
关于
看了很久的斗鱼主播图片,我的欲望也欲来不满,望着他隔壁家的虎牙,我的心开始动摇,最后,我忍不住点开了看,发现了新鲜的图片,人就是如此,祖传手艺岂可落下,于是我开始爬取虎牙的图片…
想看斗鱼的指定爬取图片可以点开此链接:https://blog.csdn.net/weixin_45859193/article/details/107081107
起初
我天真的以为斗鱼和虎牙设计网页的模式是一样的,所以我点开了js解析找到了一个比较类似网页链接:
https://search.cdn.huya.com/?callback=jQuery1111024704760784583946_1595034973844&m=Search&do=getSearchContent&q=%E8%8B%B1%E9%9B%84%E8%81%94%E7%9B%9F&uid=0&v=4&typ=-5&livestate=0&rows=16&_=1595034973845

发现加粗的字体是关键字,但是当我搜美女的时候却发现里面是把美女当成关键字去搜索,并不是我想要的图片,我也看不懂里面是什么东西,虽然能找到链接,大概知道的样子(说白就是不知道= =)…
于是只能用另一个方法
Xpath工具
本文会用到xpath工具如果有不懂也可以点开斗鱼链接去查看,里面有详解
没有下载的可以再次链接下载:https://pan.baidu.com/s/1GXPm1kMENXhOkefKcEQnlA
提取码:8wwv
步骤
1.url地址
2.发送请求
3.解析数据
4.保存数据
所以我第一步要做的是先点开虎牙直播的分类找到他的url地址,然后分类
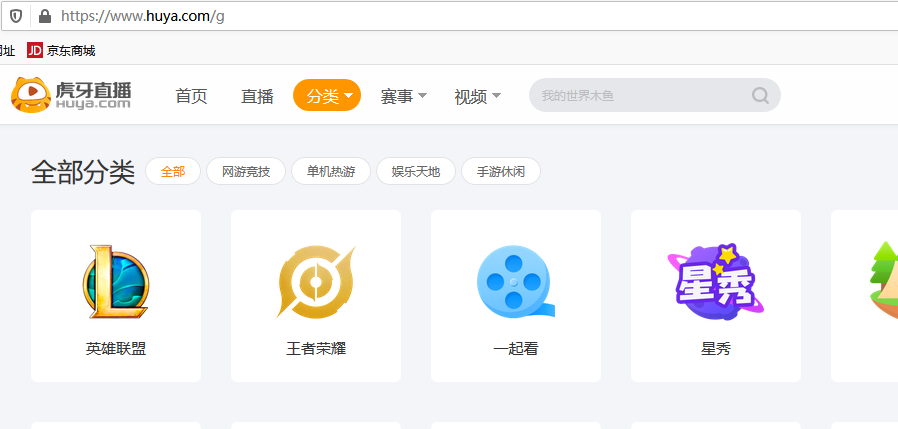
发现他的分类的url是:https://www.huya.com/g,这是第一层,然后随便点一个颜值的进去看看
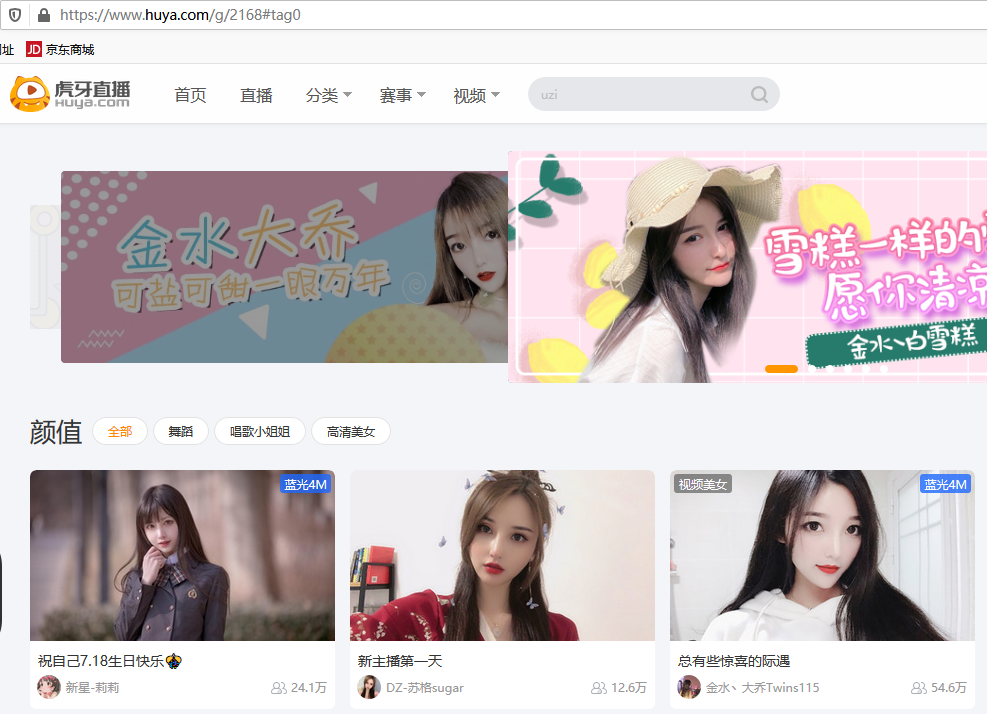 这一层的url是:https://www.huya.com/g/2168,不过点开全部会出现#tag0,我们是要全部图片所以加上去,看到了2168这个奇怪的数字,不过如果我想指定的话,是不能打颜值这2个字的,因为找不到,所以我们要返回上一层url先获取他的id号,和关键字…
这一层的url是:https://www.huya.com/g/2168,不过点开全部会出现#tag0,我们是要全部图片所以加上去,看到了2168这个奇怪的数字,不过如果我想指定的话,是不能打颜值这2个字的,因为找不到,所以我们要返回上一层url先获取他的id号,和关键字…

 获得了这2个我们是不是能在输入一个数的时候来个循环判断查找,找到把id带上退出第一层url,去第二层url地址,没找到继续找,没有这个数就显示没有,那么是不是为了让我们能知道关键字id,是不是要再把这里面的id和关键字保存到一个记事本,方便查看…
获得了这2个我们是不是能在输入一个数的时候来个循环判断查找,找到把id带上退出第一层url,去第二层url地址,没找到继续找,没有这个数就显示没有,那么是不是为了让我们能知道关键字id,是不是要再把这里面的id和关键字保存到一个记事本,方便查看…
代码
代码有注释,不懂的可以去看看上面的步骤
import requests
from lxml import etree
import os
from urllib.request import urlretrieve
import sys
url='https://www.huya.com/g'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36'}
response=requests.get(url,headers=headers).content.decode()
html=etree.HTML(response)
req=html.xpath('//li[@class="g-gameCard-item"]//a//@data-gid')
names=html.xpath('//li[@class="g-gameCard-item"]//a//p/text()')
i=0
mylog=open('关键字大全.log',mode='a',encoding='utf-8')
print(' -----------查找关键字大全-----------',file=mylog)
#这里只是为了查看关键字美观而已,保存到记事本里
for re,name in zip(req,names):
print('关键字:%s 查找id号:%s'%(name,re),end=' ',file=mylog)
i+=1
if i==5:
print('\n',file=mylog)
i=0
mylog.close()
name_1=input('\n请输入查找关键字:')
for re,name in zip(req,names):
if name_1==name:
break
if name_1!=name:
print('没有你想查找的关键字')
else:
url='https://www.huya.com/g/{}#tag0'.format(re)
data=requests.get(url,headers=headers).content.decode()
html=etree.HTML(data)
#链接
link_list=html.xpath('//a/img[@class="pic"]/@data-original')
#名字
names_1_list=html.xpath('//span[@class="avatar fl"]//img/@title')
# 文件名字
os.mkdir(name)
for link, names_1 in zip(link_list, names_1_list):
# 获取链接
link = link.split('?')[0]
try:
# 保存数据
urlretrieve(link, name + '/' + names_1 + '.jpg')
print(names_1 + '100%')
except:
pass
最后
奉上图片
福利
随便来几张我觉得好看的吧!



好了好了,这些够了,不然我要被抓了= =
总结
还是少看点,适当的看还是有帮助滴,如果走火后果还是很严重的啊!!!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/66875.html

