
开始
不负众望,早上说好的更新b站新番排行top50的我,现在来履行承诺了,本文有一些的知识点,比如bs4和selenium,因为b站的新番榜的图片是js渲染得来的,所以必须要使用selenium来实现滑动滚轮,再获取数据,所以requests就不需要啦!
爬虫项目实战(初学推荐!)
本次爬虫可能会对初学者有一些些的难度,所以没看过我之前的进阶视频的不妨看一下,看完之后再来看本视频会学到很多的知识!
豆瓣爬虫实战
python爬取豆瓣top前10(初阶)
链接:https://blog.csdn.net/weixin_45859193/article/details/107064009
python爬取豆瓣top排行250(中阶)
链接:https://blog.csdn.net/weixin_45859193/article/details/107772556
python爬取豆瓣高评分(进阶)
链接https://blog.csdn.net/weixin_45859193/article/details/107752833
b站爬虫实战
python之数据分析可视化
链接https://blog.csdn.net/weixin_45859193/article/details/107525767
python爬取b站弹幕和统计
链接https://blog.csdn.net/weixin_45859193/article/details/107418453
python爬取b站高追番榜图片
链接:https://blog.csdn.net/weixin_45859193/article/details/107784513
当你学完这些案例,差不多你也可以自己去爬取一些其他的网站了,也可以更好的理解本节课的代码是什么意思了!
selenium爬虫常用方法
想看其他方法的不妨点一下上面的链接,有很多介绍xpath,jsonpath等等的方法,有兴趣的可以看,这里就不解释了!
selenium用法

当然定位操作不止id,有很多种class_name,text,xpath…很多这里不用就不详解了!
selenium滑动滚动条方法
#将滚动条移动到页面的底部
js="var q=document.documentElement.scrollTop=100000"
driver.execute_script(js)
time.sleep(3)
#将滚动条移动到页面的顶部
js="var q=document.documentElement.scrollTop=0"
driver.execute_script(js)
time.sleep(3)
#若要对页面中的内嵌窗口中的滚动条进行操作,要先定位到该内嵌窗口,在进行滚动条操作
js="var q=document.getElementById('id').scrollTop=100000"
driver.execute_script(js)
注!(本次使用的selenium需要下载插件和响应版本下载,如有需求请点开下面的链接)
selenium安装+chrome浏览器测试版下载+符合版本下载:https://blog.csdn.net/weixin_45859193/article/details/107796812
代码块
代码注释很多,看不懂的可以多看注释
import bs4
import os
from urllib.request import urlretrieve
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get('https://www.bilibili.com/ranking/bangumi/13/0/3')
time.sleep(2)
#将滚动条移动到页面的底部
for i in range(200,10000,20):
js = "var q=document.documentElement.scrollTop={}".format(i)
driver.execute_script(js)
#延迟3秒让页面加载完成
time.sleep(3)
#获取了页面全部源码
response=driver.page_source
#退出
driver.quit()
soup=bs4.BeautifulSoup(response,'html.parser')
link_list = soup.find_all("div", class_="lazy-img cover")
i=0
#文件名
text='b站新番榜单图片'
#判断文件夹是否存在
if not os.path.exists(text):
os.mkdir(text)
#保存数据
for link in link_list:
#链接
links= link.img['src'].split('@',-1)[0]
#名字
name=link.img['alt']
i+=1
#清楚一些冲突数据
urlretrieve(links,text+'/'+(str(i)+(name.replace(':',' '))\
.split('/')[0])+'.jpg')
print(name+'100%')
最后
奉上图片!
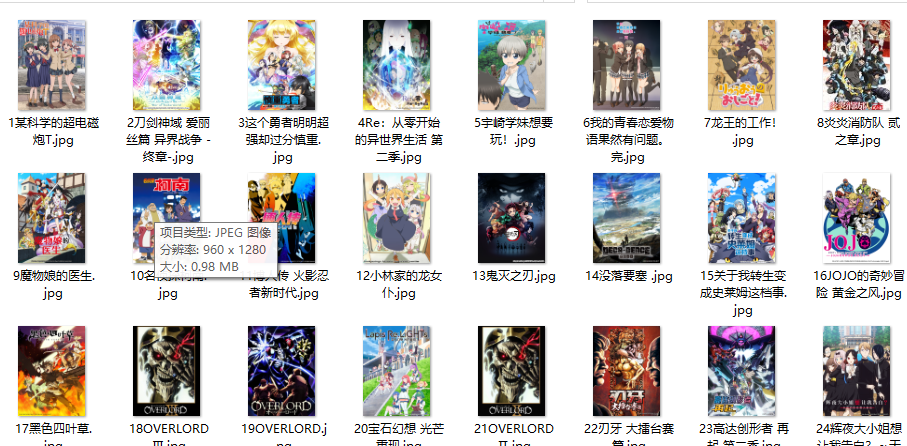
顺便给喜欢看番的绅士们推荐这个动漫 = . =

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/66867.html

![FastDFS报错 fdfs_client.exceptions.DataError: [-] Error: 28, No space left on device的解决方法](https://www.bmabk.com/wp-content/uploads/2022/05/post-loading-480x300.gif)