
文章目录
1. 介绍
当if else过多时,可以通过策略模式来进行重构。先定义一个接口,各else处理分支实现这个接口,并定义 < 条件 , 处理类 > 的映射关系,然后根据条件找到响应的处理类执行即可。
当有新的分支时,只需要新增一个实现类,增加一个映射关系即可。
2. 策略模式结构
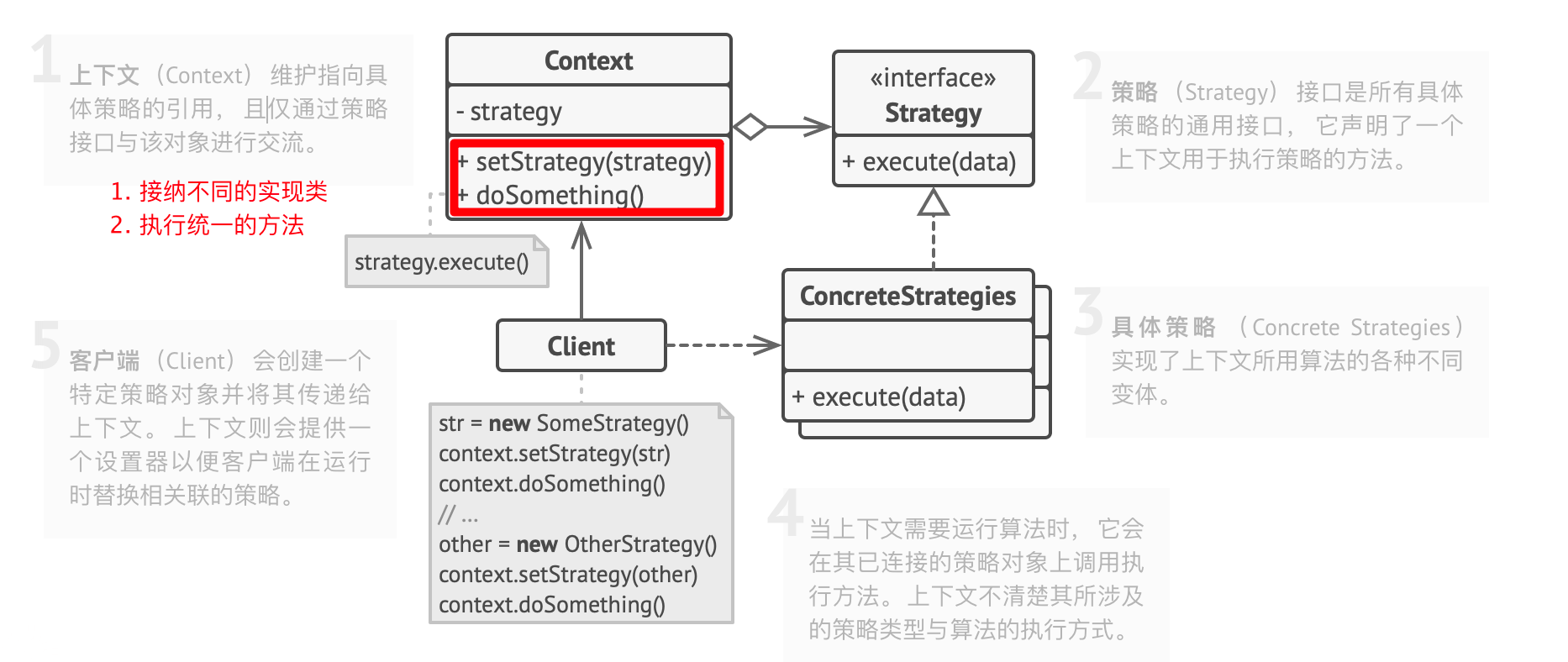

- 策略接口:提供了一个函数式接口,提供了分支逻辑实现的多种方法:匿名类、普通类等
- context类:通过组合策略接口,并执行统一方法,实现面向接口的动态方法。
先来一个官方的伪代码:
策略接口和实现类
// 一个函数式的策略接口
interface Strategy is
method execute(a, b)
// 实现类:实现了+、-、* 算法。
class ConcreteStrategyAdd implements Strategy is
method execute(a, b) is
return a + b
class ConcreteStrategySubtract implements Strategy is
method execute(a, b) is
return a - b
class ConcreteStrategyMultiply implements Strategy is
method execute(a, b) is
return a * b
上下文类的逻辑
class Context is
// 引用策略接口:面向策略
private strategy: Strategy
//传入策略实现类,或者维护一个map
method setStrategy(Strategy strategy) is
this.strategy = strategy
//根据传入的实现类,执行不同的逻辑
method executeStrategy(int a, int b) is
return strategy.execute(a, b)
client
class ExampleApplication is
method main() is
。。。
创建上下文对象
if (action == addition) then
context.setStrategy(new ConcreteStrategyAdd())
if (action == subtraction) then
context.setStrategy(new ConcreteStrategySubtract())
if (action == multiplication) then
context.setStrategy(new ConcreteStrategyMultiply())
result = context.executeStrategy(First number, Second number)
3. 策略模式更一般的用法:工厂类的查表
现在我们知道通过策略模式可以去掉 if-else 分支判断。
更一般的框架,可以根据策略工厂类的逻辑,借助“查表法”(根据 type查表、或字符匹配)来替代根据 type 分支判断。
60 | 策略模式(上):如何避免冗长的if-else/switch分支判断代码?
4. 策略模式使用
4.1. 场景一: 表迁移
有一个需求:项目版本升级(不同版本之间数据表结构不同),需要迁移数据库到新的版本,要求出一个框架,适配项目中所有的数据库的迁移。
- 首先可以使用策略模式,一个表对应一个实现类,通过**类名子串(“t1,t2,t3”)**标识要迁移的表有哪些,然后遍历实例化这些实现类,并放到一个list中,最后遍历这个list,完成某个库的迁移;
- 其次数据迁移涉及到库的连接和库的关闭,所以在创建迁移逻辑之前和迁移之后要维护好这些逻辑,可以统一放到一个context类中。
大致逻辑:
1.策略接口和实现
迁移时的sql逻辑接口
@FunctionalInterface
public interface JdbcDataMigrateFunction {
/**
* 所有迁移和被迁移的表都在一个mysql节点下
*/
void dataMigrate(Connection dbConn, JdbcPros pros);
}
@Log4j2
public class FlinkJobAndInstanceFunction implements JdbcDataMigrateFunction {
...
}
2.context的逻辑
//构造分支的运行逻辑:1. 根据字符串去创建分支逻辑类;2. 分支运行逻辑构建:连接数据库,遍历执行分支逻辑,关闭连接。
public class JdbcTableBuilder {
private JdbcPros jdbcPros;
private JdbcDataMigrateFunction[] jdbcDataMigrateFunctions;
private Connection datalakeDbConn;
public JdbcTableBuilder(String propertiesPath) {
jdbcPros = getJdbcPros(propertiesPath);
String datalakeMigrationTables = jdbcPros.getDatalakeMigrationTables();
String[] datalakeTableNames = datalakeMigrationTables.split(",");
jdbcDataMigrateFunctions = new JdbcDataMigrateFunction[datalakeTableNames.length];
for (int i = 0; i < datalakeTableNames.length; i++) {
jdbcDataMigrateFunctions[i] = createJdbcDataMigrateFunction(datalakeTableNames[i]);
}
}
JdbcDataMigrateFunction createJdbcDataMigrateFunction(String dataflowTableName) {
switch (dataflowTableName) {
case "table1":
return new FlinkJobFunction();
// todo:添加其他表的迁移逻辑
// case ""
// ;
default:
throw new RuntimeException("No logical instance of the table migration could be found");
}
}
//CONTEXT的逻辑
public void runDataMigrate() {
open(jdbcPros);
//run
for (JdbcDataMigrateFunction function : jdbcDataMigrateFunctions) {
function.dataMigrate(datalakeDbConn, dodpDbConn);
}
//close
closeConn();
}
/**
* 1、jdbc链接
*/
public void open(JdbcPros pros) {
try {
DriverManager.getDrivers();
Class.forName(pros.getDrivername());
dodpDbConn = DriverManager.getConnection(
pros.getDodpDbURL(),
pros.getDodpDbUsername(),
pros.getDodpDbPassword());
} catch (SQLException | ClassNotFoundException e) {
e.printStackTrace();
}
}
/**
* 关闭Connection
*/
public void closeConn() {
if (dodpDbConn != null) {
try {
dodpDbConn.close();
} catch (SQLException se) {
} finally {
dodpDbConn = null;
}
}
}
4.2. flink connector类型转换
/** Base class for all converters that convert between JDBC object and Flink internal object. */
public class JdbcRowConverter
extends AbstractRowConverter<
ResultSet, JsonArray, FieldNamedPreparedStatement, LogicalType> {
private static final long serialVersionUID = 1L;
//context逻辑:根据flink sql中字段类型来构建类型转换规则
public JdbcRowConverter(RowType rowType) {
super(rowType);
for (int i = 0; i < rowType.getFieldCount(); i++) {
toInternalConverters.add(
wrapIntoNullableInternalConverter(
createInternalConverter(rowType.getTypeAt(i))));
toExternalConverters.add(
wrapIntoNullableExternalConverter(
createExternalConverter(fieldTypes[i]), fieldTypes[i]));
}
}
@Override
protected ISerializationConverter<FieldNamedPreparedStatement>
wrapIntoNullableExternalConverter(
ISerializationConverter<FieldNamedPreparedStatement> serializationConverter,
LogicalType type) {
final int sqlType =
JdbcTypeUtil.typeInformationToSqlType(
TypeConversions.fromDataTypeToLegacyInfo(
TypeConversions.fromLogicalToDataType(type)));
return (val, index, statement) -> {
if (val == null
|| val.isNullAt(index)
|| LogicalTypeRoot.NULL.equals(type.getTypeRoot())) {
statement.setNull(index, sqlType);
} else {
serializationConverter.serialize(val, index, statement);
}
};
}
//内部转换:将数据转换为flink能进行处理的数据
@Override
public RowData toInternal(ResultSet resultSet) throws Exception {
GenericRowData genericRowData = new GenericRowData(rowType.getFieldCount());
for (int pos = 0; pos < rowType.getFieldCount(); pos++) {
Object field = resultSet.getObject(pos + 1);
genericRowData.setField(pos, toInternalConverters.get(pos).deserialize(field));
}
return genericRowData;
}
@Override
public RowData toInternalLookup(JsonArray jsonArray) throws Exception {
GenericRowData genericRowData = new GenericRowData(rowType.getFieldCount());
for (int pos = 0; pos < rowType.getFieldCount(); pos++) {
Object field = jsonArray.getValue(pos);
genericRowData.setField(pos, toInternalConverters.get(pos).deserialize(field));
}
return genericRowData;
}
//外部数据转换
@Override
public FieldNamedPreparedStatement toExternal(
RowData rowData, FieldNamedPreparedStatement statement) throws Exception {
for (int index = 0; index < rowData.getArity(); index++) {
toExternalConverters.get(index).serialize(rowData, index, statement);
}
return statement;
}
//具体策略的实现类:由flink sql字段名匹配类型转换规则实例
@Override
protected IDeserializationConverter createInternalConverter(LogicalType type) {
switch (type.getTypeRoot()) {
case NULL:
return val -> null;
case BOOLEAN:
case FLOAT:
case DOUBLE:
case INTERVAL_YEAR_MONTH:
case INTERVAL_DAY_TIME:
case INTEGER:
case BIGINT:
return val -> val;
case TINYINT:
return val -> ((Integer) val).byteValue();
case SMALLINT:
// Converter for small type that casts value to int and then return short value,
// since
// JDBC 1.0 use int type for small values.
return val -> val instanceof Integer ? ((Integer) val).shortValue() : val;
case DECIMAL:
final int precision = ((DecimalType) type).getPrecision();
final int scale = ((DecimalType) type).getScale();
// using decimal(20, 0) to support db type bigint unsigned, user should define
// decimal(20, 0) in SQL,
// but other precision like decimal(30, 0) can work too from lenient consideration.
return val ->
val instanceof BigInteger
? DecimalData.fromBigDecimal(
new BigDecimal((BigInteger) val, 0), precision, scale)
: DecimalData.fromBigDecimal((BigDecimal) val, precision, scale);
case DATE:
return val ->
(int) ((Date.valueOf(String.valueOf(val))).toLocalDate().toEpochDay());
case TIME_WITHOUT_TIME_ZONE:
return val ->
(int)
((Time.valueOf(String.valueOf(val))).toLocalTime().toNanoOfDay()
/ 1_000_000L);
case TIMESTAMP_WITH_TIME_ZONE:
case TIMESTAMP_WITHOUT_TIME_ZONE:
return val -> TimestampData.fromTimestamp((Timestamp) val);
case CHAR:
case VARCHAR:
return val -> StringData.fromString(val.toString());
case BINARY:
case VARBINARY:
return val -> (byte[]) val;
case ARRAY:
case ROW:
case MAP:
case MULTISET:
case RAW:
default:
throw new UnsupportedOperationException("Unsupported type:" + type);
}
}
@Override
protected ISerializationConverter<FieldNamedPreparedStatement> createExternalConverter(
LogicalType type) {
switch (type.getTypeRoot()) {
case BOOLEAN:
return (val, index, statement) ->
statement.setBoolean(index, val.getBoolean(index));
case TINYINT:
return (val, index, statement) -> statement.setByte(index, val.getByte(index));
case SMALLINT:
return (val, index, statement) -> statement.setShort(index, val.getShort(index));
case INTEGER:
case INTERVAL_YEAR_MONTH:
return (val, index, statement) -> statement.setInt(index, val.getInt(index));
case BIGINT:
case INTERVAL_DAY_TIME:
return (val, index, statement) -> statement.setLong(index, val.getLong(index));
case FLOAT:
return (val, index, statement) -> statement.setFloat(index, val.getFloat(index));
case DOUBLE:
return (val, index, statement) -> statement.setDouble(index, val.getDouble(index));
case CHAR:
case VARCHAR:
// value is BinaryString
return (val, index, statement) ->
statement.setString(index, val.getString(index).toString());
case BINARY:
case VARBINARY:
return (val, index, statement) -> statement.setBytes(index, val.getBinary(index));
case DATE:
return (val, index, statement) ->
statement.setDate(
index, Date.valueOf(LocalDate.ofEpochDay(val.getInt(index))));
case TIME_WITHOUT_TIME_ZONE:
return (val, index, statement) ->
statement.setTime(
index,
Time.valueOf(
LocalTime.ofNanoOfDay(val.getInt(index) * 1_000_000L)));
case TIMESTAMP_WITH_TIME_ZONE:
case TIMESTAMP_WITHOUT_TIME_ZONE:
final int timestampPrecision = ((TimestampType) type).getPrecision();
return (val, index, statement) ->
statement.setTimestamp(
index, val.getTimestamp(index, timestampPrecision).toTimestamp());
case DECIMAL:
final int decimalPrecision = ((DecimalType) type).getPrecision();
final int decimalScale = ((DecimalType) type).getScale();
return (val, index, statement) ->
statement.setBigDecimal(
index,
val.getDecimal(index, decimalPrecision, decimalScale)
.toBigDecimal());
case ARRAY:
case MAP:
case MULTISET:
case ROW:
case RAW:
default:
throw new UnsupportedOperationException("Unsupported type:" + type);
}
}
}
4.3. spring bean ing
将if else 变成spring bean的名字去拿到bean,这个bean是通过一个抽象接口实现的。
参考:
策略模式
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/65328.html

