
1.介绍
在二叉树的结点上加上线索的二叉树称为线索二叉树,对二叉树以某种遍历方式(如先序、中序、后序或层次等)进行遍历,使其变为线索二叉树的过程称为对二叉树进行线索化。
2.概述
对于n个结点的二叉树,在二叉链存储结构中有n+1个空链域,利用这些空链域存放在某种遍历次序下该结点的前驱结点和后继结点的指针,这些指针称为线索,加上线索的二叉树称为线索二叉树。
这种加上了线索的二叉链表称为线索链表,相应的二叉树称为线索二叉树(Threaded BinaryTree)。根据线索性质的不同,线索二叉树可分为前序线索二叉树、中序线索二叉树和后序线索二叉树三种。
注意:线索链表解决了无法直接找到该结点在某种遍历序列中的前驱和后继结点的问题,解决了二叉链表找左、右孩子困难的问题。
3.本质
二叉树的遍历本质上是将一个复杂的非线性结构转换为线性结构,使每个结点都有了唯一前驱和后继(第一个结点无前驱,最后一个结点无后继)。对于二叉树的一个结点,查找其左右子女是方便的,其前驱后继只有在遍历中得到。为了容易找到前驱和后继,有两种方法。一是在结点结构中增加向前和向后的指针,这种方法增加了存储开销,不可取;二是利用二叉树的空链指针。
4.存储结构
线索二叉树中的线索能记录每个结点前驱和后继信息。为了区别线索指针和孩子指针,在每个结点中设置两个标志ltag和rtag。
当tag和rtag为0时,leftChild和rightChild分别是指向左孩子和右孩子的指针;否则,leftChild是指向结点前驱的线索(pre),rightChild是指向结点的后继线索(suc)。由于标志只占用一个二进位,每个结点所需要的存储空间节省很多。 [3]
现将二叉树的结点结构重新定义如下:
|
lchild |
ltag |
data |
rtag |
rchild |
其中:ltag=0 时lchild指向左儿子;ltag=1 时lchild指向前驱;rtag=0 时rchild指向右儿子;rtag=1 时rchild指向后继。
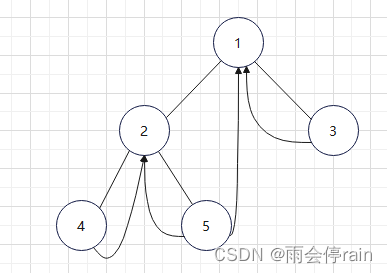
5. 图示
根据中序遍历得到如下遍历顺序


根据中序遍历得到的遍历顺序可以知道线索二叉树如下
6.java代码实现
/**
* @author wangli
* @data 2022/5/24 15:11
* @Description:
*/
public class TreadedBineryTree {
/**
* 测试中序线索二叉树是否构建成功
*/
@Test
public void testTreadedBinaryTree(){
Person root = new Person(1,"1");
Person node2 = new Person(2,"2");
Person node3 = new Person(3,"3");
Person node4 = new Person(4,"4");
Person node5 = new Person(5,"5");
//二叉树 以后会递归创建
root.setLeftPoint(node2);
root.setRightPoint(node3);
node2.setRightPoint(node5);
node2.setLeftPoint(node4);
//测试线索化
BinaryTree threadedBinaryTree = new BinaryTree();
threadedBinaryTree.setRoot(root);
threadedBinaryTree.threadedNodes();
// 遍历中序线索二叉树
threadedBinaryTree.threadedList();
//测试 以10号结点Node5测试
Person leftNode = node5.getLeftPoint();
Person rightNode = node5.getRightPoint();
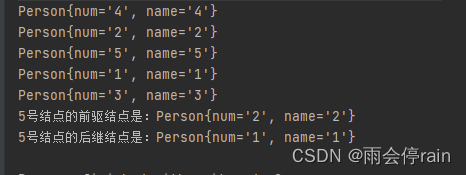
System.out.println("5号结点的前驱结点是:"+ leftNode);//2
System.out.println("5号结点的后继结点是:"+ rightNode);//1
}
@Data
public class Person{
private int num;
private String name;
private Person leftPoint;
private Person rightPoint;
/*
* 表明
* 如果leftType == 0 表示指向的是左子树,如果是1则表示指向前驱结点
* 如果fightTpye == 0表示指向的是右子树,如果是1则表示指向后驱结点
*/
private int leftType;
private int rightType;
public Person(int num, String name) {
this.num = num;
this.name = name;
}
@Override
public String toString() {
return "Person{" +
"num='" + num + '\'' +
", name='" + name + '\'' +
'}';
}
}
static class BinaryTree{
private Person root;
// 前置节点指针
private Person pre=null;
public void setRoot(Person root) {
this.root = root;
}
public void threadedNodes() {
this.threadedNodes(root);
}
public void preThreadList() {
//定义一额变量,保存当前遍历的结点,从root开始
Person node = root;
}
public Person getPre() {
return pre;
}
public void setPre(Person pre) {
this.pre = pre;
}
/**
*中序线索二叉树的遍历
*/
public void threadedList() {
//定义一个变量,存储当前遍历的结点,从root开始
Person node = root;
while(node != null) {
//循环的找到leftType == 1的结点,第一个找到的就是中序的第一个结点
//找到结点的时候按照该结点开始索引化
//处理后的有效结点
while(node.getLeftType() == 0) {
node = node.getLeftPoint();
}
//打印当前这个结点
System.out.println(node);
//当这道第一个leftType == 1表明找到了中序的头,现在可以按照头进行线索化 如果该结点有后继结点,则一直输出
while(node.getRightType() == 1) {
//获取到当前结点的后继结点
node = node.getRightPoint();
System.out.println(node);
}
//如果没有后继结点,则这个结点是个子女双全的父结点,此时按照中序输出,后一个结点应该是父结点的右子树
node = node.getRightPoint();
}
}
/**
* 使用中序遍历的方法将普通二叉树线索化变成中序线索二叉树
* @param node
*/
public void threadedNodes(Person node){
// 如何当前root节点没有数据,则无法线索化
if (node==null){
return;
}else {
// 像左线索化
threadedNodes(node.getLeftPoint());
// 处理当前节点线索化
// 首先处理当前节点的前驱节点
if (node.getLeftPoint()==null){
// 让当前节点的左指针指向前驱节点
node.setLeftPoint(pre);
// 修改当前节点的左指针为线索化类型,指向前驱节点
node.setLeftType(1);
}
// 处理后序节点需要在下一轮中进行
if (pre!=null&&pre.getRightPoint()==null){
pre.setRightPoint(node);
pre.setRightType(1);
}
//每处理一个结点后,让当前结点是下一个结点的前驱结点
pre = node;
// 像右线索化
threadedNodes(node.getRightPoint());
}
}
}
}
运行测试方法打印如下
7.优势与不足
优势
(1)利用线索二叉树进行中序遍历时,不必采用堆栈处理,速度较一般二叉树的遍历速度快,且节约存储空间。
不足
(1)结点的插入和删除麻烦,且速度也较慢。
(2)线索子树不能共用。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/64393.html

