
一、前言
在使用MySQL的过程中,经常会遇到一些新需求,急需要一些之前未了解过的新的函数来解决,但是可能因为版本、数据等问题,看了官方或网友的介绍之后,不确定能不能真正解决自己的问题,这时候需要测试一下函数的功能是否符合自己的预期结果。
怎么快速验证呢?
下面介绍给小伙伴们介绍几个快速验证方法。
二、函数快速验证方法
2.1 自建字段查询
语法参考:
select function(xxx);
特点:
- 简单快速
- 适合一些比较简单不需要跨行计算的函数,比如left()、length()、trim()等;
为了更好观展开介绍验证方法,我们先假设有以下几个问题:
-
问题1、获取字符中某分隔符后面的字符
- 描述:假设我有一个工号和姓名合并在一起的字段(形如:s1001-xindata),工号是定长的,名字是不定长的。
- 目标:取出名字。
- 已知:可以使用
substring_index()实现 - 测试:
select substring_index('s1001-xindata','-',-1) as name; 

-
问题2、时间字段改为截止到20点xxx,时间拼接函数
- 描述:假设我有转化周期的结束时间(如:2022-01-01 23:59:59),现在需要知道在转化周期的结束当天20点前的转化数据。
- 目标:获取结束当天截止到20点的时间(转化数据略)。
- 已知:可以使用
date_format()或date_sub()实现 - 测试:
select date_format('2022-01-01 23:59:59','%Y-%m-%d 20:00:00') as col1,date_sub('2022-01-01 23:59:59',interval 4 hour) as col2; 
-
问题3、时间差值
- 描述:假设我有一个用户购买商品的时间(如:2022-01-01 15:23:31),现在要看距今使用时长。
- 目标:获取用户购买至今有多少天。
- 已知:datediff()
- 测试:
select datediff(curdate(),'2022-01-01 15:23:31') as col1; 
-
问题4、计算符号:length()、str_length()
- 描述:假设我有一个字符串字段,现在要统计某个字符的个数。字符串:‘123-45-67-8’
- 目标:计算字符
-的个数 - 已知:length()
- 测试:
select length('123-45-67-8')-length(replace('123-45-67-8','-','')) as col1; 
以上几个问题,就是通过自建字段验证函数应用的方法,一般情况下就是有一个什么样的需求,知道某个函数,测试一下能不能实现,然后自建一个字符串快速验证一下。
2.2 使用with as建临时表
基本框架就是
with table_name2 as(
select xxx as col_name1 union all
select xxx
)
select * from table_name2;
该方法也和直接用子查询表单(如下代码)差不多,不过,用with as更优雅整洁,更好聚焦,有点像编程里的类或函数,写完直接通过自定义的表名进行查询。
select *
from(
select xxx as col_name1 union all
select xxx
) as table_name2;
当然如果你喜欢或者习惯用子查询也可以改用子查询。
特点:
- 比较简单快速
- 适合跨行计算的较复杂的函数测试,如:
max()、group_concat()等。
为了更好观展开介绍验证方法,我们先假设有以下问题:
- 问题1、单行拆成多行
- 描述:假设我有一个订单表(
orders),表中一列存着一堆商品,如下: 
- 目标:将该列中的商品都作为一个独立行,分成几行来记录,如下:
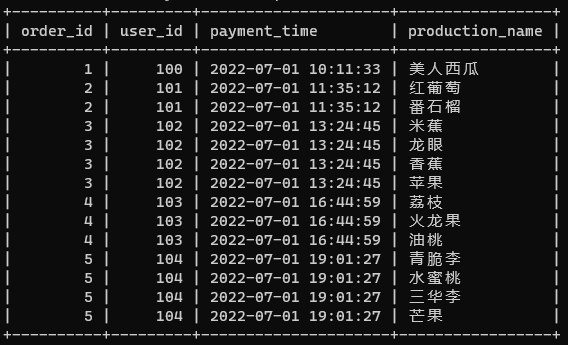
- 已知:通过计算分隔符(这里是逗号)的个数,将1行先扩展到多行(具体多少看逗号数量,逗号数加1),然后保留用
substring_index()切割取倒数第一个值(有点抽象,看测试代码),可以逐步测试。 - 测试:这里通过
with as创建临时表来测试,具体做法就是模拟原表的关键字段内容的结构,取几个值创建一个临时的表单,比如说我这里模仿原表orders取其中两行,用with as语句创建一个临时的表单orders(如下图)。 
- 具体代码如下:
- 描述:假设我有一个订单表(
with
orders as(
select 1 as order_id,'苹果,龙眼,香蕉,米蕉' as production_name union all
select 2,'美人西瓜'
)
-- 辅助表,用于扩展每一个订单
,help_id as(
select 0 as id union all
select 1 union all
select 2 union all
select 3 union all
select 4 union all
select 5
)
-- substring_index()将字符串按分隔符分割,然后指定取第几个
select o.order_id,substring_index(substring_index(o.production_name,',',hi.id+1),',',-1) as production_name
from orders o
-- char_length()计算字符长度,replace()替换字符;等号右边即是计算分隔符的数量
join help_id hi on hi.id<=(char_length(o.production_name)-char_length(replace(o.production_name,',','')));
- 问题2、多行合并一行
- 描述:假设有一个订单、品类及具体商品的关系表
order_productions,如下 
- 目标:按订单和品类聚合,将商品合并为一行

- 已知:
group_concat([合并字段] order by [排序字段] separator '[分隔符]') - 测试:同问题1,通过
with as在原表取几个值创建一个临时的表单order_productions(代码如下),然后根据订单id和类型聚合,得到最终结果。
- 描述:假设有一个订单、品类及具体商品的关系表
with
order_productions as(
select 1 as order_id,'瓜果' as subtype,'美人西瓜' as production_name union all
select 2 ,'浆果','番石榴' union all
select 2 ,'浆果','红葡萄' union all
select 3 ,'浆果','米蕉' union all
select 3 ,'浆果','苹果' union all
select 3 ,'浆果','香蕉' union all
select 3 ,'仁果','龙眼'
)
-- group_concat(),需要配合group by使用
select op.order_id,op.subtype
,group_concat(op.production_name order by op.production_name separator ',') as production_name
from order_productions op
group by op.order_id,op.subtype;
- 问题3、多行转为多列(和问题2同表)
- 描述:假设我有一个表,如下
- 目标:将订单和品类转化为二维表,看每一个订单都购买了什么品类的商品,结果如下:

- 已知:
max()和case when [条件1] then [结果1] else [结果2] end - 测试:
with
order_productions as(
select 1 as order_id,'瓜果' as subtype,'美人西瓜' as production_name union all
select 2 ,'浆果','番石榴' union all
select 2 ,'浆果','红葡萄' union all
select 3 ,'浆果','米蕉' union all
select 3 ,'浆果','苹果' union all
select 3 ,'浆果','香蕉' union all
select 3 ,'仁果','龙眼'
)
-- case when相当于if()函数;max()取最大,配合group by使用
select op.order_id
,max(case when op.subtype='瓜果' then 1 else 0 end) "瓜果"
,max(case when op.subtype='浆果' then 1 else 0 end) "浆果"
,max(case when op.subtype='仁果' then 1 else 0 end) "仁果"
,max(case when op.subtype='核果' then 1 else 0 end) "核果"
from order_productions op
group by op.order_id;
注意:**with as****测试通过之后,还是要放在源表进行测试验证,**以避免遗漏一些数据,如果发现有异常数据,还需要进行相关清洗。
2.3 搭建数据库建表查询
如果还没有下载数据库,可以参考往期的文章:MySQL安装及应用合集(1):MySQL安装方式介绍,选择一种方式安装,然后创建相关的数据库和数据表测试,基本语法参考MySQL安装及应用合集(4):MySQL库表基本操作-增删改查。
以2.2 问题1和问题2为例,首先,我创建一个数据库,命名为my_datas,并切换到数据库下:
-- 创建数据库
create database my_datas;
-- 启用数据库
use my_datas;
创建问题1的数据表:
-- 创建orders表
create table my_datas.orders(
order_id bigint not null AUTO_INCREMENT comment '订单ID'
,production_name varchar(32) not null comment '购买商品'
,primary key(order_id)
) comment '订单表_by xindata';
-- 插入数据
insert into my_datas.orders(production_name)values('美人西瓜'),('苹果,龙眼,香蕉,米蕉');
2.2 问题1-单行拆成多行代码实现:
with help_id as(
select 0 as id union all
select 1 union all
select 2 union all
select 3 union all
select 4 union all
select 5
)
SELECT o.order_id,o.user_id,o.payment_time,substring_index(substring_index(o.production_name,',',hi.id+1),',',-1) AS production_name
FROM my_datas.orders o
JOIN help_id hi ON hi.id <=
(CHAR_LENGTH(o.production_name)-CHAR_LENGTH(replace(o.production_name,',','')))
order by o.order_id;
创建问题2的数据表:
-- 创建order_productions表
create table my_datas.order_productions(
order_id bigint not null AUTO_INCREMENT comment '订单ID'
,subtype varchar(8) not null comment '购买商品'
,production_name varchar(16) not null comment '购买商品'
,primary key(order_id,production_name)
) comment '订单-商品表_by xindata';
-- 插入数据表
insert into my_datas.order_productions(order_id,subtype,production_name)
select 1 as order_id,'瓜果' as subtype,'美人西瓜' as production_name union all
select 2 ,'浆果','番石榴' union all
select 2 ,'浆果','红葡萄' union all
select 3 ,'浆果','米蕉' union all
select 3 ,'浆果','苹果' union all
select 3 ,'浆果','香蕉' union all
select 3 ,'仁果','龙眼' ;
2.2 问题2-多行合并一行代码实现:
select op.order_id,op.subtype
,group_concat(op.production_name order by op.production_name separator ',') as production_name
from my_datas.order_productions op
group by op.order_id,op.subtype;
测试完,可以直接删除数据库,或者删除数据表
-- 删库
drop database my_datas;
-- 删表
drop table my_datas.orders;
drop table my_datas.order_productions;
通过创建数据库表进行查询,可以模仿生产环境数据库进行,建表过程中也可以把源表的ddl拿来用,进行仿真测试。不过会相对繁琐一些。
特点
- 能够最真实还原数据结构,然后测试性能(可结合explain)
- 比较繁琐和复杂
2.4 直接在源表测试验证
其实这是必经之路。不管上面三种方式测试完之后,结果有多么完美,最后还是要在源表进行测试验证,以避免遗漏一些数据,同时如果发现有异常数据,还需要进行相关清洗。毕竟现实中的数据,可能会存在一些脏数据。
那为什么不一开始就在源表测试呢?
一方面考虑源表的数据量,数据量如果很大,像千万级别、亿级别的,可能跑起来会比较慢,没法快速验证;另一方面是源表数据量较多,定点做小范围测试比较麻烦一些,需要写一些where条件缩小范围以便于修改代码测试结果,而直接拿到几个值,模仿测试会更加方便测试。
源表测试,需要注意,比如说
- 字段值问题,可能前后有空格影响验证
- 需要指定有相关测试的字段,比如说有一些数据以数组形式存放,有的选项没有获取到值时会存为空或者直接没有该字段(像问卷的选填选项,没填写的时候,可能就不会记录数据),这时候要定位到有值的字段进行测试,以验证效果
- 如果表比较大,不便于测试,可以挑选小部分相关数据,通过以上几种方法建表,模拟测试
特点:适合数据量小的表,数据量太大,可能会影响测试效率
三、总结
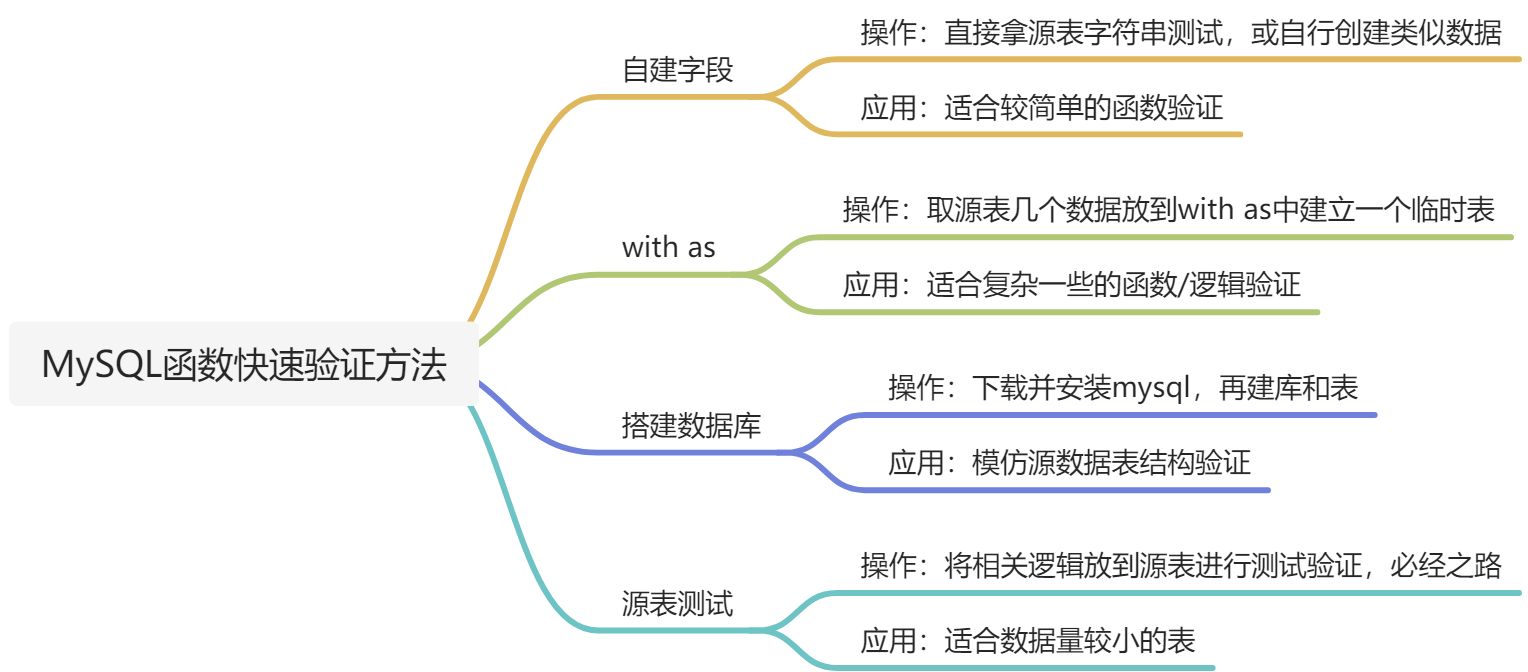
不管是否哪一种方法,能实现最终的效果都是可以的!同时也不管通过什么方法,最终都需要在源表进行测试,以保证准确无误,达成最终效果。
– End –
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/66953.html

