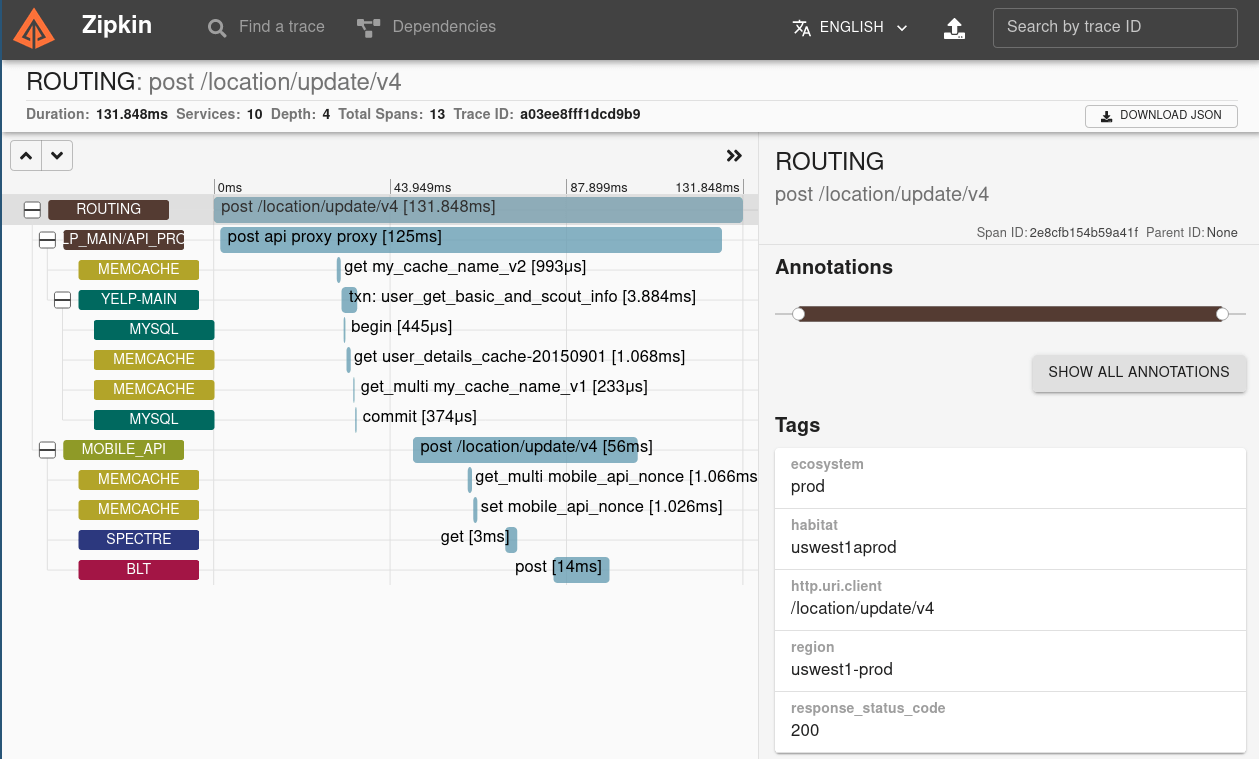
Zipkin UI 还提供了一个依赖关系图,显示有多少跟踪请求通过了每个应用程序。这有助于识别聚合行为,包括错误路径或对已弃用服务的调用。
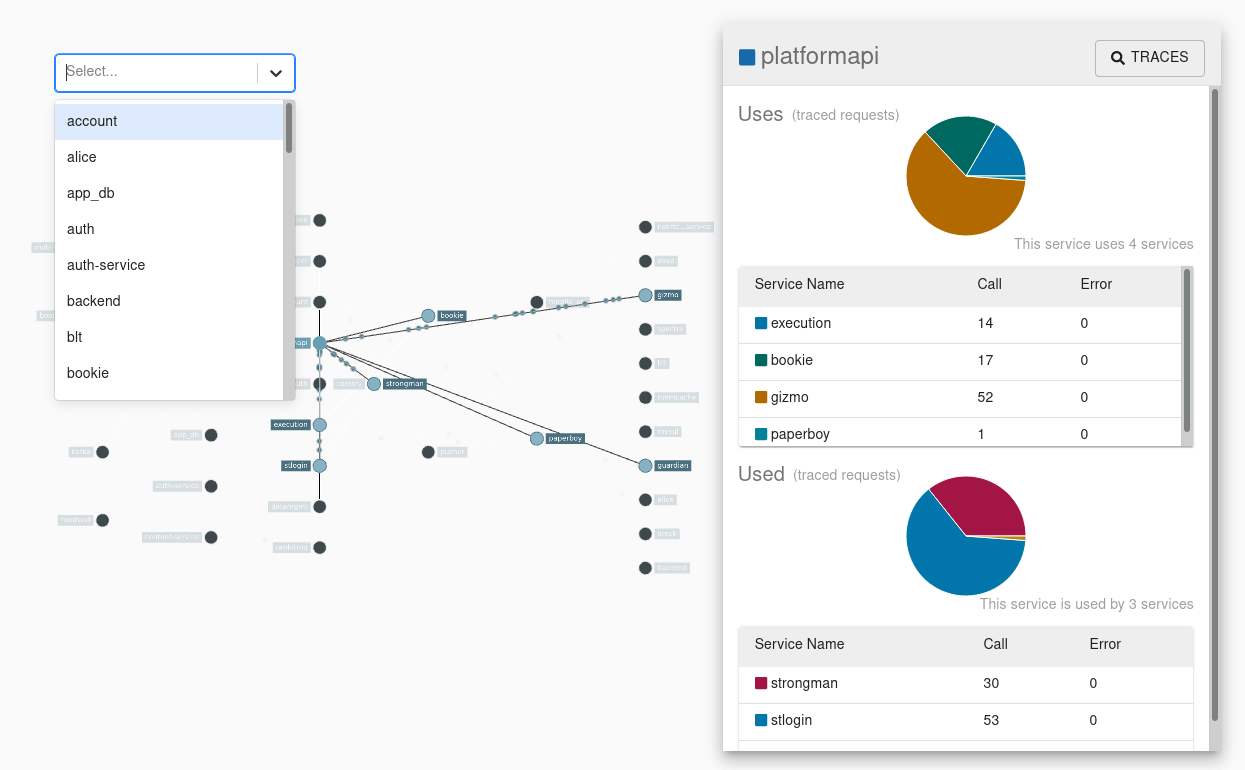
应用程序需要被“检测”以向 Zipkin 报告跟踪数据。这通常意味着配置跟踪器或检测库。向 Zipkin 报告数据的最流行方式是通过 HTTP 或 Kafka,但也有许多其他选项,例如 Apache ActiveMQ、gRPC 和 RabbitMQ。提供给 UI 的数据存储在内存中,或者通过支持的后端(例如 Apache Cassandra 或 Elasticsearch)持久存储。
2.架构概述
跟踪器存在于您的应用程序中,并记录有关所发生操作的时间和元数据。他们经常检测库,因此它们的使用对用户来说是透明的。例如,经过检测的 Web 服务器会记录它何时收到请求以及何时发送响应。收集的跟踪数据称为 Span。
Instrumentation 的编写是为了在生产中安全且开销很小。出于这个原因,它们仅在带内传播 ID,以告诉接收器正在进行跟踪。完成的 span 会带外报告给 Zipkin,类似于应用程序异步报告指标的方式。
例如,当一个操作被跟踪并且它需要发出一个传出的 http 请求时,会添加一些标头来传播 ID。标头不用于发送操作名称等详细信息。
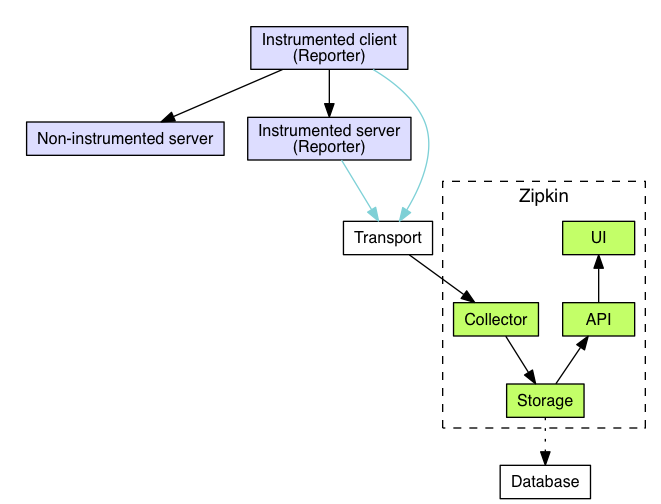
检测应用程序中向 Zipkin 发送数据的组件称为 Reporter。记者通过几种传输方式之一将跟踪数据发送到 Zipkin 收集器,后者将跟踪数据保存到存储中。稍后,API 会查询存储以向 UI 提供数据。
这是描述此流程的图表:
3.zipkin组件
zipkin有四大组件:
- collector
- storage
- search
- web UI
3.1 collector
跟踪数据到达 Zipkin 收集器守护程序后,将对其进行验证、存储和索引,以供 Zipkin 收集器查找。
3.2 storage
Zipkin 最初是为了在 Cassandra 上存储数据而构建的,因为 Cassandra 是可扩展的,具有灵活的模式,并且在 Twitter 中被大量使用。但是,我们使这个组件可插拔。除了 Cassandra,我们还原生支持 ElasticSearch 和 MySQL。其他后端可能作为第三方扩展提供。
3.3 search
一旦数据被存储和索引,我们需要一种方法来提取它。查询守护程序提供了一个简单的 JSON API 来查找和检索跟踪。此 API 的主要使用者是 Web UI
3.4 web UI
我们创建了一个 GUI,它提供了一个很好的界面来查看跟踪。Web UI 提供了一种基于服务、时间和注释查看跟踪的方法。注意:UI 中没有内置身份验证!
4.springCloud整合zipkin流程
1.使用docker下载安装zipkin
docker run -d -p 9411:9411 openzipkin/zipkin
2. 在pom.xml中导入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
3.在yml文件中配置
spring:
application:
name: user-service
zipkin:
base-url: http://192.168.56.10:9411/ # zipkin 服务器的地址
# 关闭服务发现,否则 Spring Cloud 会把 zipkin 的 url 当做服务名称
discoveryClientEnabled: false
sender:
type: web # 设置使用 http 的方式传输数据
4.查看是否启动
http://localhost:9411(根据自己启动的ip和端口访问)
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/64392.html

