
通过了解spark整体的算子,知道spark的RDD能够提供哪些数据处理的功能,以及掌握如何使用。
文章目录
在 Spark Core中,RDD支持 2 种操作:
- transformation算子:从一个已知的 RDD 中创建出来一个新的 RDD 。
- action算子:触发SparkContext提交Job作业
算子整体上分为Value类型和Key-Value类型,
value类型的算子针对处理value类型的数据,而key-value类型用于处理数据是<key,value>类型的。
接下来的篇章我们会介绍不同类型的算子,本文介绍trans算子中value类型的算子使用。
1. 算子分类概述
1、 (输入与输出分区)一对一
map(func): 一条数据调用一次
mapPartitions(func):功能类似于map,但是一个分区的数据调用一次
glom(func):将每一个分区的数据形成一个数组
sortBy(func,[ascending], [numTasks]) :根据处理后的数据比较结果排序,默认为正序。
2、一对多
flatMap(func) :对每一条数据操作,每次都返回一个序列
3、(输入分区与输出分区)多对一型
union(otherDataset): 源RDD和参数RDD求并集后返回一个新的RDD
subtract(otherDataset):取差,去除两个RDD中相同的元素,不同的源RDD将保留下来
intersection(otherDataset):交集后返回一个新的RDD
zip(otherDataset):将两个RDD组合成Key/Value形式的RDD,这里默认两个RDD的partition数量以及元素数量都相同,否则会抛出异常。
4、(输入分区与输出分区)多对多
grouBy(func):分组,按照传入函数的返回值进行分组。将相同返回值的对应值放入一个迭代器。
5、输出是输入的子集
filter(func):根据func的逻辑去过滤数据,func返回为true的元素留下
distinct([numTasks])):去重,经历了shuffle。默认情况下并行度为8。可选参数:可以设置来改变分区数,即储存的文件数量。
sample(withReplacement, fraction, seed): withReplacement:抽取的元素是否放回;true:放回
fraction:每个元素被选择的概率(也可所有元素抽取的比例)
seed:用于指定随机数生成器种子
6、Cache型
cache()
persist算子
2. 常见算子使用举例
map
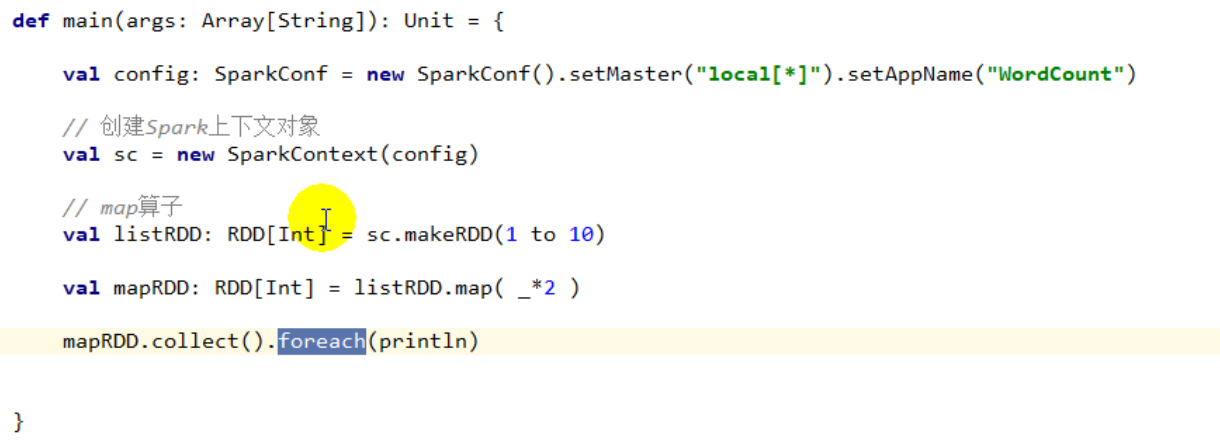

mapPartitions(func)
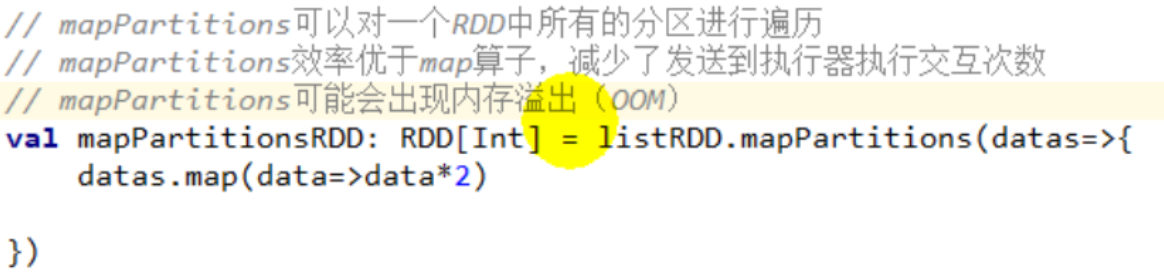
glom
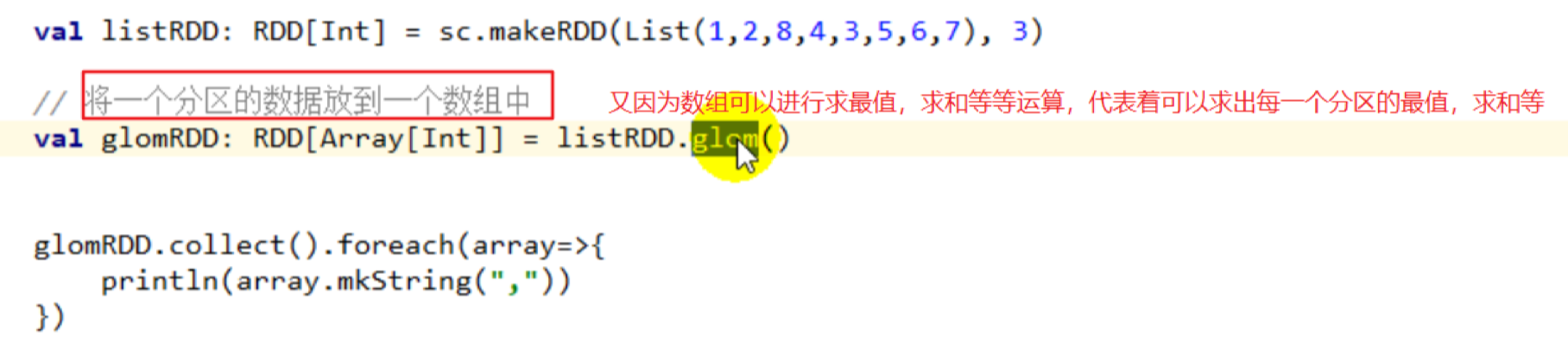
distinct()

coalesce(numPartitions)
缩减分区数,用于大数据集过滤后,提高小数据集的执行效率。
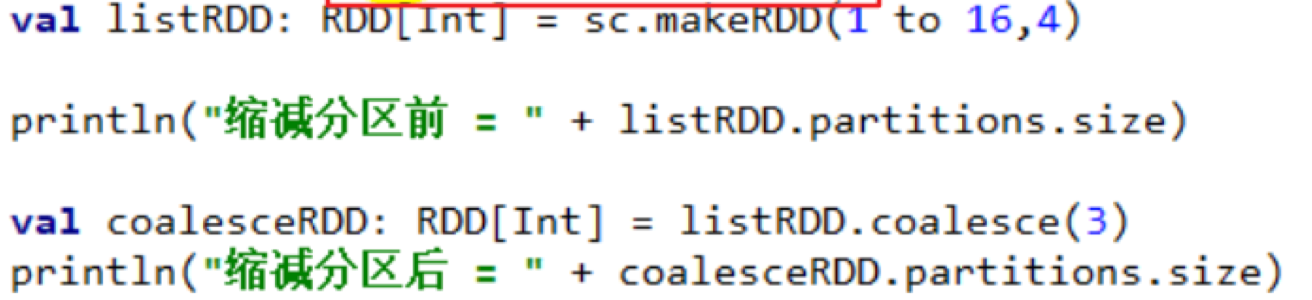
coalesce和repartition的区别
coalesce重新分区,可以选择是否进行shuffle过程。由参数shuffle: Boolean = false/true决定。
repartition实际上是调用的coalesce,默认是进行shuffle的。
源码如下:
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/65344.html

