
通过了解RDD的概念、特点、以及以一个scala程序快速认识RDD。
一. 概述
1. 定义
RDD(Resilient Distributed Dataset)是弹性的、分布式数据集是Spark中最基本的计算过程的抽象。
弹性的体现
- 基于血缘的高效容错;task和stage的失败重试,且只会重新计算失败的分片
- checkpoint、persist数据持久化,对数据进行复用。
- 数据分片的高度弹性repartion
2. 特点
a. 分区性
- rdd上的数据可以划分为几个独立的子集(分区),进行并行计算。 每一个分区都会被一个计算任务处理,即分区数==并行数
- 对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。默认情况下,一个HDFS上的数据分片就是一个 partition。即spark的并行度取决于hadoop的分片策略。
默认情况下,不指定分区数量:
a. 从HDFS文件创建,默认为文件的 Block数
b. 从集合创建时,则默认分区数量为该程序所分配到的资源的CPU核数(每个Core可以承载2~4个 partition)
b. 每一个分区(分片)都有一个计算函数
计算的时候会通过一个compute函数得到每个分区的数据
c.RDD之间的依赖性
- 一个job下的各RDD函数之间的联系称为血缘
- 数据容灾:部分分区数据丢失时,通过血缘可以重新计算丢失的分区数据,而不是所有分区重新计算
d.(可选)划分策略
如果RDD里面存的数据是key-value形式,则可以传递一个自定义的Partitioner进行重新分区
f.(可选)每个分区都有一个优先位置列表
优先位置列表会存储每个Partition的优先位置,对于一个HDFS文件来说,就是每个Partition块的位置。 在计算之前优先把作业调度到数据所在节点。
3. RDD分类
Spark中的所有的RDD方法都称之为算子,但是分为2大类:转换算子和行动算子
a. Transformation(转换)算子:
Transformation属于延迟计算,当一个RDD转换成另一个RDD时并没有立即进行转换,仅仅是记住了数据集的逻辑操作。
b. Action(执行)算子 :
触发Spark作业的运行,真正触发转换算子的计算
控制算子: cache和persist
二. RDD任务划分
Application(应用):初始化一个SparkContext即生成一个Application
Job(作业):一个Action算子就会生成一个Job。那也就是说,一个application可能有多个job。
Stage(阶段): 根据RDD之间的依赖关系的不同将一个Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage。其中Stage是一个TaskSet(任务集)。
Task(任务)
a. task:任务的执行单元;一个task会在一个executor中执行
b.一个stage中的Task数取决于Stage中最后RDD的分区数
c. Task分为
- ResultTask:DAG的最后一个阶段会为每个结果的partition生成一个ResultTask;
- ShuffleMapTask:其余所有阶段都会生成ShuffleMapTask。之所以称之为ShuffleMapTask是因为它需要将自己的计算结果通过shuffle到下一个stage
DAG
DAG是:点与点之间有方向的连接,但是没有形成环状的图
一个Spark应用程序提交时,DAGScheduler从action算子从后往前遍历,遇到一个shuffle算子就切断,形成一个stage,并放入栈内(先进后出),知道便利到第一个算子。
款依赖和窄依赖
窄依赖: 父RDD的partition最多被子RDD的一个Partition使用
宽依赖:
当上游所有算子计算的结果都需要最终聚合到一个节点算子上计算时,此时需要shuffle,也是宽依赖的出现的原因。
RDD运行特点:父RDD处理完成之后,才能进行接下来的计算
shuffle持久化的原因
1. shuflle不落地可能造成内存溢出
2. 当某个分区丢失时需要重新计算所有父分区的数据
job到task的对应关系
Application -> Job -> Stage -> Task每一层都是1对n的关系。
血缘
血缘记录着RDD的元数据信息(数据源的位置、类型)和转换行为。
容错:当RDD的部分分区数据丢失时,可以根据血缘重新计算来恢复这些数据。
血缘的查看:
toDebugString:展示了每一步的操作并且保存了文件读取的位置,转换规则等
dependencies:展示与上一个操作的依赖

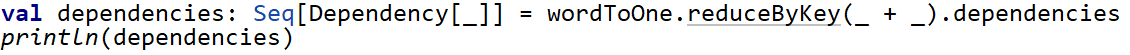
三. hello spark
//1.1、设置Spark计算框架(部署)环境
val config:SparkConf = new SparkConf().setMaster("local[*]").setAppName("WC")
//1.2、创建Spark上下文对象
val sc = new SparkContext(config)
//2.1、创建
val listRDD = sc.makeRDD(List(1, 2, 3, 4))
//2.2、执行action算子
listRDD.collect().foreach(println)
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/65345.html

