
关于
今天的我早早的起床,看着天空已经亮起,我不禁感叹,啊!这又是忙碌的一天,我拿起手机一看已经中午12点了,b站的百妖谱应该完结更新了,再点开微信一看,我的朋友发来了消息,告诉我说今天的百妖谱好催泪啊,不过我没有看过,但是又没有时间去看,就只好把百妖谱的弹幕爬取出来,好让我们能愉快的吹水!
查找
当我点开f12去查找弹幕数据的时候发现,茫茫人海,这么多想找完,不如我把这部动漫看完不是来的更快吗?于是我想,百度,有啥问题就直接面向百度找到了相关的url:https://comment.bilibili.com/+cid.xml(以百妖谱为例,百妖谱最后一集的cid=208606300),每一个弹幕都是除了cid其他都不改变.
这个好办,我直接打开f12搜索了cid关键字就出来了以下:
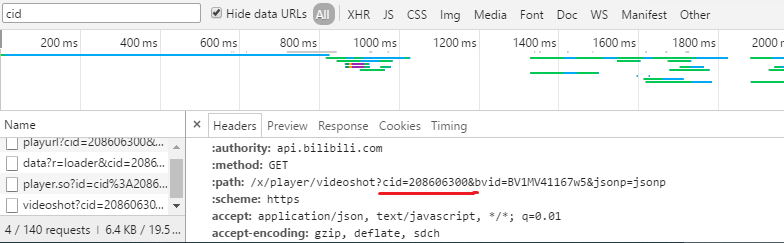
那么找到关键字以后他的地址就已经找到了,接着就好办了!
步骤
不管是什么爬虫都离不开的4大要素
1.获取url地址
2.发送请求
3.解析数据
4.保存数据
本文可能会用到xpath工具,如果有不太清楚的可以点开此链接:https://blog.csdn.net/weixin_45859193/article/details/107081107
代码
注释有解释,代码不多很容易理解
import requests
from lxml import etree
import sys
url = 'https://comment.bilibili.com/208606300.xml'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36'}
response = requests.get(url, headers=headers)
#解析xml数据
req = etree.fromstring(response.content)
#保存数据到记事本
mylog=open('recode.log',mode='a',encoding='utf-8')
data = req.xpath('/i/d/text()')
#第一层for循环是判断dat的数量有多少
for dat in data:
len = data.count(dat)
#这一层for循环来个嵌套是把相同的数据删除掉,以此类推
for da in data:
if da==dat:
data.remove(da)
print('弹幕:%s 数量:%d'%(dat,len),file=mylog)
#关闭文件
mylog.close()
结果
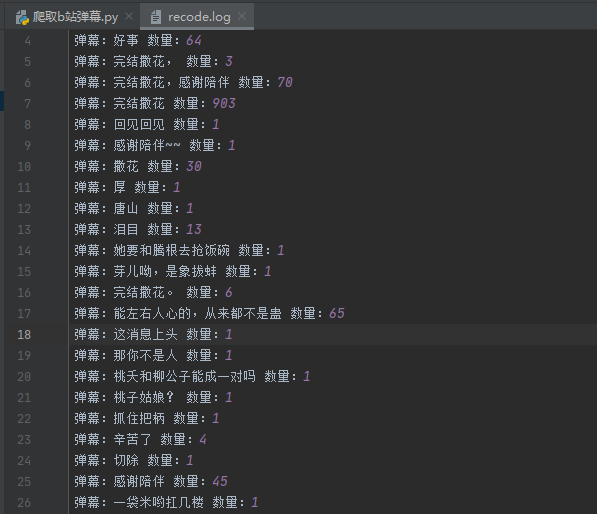
动漫图片

总结
不要熬夜,不然得12点才起得来= =…
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/66876.html

