
一. 累加器:
1.概述
获取全局唯一状态的对象。Driver和Executor之间共享变量,即Executor的计算结果可以返回到Driver中继续使用。全局级别:无论是哪个Task,修改的都是此累加器。
使用:
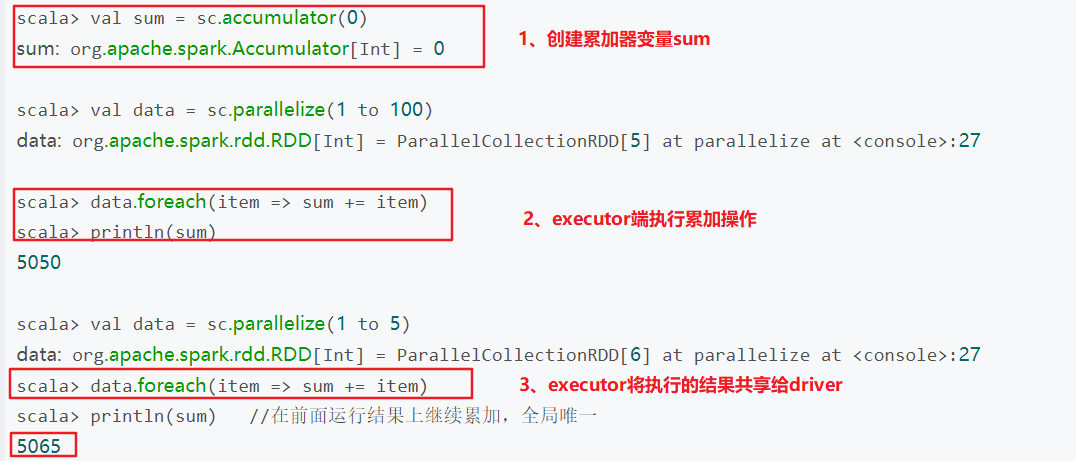

对于Executor来说,只能修改(增加)累加器的内容,不能读,只对Driver可读。
累加器是全局唯一的,每次操作只增不减。
2. 自定义累加器
case class PersonInfo(var personNum: Int, var ageSum: Int)
class MyAccumulator extends AccumulatorV2[PersonInfo, PersonInfo] {
//给Driver端的初始值,累加器是在此基础上进行累加的
private var info = PersonInfo(0, 0)
//每个分区的累加器是否有初始值,要和reset方法保持一致
override def isZero: Boolean = info.personNum == 0 && info.ageSum == 0
//复制一个新的累加器
override def copy(): AccumulatorV2[PersonInfo, PersonInfo] = {
val acc = new MyAccumulator()
acc.info = info
acc
}
//reset初始值
override def reset(): Unit = {
info=PersonInfo(0,0)
}
//(各RDD分区内各自)累加
override def add(v: PersonInfo): Unit = {
info.personNum += v.personNum
info.ageSum += v.ageSum
}
//(将每个分区的结果,)合并到Driver端
override def merge(other: AccumulatorV2[PersonInfo, PersonInfo]): Unit = {
val ac = other.asInstanceOf[MyAccumulator]
info.personNum += ac.info.personNum
info.ageSum += ac.info.ageSum
}
//累加器在Driver端最终返回的结果
override def value: PersonInfo = info
}
object SelfAccumulatorTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("acc")
val sc = new SparkContext(conf)
val acc = new MyAccumulator()
sc.register(acc)
val list = sc.parallelize(Array[String]("a 1", "b 2", "c 3", "d 4", "e 5", "f 6"), 3)
list.map(line => {
val age = line.split(" ")(1).toInt
acc.add(PersonInfo(1, age))
line
}).collect()
println(s"结果:${acc.value}")
}
二. 广播变量
分布式只读共享变量
1. 概述
背景:
每个Task在运行时都会拷贝一份数据副本,更好的保证了数据一致性,但是消耗大量内存,当数据量很大时,极易出现内存溢出(OOM)。
概念:
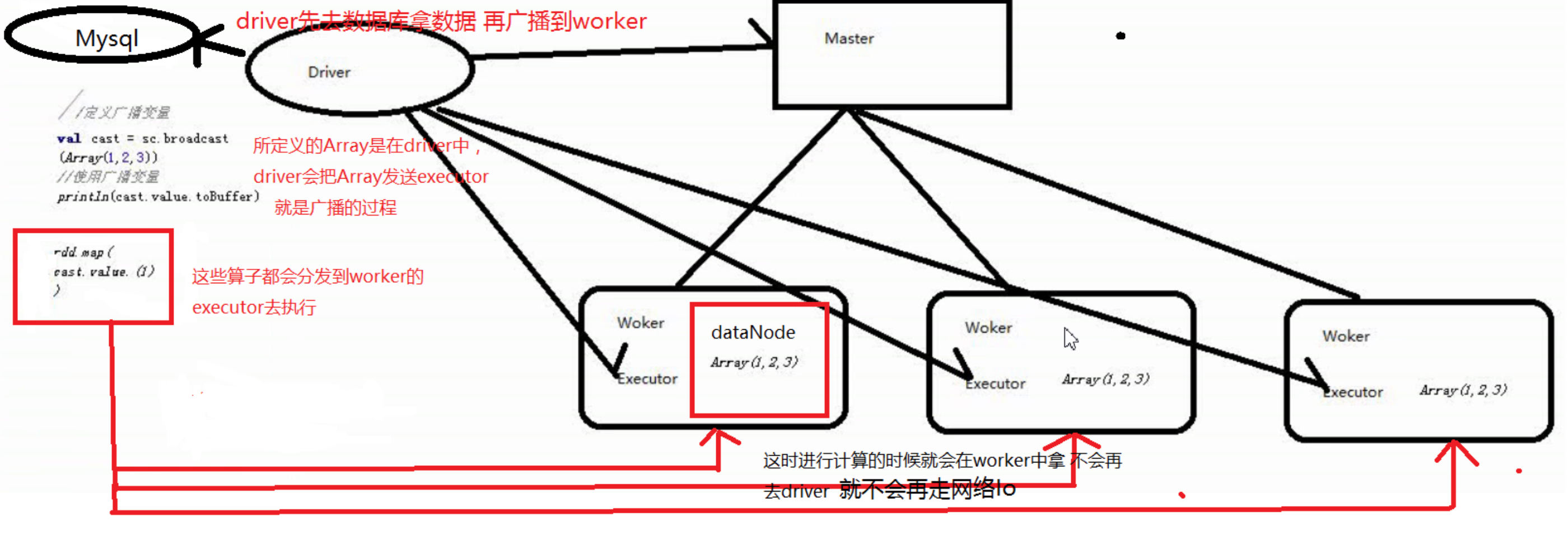
广播变量允许保留一个只读的变量缓存在每台机器上,而不是每个task上。
广播变量是由Driver发给当前Application分配的所有Executor(进程节点)内存级别的全局只读变量,Executor中线程池的线程共享该全局变量。
变量只会被发到各个节点一次,应作为只读值处理(修改这个值不会影响到别的节点)。
优点:
减少了网络传输(否则的话每个Task都要传输一次该变量,极大地节省了内存,提高CPU地有效工作。
使用
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
scala> broadcastVar.value
res33: Array[Int] = Array(1, 2, 3)
参考:
Spark自定义累加器
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/65341.html

