
G1真的这么强大嘛?
介绍
我们知道,CMS收集器会有两个极端的缺点。
在Minor GC时,由于Surviver救助空间放不下了,多余的对象会提升(promotion)到老年代,但是老年代由于垃圾收集的缘故,产生了大量的内存碎片,无法分配足够的内存给这些对象,因此会产生concurrent mode failure的错误,这个时候,会降级到Serail Old收集器进行垃圾收集,这就会产生promotion failed。
这就将一次简单的Major GC演化成了非常耗时的Full GC,而且,无法预测停顿时间。
而G1垃圾收集器就是应对这一无法预测停顿时间而产生的强大利器,它可以根据设定的停顿时间为目标,尽量达成这个目标,它能够推算出本次要收集的大体区域,以增量的方式完成收集。
G1 的全称是 GarbageFirst GC,就是为了干掉CMS的。
深入
G1采用弱化了分代概念,采用了一种“分而治之”的思想,将堆划分为多个大小一致的区间(Region),它的数值是在 1M 到 32M 字节之间的一个 2 的幂值数,region大小可通过-XX:G1HeapRegionSize=520M 配置,不配置的话,则会通过计算得到,这篇文章有介绍到。每个区间既可以是新生代,也可以是老年代,G1也是有 Eden 区和 Survivor 区的概念的,只不过它们在内存上不是连续的,而是由一小份一小份组成的。
但是当有非常大的对象需要分配内存时,普通的region是难以放下的。
G1有一个专门针对大对象的region,就是下面的Humongous区,对象大小超过 Region 50% 的对象,将会在这里分配。
下面的图片很直观的展示出来了。
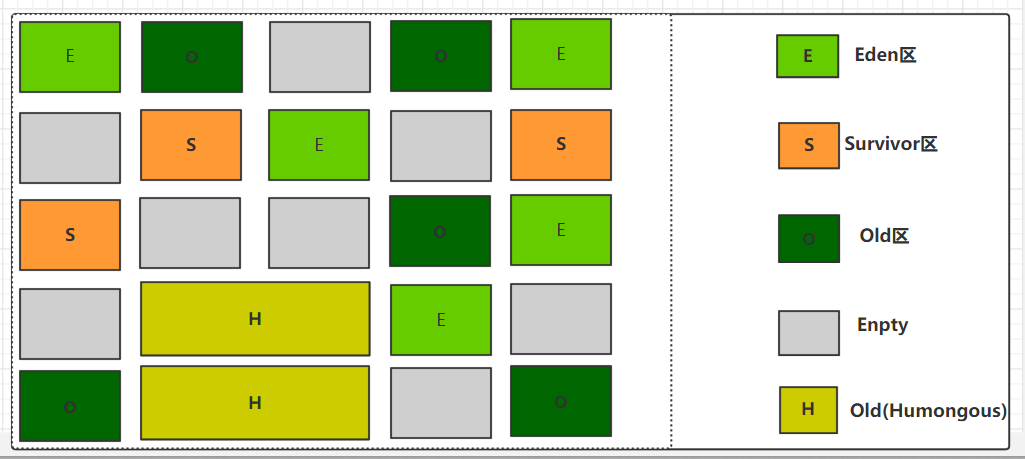

怎么回收垃圾
有没有疑惑,它在回收的时候,到底回收哪些region区呢?是随机的还是按某个规律呢?
其实,它优先回收垃圾最多的region区,这应该是它名字的由来吧:Garbage First
回收的过程
首先了解一下几个名词
-
RSet
它其实是一个以空间换时间的结构。
其实,在老年代引用了年轻代时,老年代会有一个卡表(card table)记录了相关的引用,属于points-out(我引用了谁的对象)。
而RSet的功能与此类似,它的全称是 Remembered Set,用于记录和维护 Region 之间的对象引用关系。但是又和这个有所不同,RSet记录了其他 Region 中的对象引用本 Region 中对象的关系,属于 points-into 结构(谁引用了我的对象)。G1垃圾收集器里每一个RSet对应的是一个Region内部对象引用情况,说白了就是存在Region中存活对象的指针。在标记存活对象的时候,G1使用RSet概念,将每个分区指向分区内的引用记录在该分区,避免对整个堆扫描,并行独立处理垃圾集合。它使得部分收集成为了可能。
RSet主要保存下面的引用映射关系:
- 老年代对年轻代的引用,维护老年代分区指向年轻代分区的指针
- 老年代对老年代的引用。在这里,老年代中不同分区的指针将被维护在老年代拥有分区的RSet中
如下图:我们可以看到3个分区,X(年轻代分区)、Y和Z(老年代分区)。X有一个来自Z和Y的对内引用。这个引用记录在X的RSet中,分区Y有2个对内引用,一个来自X一个来自Z,因为年轻代分区作为一个整体回收的,这时,Eden 区变空了,而在回收过程中会扫描 Survivor 分区,也没必要保存来自年轻代的引用,所以只需记录来自Z的对内引用,不用记录X的对内引用。
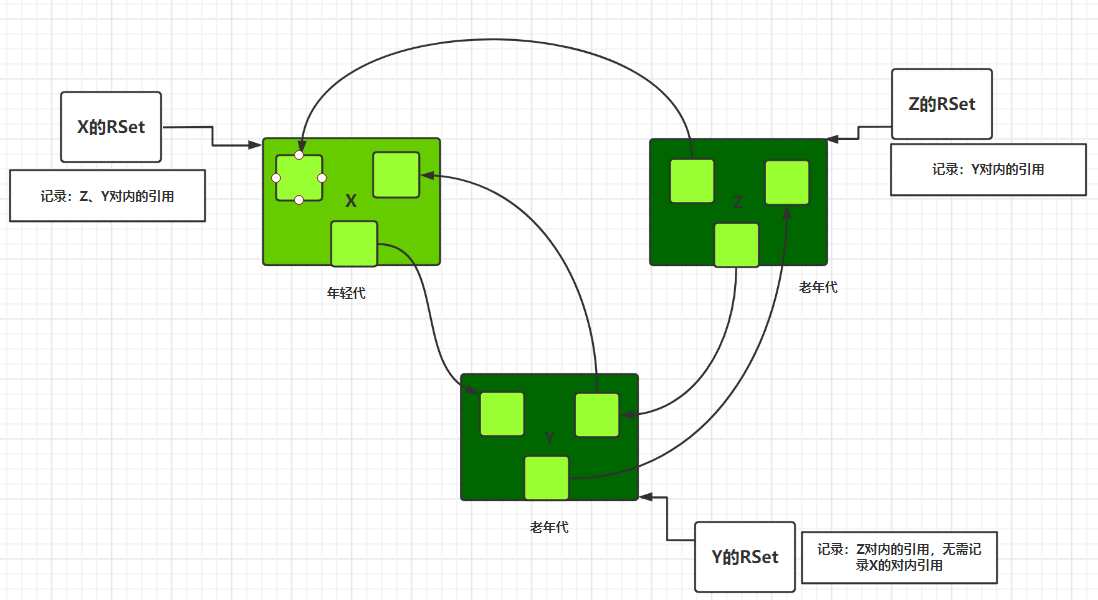
对于年轻代的 Region,它的 RSet 只保存了来自老年代的引用,这是因为年轻代的回收是针对所有年轻代 Region 的,没必要搞这个。所以说年轻代 Region 的 RSet 有可能是空的。
RSet 通常会占用很大的堆内存空间,大约 5% 或者更高。不仅仅是空间方面,很多计算开销也是比较大的。
事实上,为了维护 RSet,程序运行的过程中,写入某个字段就会产生一个 post-write barrier 。为了减少这个开销,将内容放入 RSet 的过程是异步的,而且经过了很多的优化:Write Barrier 把脏卡信息存放到本地缓冲区(local buffer),有专门的 GC 线程负责收集,并将相关信息传给被引用 Region 的 RSet。
参数 -XX:G1ConcRefinementThreads 或者 -XX:ParallelGCThreads 可以控制这个异步的过程。如果并发优化线程跟不上缓冲区的速度,就会在用户进程上完成。
- CSet
这个比较好理解,它的全称是 Collection Set,即收集集合,也就是在垃圾收集暂停过程中被回收的目标。GC时在CSet中的所有存活数据(Live Data)都会被转移,分区释放回空闲分区队列。
如图显示,左边的年轻代收集CSet代表年轻代的一部分分区,右边的混合收集CSet代表年轻代的一部分区和老年代的多个分区:
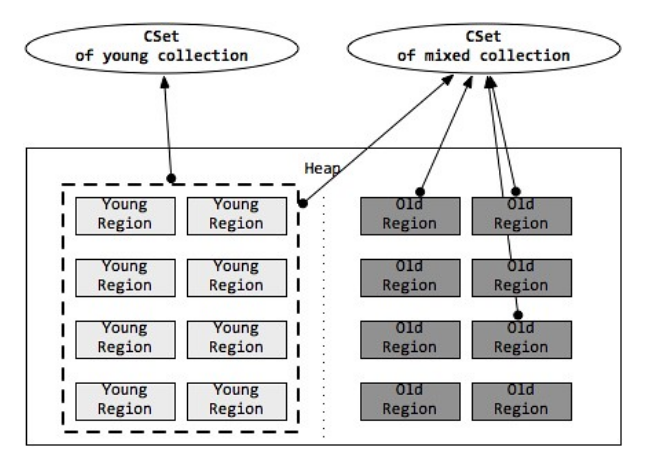
- IHOP
InitiatingHeapOccupancyPercent,简称IHOP。缺省情况是Java堆内存的45%。当老年代的空间超过45%,G1会启动一次混合周期收集
这也是G1和CMS之间较大的区别,G1的百分比是相对于整个Java堆而言的,CMS(CMSInitiatingOccupancyFraction)仅仅是针对老年代空间的占比。
》》 这是因为G1没有固定物理上分割一块内存作为老年代,而是用了Region的思想,这些Region可能是eden,survivor、老年代或者巨型分区,所以获取针对老年代本身的占用百分比没有意义
G1 的垃圾回收过程
G1是在逻辑上分为年轻代和老年代,但它的年轻代和老年代比例,并不是那么固定,为了达到 MaxGCPauseMillis 所规定的效果,G1 会自动调整两者之间的比例。
当你强行使用 -Xmn 或者 -XX:NewRatio 去设定它们的比例的话,我们给 G1 设定的这个目标将会失效。
G1垃圾回收时会有三个阶段:
- “年轻代”的垃圾回收,也叫 Minor GC,这个过程和普通的差不多,发生时机就是 Eden 区满的时候。
- “老年代”的垃圾收集,严格来说不算是收集,它是一个“并发标记”的过程,顺便清理了一点点对象。
- 真正的清理,发生在“混合模式”,它不止清理年轻代,还会将老年代的一部分区域进行清理,上面那张图片可以看到。
三个的如图所示:
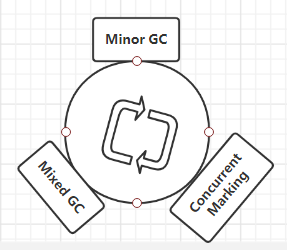
在 GC 日志里,这个过程描述特别有意思,(1)的过程,叫作 [GC pause (G1 Evacuation Pause) (young),而(2)的过程,叫作 [GC pause (G1 Evacuation Pause) (mixed)。Evacuation 是转移的意思,和 Copy 的意思有点类似。
这三种模式之间的间隔也是不固定的。比如,1 次 Minor GC 后,发生了一次并发标记,接着发生了 5 次 Mixed GC或者更多。
1. 年轻代回收
是一个 STW 的过程,它的跨代引用使用 RSet 数据结构来追溯,会一次性回收掉年轻代的所有 Region。
在应用刚启动,流量慢慢的进来了,开始生成对象。G1会选一个分区并指定它为Eden分区,当这块分区用满了之后,G1会选一个新的分区作为Eden分区,这个操作会一直进行下去直到达到Eden分区上限,也就是说Eden分区已经被占满,那么会触发一次年轻代收集.
回收过程:
首先做的就是迁移存活对象,它使用单eden,双survivor进行复制算法,它将存活的对象从eden分区转移到survivor分区,survivor分区内的某些对象达到了任期阈值之后,会晋升到老年代分区中。原有的年轻代分区会被整个回收掉。这里面的存活对象的判定依靠了RSet,当存在有老年代应用新生代的时候,它就会被判定为存活对象。
同时,年轻代收集还负责维护对象年龄,存活对象经历过年轻代收集总次数等信息。G1将晋升对象的尺寸总和和它们的年龄信息维护到年龄表中,结合年龄表、survivor占比(–XX:TargetSurvivorRatio 缺省50%)、最大任期阈值(–XX:MaxTenuringThreshold 缺省为15)来计算出一个合适的任期阈值
这里有个小细节:为什么最大任期阈值为15?
我在网上找到的答案说是:因为采用4bit来保存这个数据,所以最大为15.调优:我们可以通过–XX:MaxGCPauseMillis,调优年轻代收集,缩小暂停时间
最后还会处理 Soft、Weak、Phantom、Final、JNI Weak 等引用。结束收集。
2. 并发标记
当整个堆内存使用达到一定比例(也就是IHOP,默认是 45%),并发标记阶段就会被启动。这个比例也是可以调整的,通过参数 -XX:InitiatingHeapOccupancyPercent 进行配置。
它其实是为了后面的混合收集提供标记服务的,并不是一次 GC 过程的必须环节。
G1的并发标记循环分5个阶段:
- 初始标记
这个过程共用了 年轻代收集的STW暂停,这是因为它们可以复用 Root Scan 操作。虽然是 STW 的,但是时间通常非常短。
- 根区间扫描
标记所有幸存者区间的对象引用
- 并发标记
这个阶段从 GC Roots 开始对堆中的对象标记,标记线程与应用程序线程并行执行,并且收集各个 Region 的存活对象信息。
- 重新标记
标记那些在并发标记阶段发生变化的对象,STW,完成所有标记工作。
- 清除
这个过程不需要 STW。如果发现 Region 里全是垃圾,在这个阶段会立马被清除掉。不全是垃圾的 Region,并不会被立马处理,它会在 Mixed GC 阶段,进行收集。并将回收的Region加入可用Region队列。
调优:
可以通过–XX:InitiatingHeapOccupancyPercent,配置适合应用的IHOP值(过大会可能转移失败,过小可能过早引起并发标记周期);
也可以通过–XX:ConcGCThreads,增加并发线程数。
如果在并发标记阶段,又有新的对象发生了变化,该怎么办?
这个由算法 SATB 保证的。SATB 的全称是 Snapshot At The Beginning,它作用是保证在并发标记阶段的正确性。具体我也没看嘻嘻。
3. 混合回收
当达到IHOP参数并完成上一小节的并发标记周期之后,混合收集周期就开始启动了,它是能并发清理老年代中的整个整个的Region是一种最优情形。混合收集过程,不只清理年轻代,还会将一部分老年代区域也加入到 CSet 中。
混合收集周期包含多次收集次数。那么什么影响收集次数呢?是固定的?还是?有两个参数比较重要:
- -XX:G1MixedGCCountTarget:缺省值为8,意思是能启动混合收集的数目设定一个物理限制。G1根据将回收的老年分区除以该参数值得到每次混合收集的老年代CSet最小数量。
- -XX:G1HeapWastePercent:缺省值为5%,每次混合收集暂停,G1算出废物百分比,根据堆废物百分比,当收集达到参数时,不再启动新的混合收集。因为通过 Concurrent Marking 阶段,我们已经统计了老年代的垃圾占比。在 Minor GC 之后,如果判断这个占比达到了某个阈值,下次就会触发 Mixed GC。因为这种情况下, GC 会花费很多的时间但是回收到的内存却很少。所以这个参数也是可以调整 Mixed GC 的频率的。
调优:当暂停时间和运行时间呈现指数级增长,可以通过-XX:G1HeapWastePercent,调高该参数会有所帮助,但这也导致更多碎片化
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/64688.html

