
前言
又是一个宁静的晚上,看到同学们聊的新闻如此的开心,有说有笑的,我仿佛像个空气一样找不到话题,只能默默的看着他们聊天,然后一起笑,一起害怕,因为我是一个不怎么看新闻的人,所以他们说什么我都不知道啊!!!,所以我决定要爬取新闻然后可以全部看完,这样就能和我的朋友有说有笑,不用愁眉苦脸的看着他们啦!(好多四字成语,语文老师欣慰的点了点头…)
xpath工具和requests
本代码所用的工具就着2个,比较简单,不是很复杂,就是清洗数据有点麻烦,想了解xpath和下载xpath的可以点开此链接下载:https://blog.csdn.net/weixin_45859193/article/details/107064009
(此链接还有一个简单的实战操作,可以练手掌握)
步骤
其实这个想法之前就有想过,也尝试了,不过那时,我比较菜,也就知道抓包,js数据和用xpath工具解析数据,所以导致那时我用requests是什么获取不到我想要的数据的,最后在不断努力的抓包的过程中和查找源代码的过程中,我看到了这个数据

仔细观察可以看出这个有点像python里的字典啊,所以好办了,可以用requests解析数据看看是怎么样
(最后果然发现是可以转换为字典的,只要清洗一下数据就ok啦!)

爬虫的四大步骤
1.获取url
2.发送请求
3.解析数据,并清洗数据
4.保存数据
不管是什么网页都离不开的四大步骤,所以我们围绕着这四步走!
所以我们可以一步一步的上代码来看看是不是这样的!
思路
第一步获取url地址
#这是第一层的url
url='http://ent.sina.com.cn/hotnews/ent/Daily/'
第二步发送请求
#模拟浏览器
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.69 Safari/537.36'}
#发送请求
response=requests.get(url,headers=headers).content.decode()
第三步解析数据,并清洗数据
#解析成xpath能识别数据
html=etree.HTML(response)
#获取php链接,清洗数据
url_list=html.xpath('//script/@src')
url_link=url_list[1]
#获取到了链接
url_link='http:'+url_link
#获取到了新链接是不是还要继续按照上面的四大步骤去走,这里就不详解,都是一样的
response=requests.get(url_link,headers=headers).content.decode()
# #清洗数据
response=response.split('[')[-1]
response=response.split(']',-1)[0]
#转型
response=eval(response)
第四步保存清洗后的数据
#文件名
file_name='娱乐新闻.txt'
for req in response:
#防止报错
try:
# 标题
data = req['title']
#这里不要组图的标题,没有内容,是图片,我们要的是新闻
if re.findall('(.*?):', req['title']) == ['组图']or re.findall('(.*?):', req['title']) == ['组图']:
continue
#拼合,清洗数据,原谅我不会正则
link = req['url'].replace('\\', '//')
link = link.split('', 1)
#这是我们想要的链接
link = link[0] + link[1]
res = requests.get(link, headers=headers).content.decode()
html = etree.HTML(res)
#判断链接后缀有没有/有的话要用另一个xpath工具来获取
if link.split('//',-1)[-1]== '/':
#清洗文本数据
text='\n'.join(html.xpath('//div[@id="cont_0"]//p/text()')).strip('\n').replace('\u3000',' ')
else:
text='\n'.join(html.xpath('//div[@class="article"]//p//text()')).strip('\n').replace('\u3000',' ')
#保存数据
with open(file_name,'a+',encoding='utf-8') as f:
# 标题写入
f.write('------------'+''.join(data)+'------------\n')
#正文写入
f.write(text+'\n\n')#换行
print(''.join(data)+'--提取成功')
except:
pass
是不是按照这四步走,发现其实并不是很难!
代码
import requests
from lxml import etree
from urllib.request import urlretrieve
import re
import json
#url='http:'+'//top.ent.sina.com.cn/ws/GetTopDataList.php?top_type=day&top_cat=ent_suda&top_time=20200802&top_show_num=20&top_order=DESC&js_var=all_1_data'
#第一层url,用来获取php的链接
url='http://ent.sina.com.cn/hotnews/ent/Daily/'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.69 Safari/537.36'}
name_data=input('请问您想要的数据是什么数据(默认娱乐新闻)\n0.默认 1.其他')
if name_data == '1':
url_1=input('请输入你想获取其他新闻的url')
url=url_1
response=requests.get(url,headers=headers).content.decode()
html=etree.HTML(response)
#获取php链接,清洗数据
url_list=html.xpath('//script/@src')
url_link=url_list[1]
#获取到了链接
if name_data !='1':
url_link='http:'+url_link
response=requests.get(url_link,headers=headers).content.decode()
# #清洗数据,本人不太会正则= =
response=response.split('[')[-1]
response=response.split(']',-1)[0]
#转型
response=eval(response)
#定义文件名
file_name='娱乐新闻.txt'
for req in response:
try:
# 标题
data = req['title']
#这里不要组图的标题,没有内容,是图片,我们要的是新闻
if re.findall('(.*?):', req['title']) == ['组图']or re.findall('(.*?):', req['title']) == ['组图']:
continue
#拼合,清洗数据,原谅我不会正则
link = req['url'].replace('\\', '//')
link = link.split('', 1)
#这是我们想要的链接
link = link[0] + link[1]
res = requests.get(link, headers=headers).content.decode()
html = etree.HTML(res)
#判断链接后缀有没有/有的话要用另一个xpath工具来获取
if link.split('//',-1)[-1]== '/':
#清洗文本数据
text='\n'.join(html.xpath('//div[@id="cont_0"]//p/text()')).strip('\n').replace('\u3000',' ')
else:
text='\n'.join(html.xpath('//div[@class="article"]//p//text()')).strip('\n').replace('\u3000',' ')
#保存数据
with open(file_name,'a+',encoding='utf-8') as f:
# 标题写入
f.write('------------'+''.join(data)+'------------\n')
#正文写入
f.write(text+'\n\n')#换行
print(''.join(data)+'--提取成功')
except:
pass
效果
注:我爬取的是娱乐新闻,如果想爬其他的可以更改第一层的url地址(亲测有效的不过,只是在这些地方测试过,比如,其他的地方没试过)
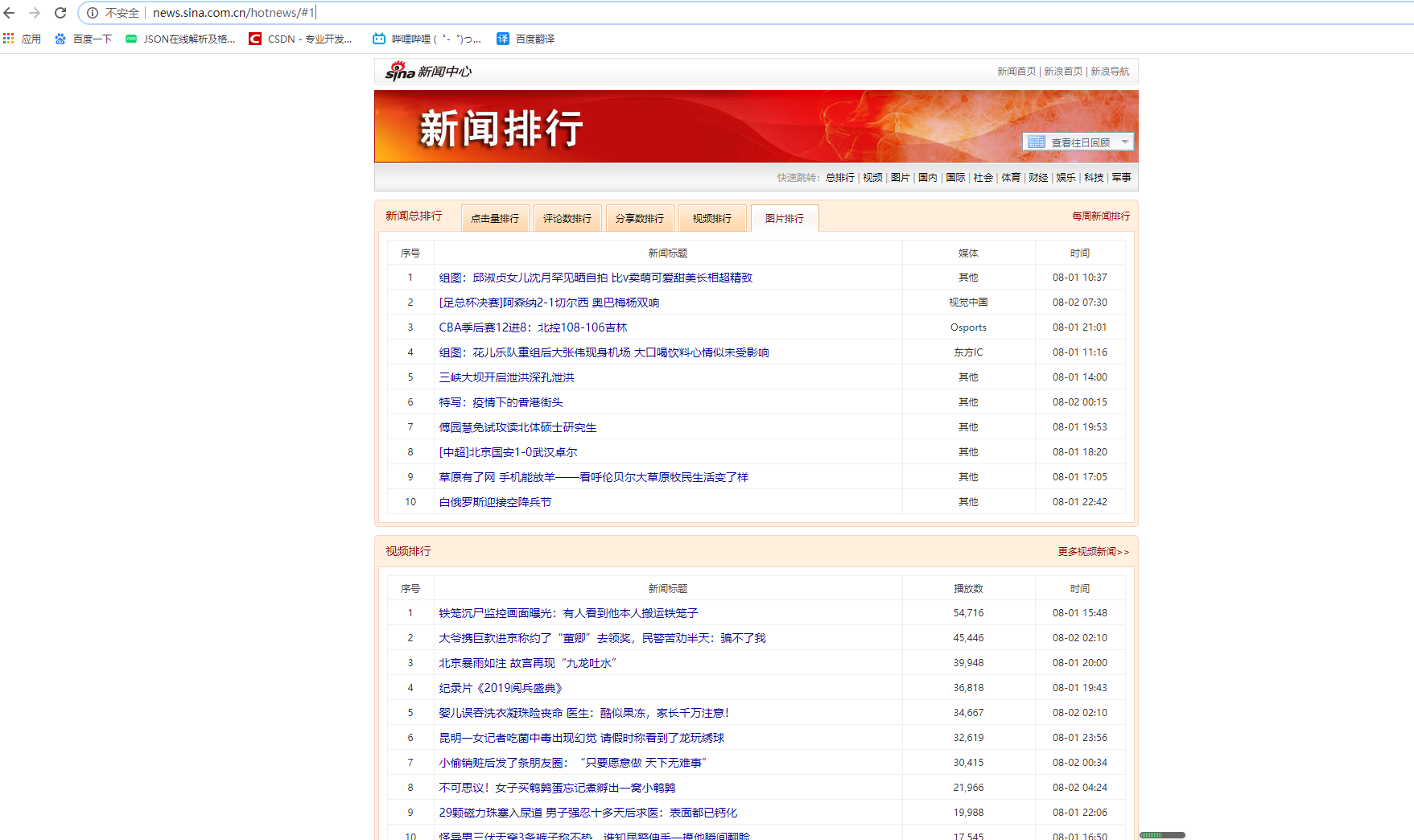
其他地方没试过,如果有更好的建议,欢迎大佬指点改进
最终效果
其他效果

默认效果

文本效果

总结
不忘初心,方得始终!
温馨提示:大家尽量不要熬夜啊,身体要紧!!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/66871.html

