
前言
本次是爬取豆瓣高评分的榜单,爬多少可以自己调整,这次代码就跑个300个图片就够了!,如果想更深刻的了解爬虫,或是初学爬虫的,不妨可以先看看此链接:https://blog.csdn.net/weixin_45859193/article/details/107064009
先从简单的开始,再到难的,先了解思路再进行下一步的进阶!
requests库和jsonpath库
本文主要用到的这2种库这里给大家图片参考一下吧!
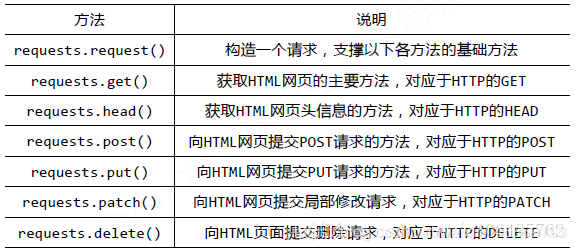
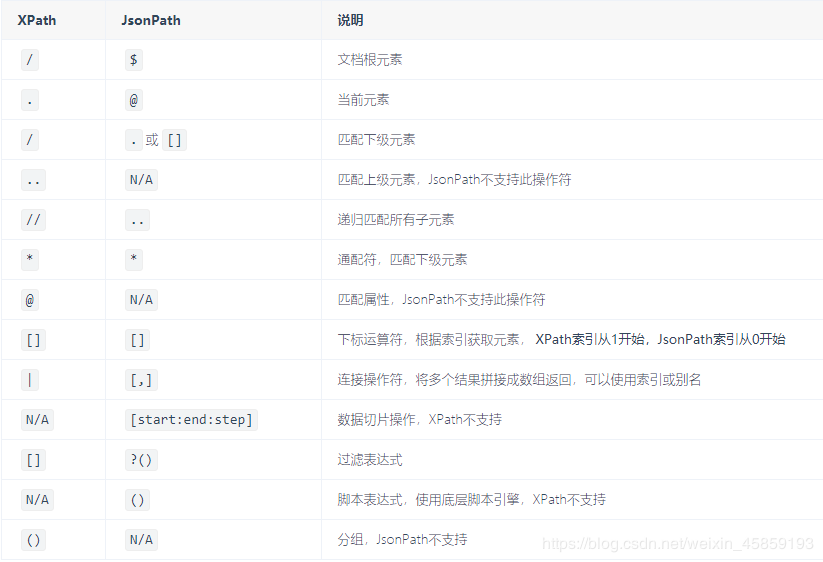
顺便也把xpath也列出来吧!
爬虫的四大步骤
1.目标url 网站
2.发送请求
3.解析数据
4.保存数据
在我的博客也说了很多次这四大步骤了,不过我认为真的很重要,因为不管什么爬虫都是围绕着这四步走的!
代码块
代码有很多注释,也比较简单,适合进阶爬虫学习,有不懂的可以参考注释和上面的图片,或链接进行学习,那么就直接上代码吧!
import requests
import jsonpath
from urllib.request import urlretrieve
import os
import time
def url_list(id):
#目标url
url = 'https://movie.douban.com/j/search_subjects?type=movie&tag=%E8%B1%86%E7%93%A3%E9%AB%98%E5%88%86&sort=recommend&page_limit=20&page_start={}'.format(id)
#模拟浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'}
#发送请求,解析json数据
req = requests.get(url, headers=headers).json()
#查找图片和名字
data_list = jsonpath.jsonpath(req, '$..cover')
name_list = jsonpath.jsonpath(req, '$..title')
#返回数据
return (data_list,name_list)
#文件夹名
text='豆瓣高评分图片'
#判断文件夹是否创建
if not os.path.exists(text):
os.mkdir(text)
#这里我只要300张图片
for i in range(0,320,20):
#获取图片链接
link_list,names = url_list(i)
#保存数据
for link,name in zip(link_list,names):
#防止报错
try:
#到哪个链接查找,然后是哪个文件夹和里面的名字,后缀是.什么的格式
urlretrieve(link,text+'/'+name+'.jpg')
#打印成功
print(name+'100%')
except:
pass
#延迟2秒
time.sleep(2)
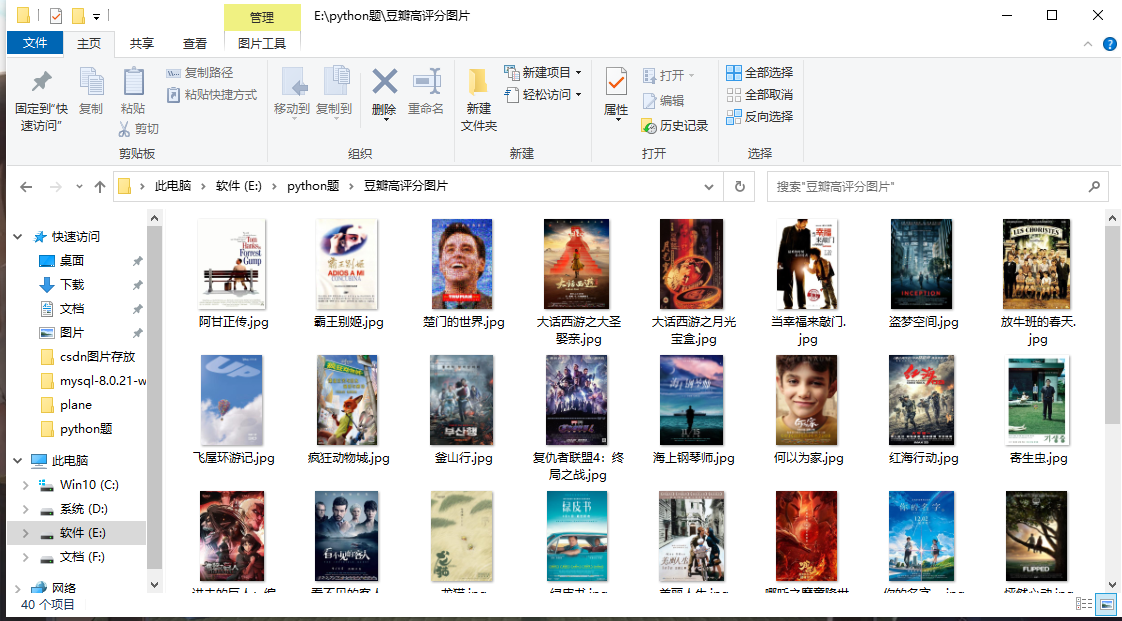
效果
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/66870.html

