
1、前言
随着时间和业务的发展,数据库中的表会越来越多,表中的数据也会越来越多,带来的问题就是对于数据的操作会越来越慢。当遇见这种情况,如何解决这些问题呢?提升单台服务器的配置?但是单台服务器的资源毕竟有限,最终数据库的数量和数据处理能力还是会遇到瓶颈,再者无限提升服务器配置也会急剧增加硬件成本。还有什么方法可以解决这些问题,这就是今天我们要讨论的分库分表。
分库分表主要是为了解决互联网应用的大数据量存储问题,分库分表通常分为:垂直划分、水平划分。
- 垂直划分
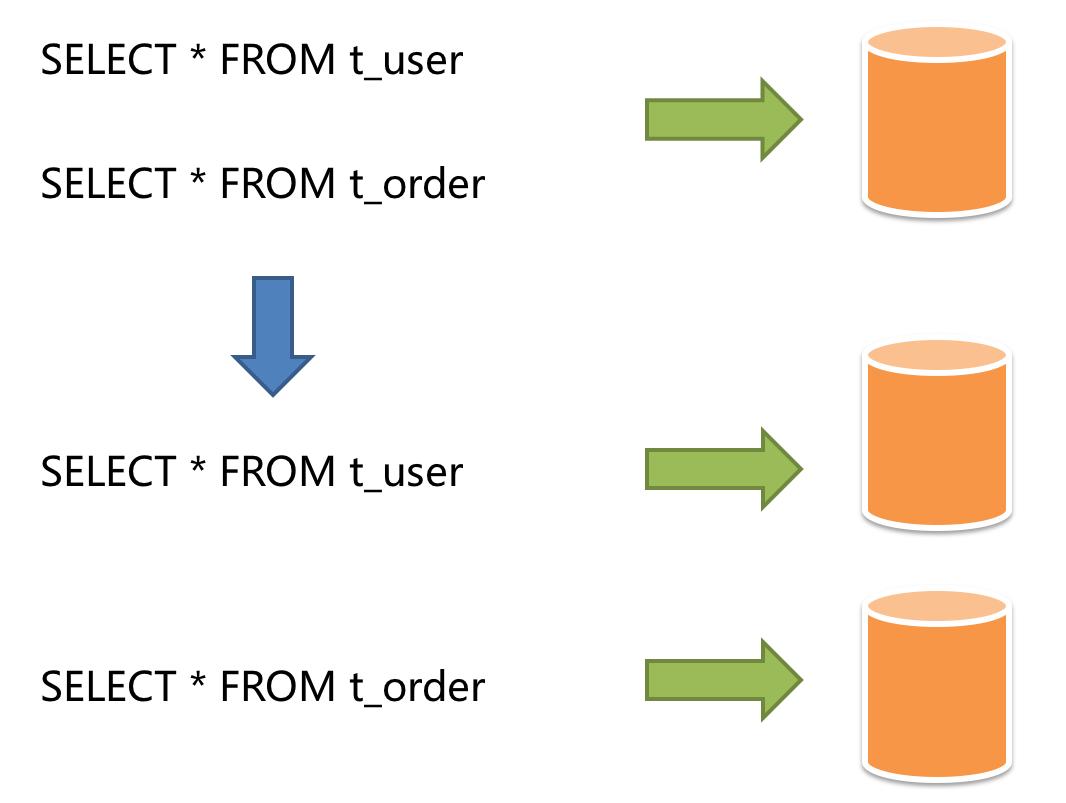
按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用。 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。

- 水平划分
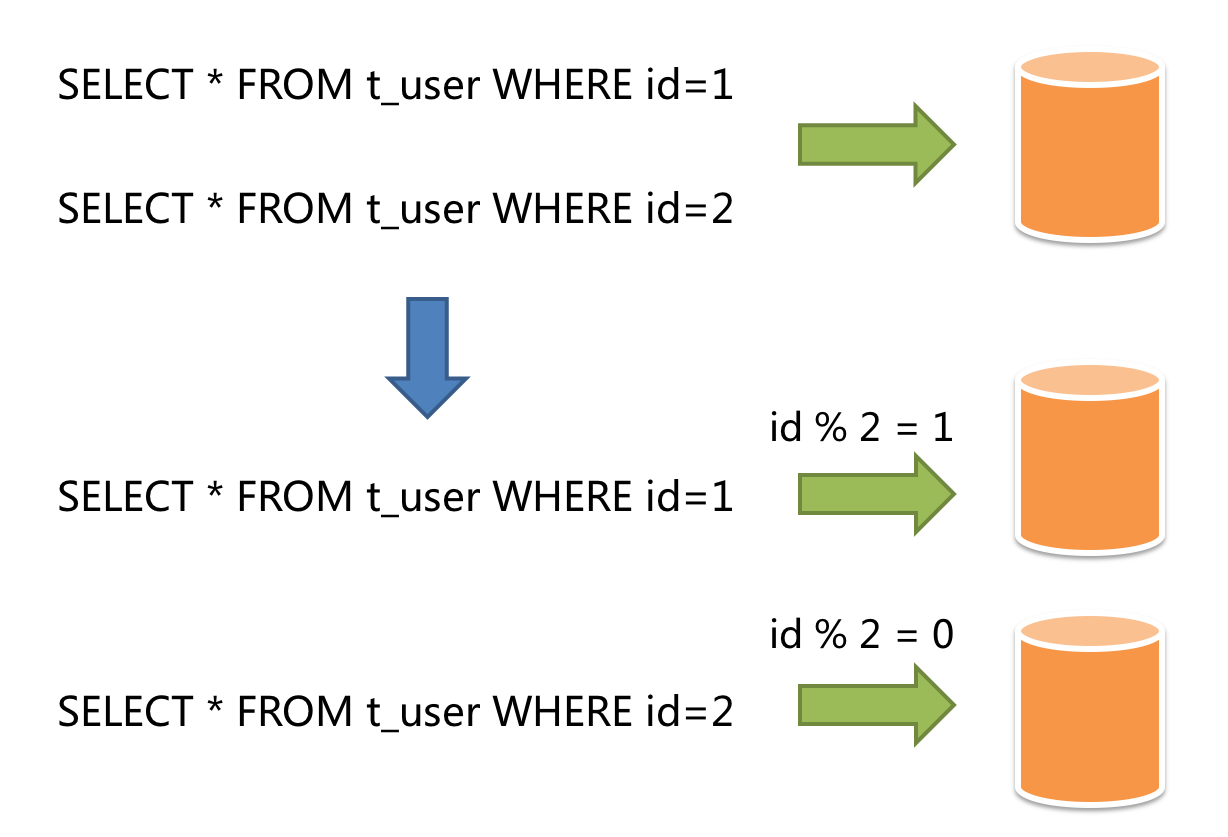
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。
2、主角:Sharding-jdbc
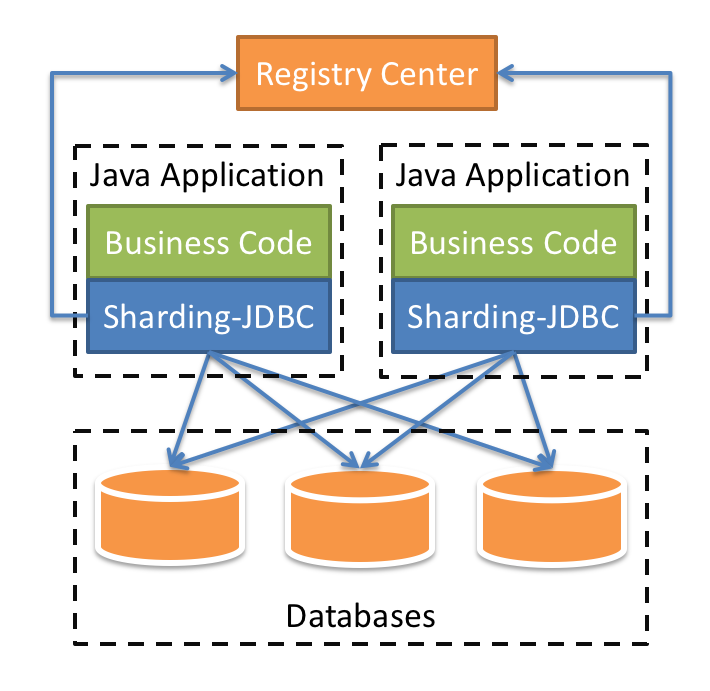
Apache ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款相互独立,却又能够混合部署配合使用的产品组成。 它们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
Sharding-jdbc是ShardingSphere中一个模块,定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
- 支持任意实现JDBC规范的数据库。目前支持 MySQL,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。
3、核心概念
- 逻辑表(LogicTable):水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:订单数据根据主键尾数拆分为10张表,分别是t_order_0到t_order_9,他们的逻辑表名为t_order。
- 真实表(ActualTable):在分片的数据库中真实存在的物理表。即上个示例中的t_order_0到t_order_9。
- 数据节点(DataNode):数据分片的最小单元。由数据源名称和数据表组成,例:ds_0.t_order_0。
- 动态表(DynamicTable):逻辑表和真实表不一定需要在配置规则中静态配置。比如按照日期分片的场景,真实表的名称随着时间的推移会产生变化。此类需求Sharding-JDBC是支持的,不过目前配置并不友好,会在新版本中提升。
- 广播表
指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。 - 绑定表(BindingTable):指分片规则一致的主表和子表。例如:t_order表和t_order_item表,均按照order_id分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。举例说明,如果SQL为:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在不配置绑定表关系时,假设分片键order_id将数值10路由至第0片,将数值11路由至第1片,那么路由后的SQL应该为4条,它们呈现为笛卡尔积:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在配置绑定表关系后,路由的SQL应该为2条:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
其中t_order在FROM的最左侧,ShardingSphere将会以它作为整个绑定表的主表。 所有路由计算将会只使用主表的策略,那么t_order_item表的分片计算将会使用t_order的条件。故绑定表之间的分区键要完全相同。
-
分片键
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL 中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,Apache ShardingSphere 也支持根据多个字段进行分片。 -
分片算法
通过分片算法将数据分片,支持通过=、>=、<=、>、<、BETWEEN和IN分片。 分片算法需要应用方开发者自行实现,可实现的灵活度非常高。目前提供4种分片算法。 由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。1>、精确分片算法
对应 PreciseShardingAlgorithm,用于处理使用单一键作为分片键的 = 与 IN 进行分片的场景。需要配合 StandardShardingStrategy 使用。2>、范围分片算法
对应 RangeShardingAlgorithm,用于处理使用单一键作为分片键的 BETWEEN AND、>、<、>=、<=进行分片的场景。需要配合 StandardShardingStrategy 使用。3>、复合分片算法
对应 ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合 ComplexShardingStrategy 使用。4>、Hint分片算法
对应 HintShardingAlgorithm,用于处理使用 Hint 行分片的场景。需要配合 HintShardingStrategy 使用。 -
分片策略
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。目前提供 5 种分片策略。1>、标准分片策略
对应 StandardShardingStrategy。提供对 SQ L语句中的 =, >, <, >=, <=, IN 和 BETWEEN AND 的分片操作支持。 StandardShardingStrategy 只支持单分片键,提供 PreciseShardingAlgorithm 和 RangeShardingAlgorithm 两个分片算法。 PreciseShardingAlgorithm 是必选的,用于处理 = 和 IN 的分片。 RangeShardingAlgorithm 是可选的,用于处理 BETWEEN AND, >, <, >=, <=分片,如果不配置 RangeShardingAlgorithm,SQL 中的 BETWEEN AND 将按照全库路由处理。2>、复合分片策略
对应 ComplexShardingStrategy。复合分片策略。提供对 SQL 语句中的 =, >, <, >=, <=, IN 和 BETWEEN AND 的分片操作支持。 ComplexShardingStrategy 支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。3>、行表达式分片策略
对应 InlineShardingStrategy。使用 Groovy 的表达式,提供对 SQL 语句中的 = 和 IN 的分片操作支持,只支持单分片键。 对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: t_user_$->{u_id % 8} 表示 t_user 表根据 u_id 模 8,而分成 8 张表,表名称为 t_user_0 到 t_user_7。 详情请参见行表达式。4>、Hint分片策略
对应 HintShardingStrategy。通过 Hint 指定分片值而非从 SQL 中提取分片值的方式进行分片的策略。5>、不分片策略
对应 NoneShardingStrategy。不分片的策略。 -
SQL Hint
对于分片字段非 SQL 决定,而由其他外置条件决定的场景,可使用SQL Hint灵活的注入分片字段。 例:内部系统,按照员工登录主键分库,而数据库中并无此字段。SQL Hint支持通过Java API和SQL注释(待实现)两种方式使用。 详情请参见强制分片路由。
4、实践1-读写分离
前面《MySql5.7 数据库安装及主从同步配置》中,我们知道了MySQL主从复制的环境搭建,这个是读写分离的基础。而在《基于MyCat实现的Mysql数据库的读写分离》中,我们又实现了基于MyCat的读写分离实现,这里我们实现通过Sharding-jdbc的读写分离,这里数据库环境还沿用了之前的配置。
4.1、pom.xml
引入Sharding-jdbc依赖,完整内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.5.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.qriver.shardingjdbc</groupId>
<artifactId>qriver-sharding-jdbc</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<!--sharding-jdbc依赖-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.4</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!--集成druid连接池-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.11</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
</project>
4.2、application.properties配置文件
这里主要配置了主从数据库源,完整内容如下:
server.port=8080
# 数据源名称集合,对应下面数据源配置的名称
spring.shardingsphere.datasource.names=master,slave
# 主数据源
spring.shardingsphere.datasource.master.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.master.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master.url=jdbc:mysql://192.168.1.8:3306/test?useSSL=true&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.master.username=root
spring.shardingsphere.datasource.master.password=123456
# 从数据源
spring.shardingsphere.datasource.slave.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.slave.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.slave.url=jdbc:mysql://192.168.1.9:3306/test?useSSL=true&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.slave.username=root
spring.shardingsphere.datasource.slave.password=123456
# 用于配置从库负载均衡算法类型,可选值:ROUND_ROBIN(轮询),RANDOM(随机),(这里的demo,只使用了一个从数据库)
spring.shardingsphere.masterslave.load-balance-algorithm-type=round_robin
# 最终的数据源名称
spring.shardingsphere.masterslave.name=dataSource
# 主库数据源名称
spring.shardingsphere.masterslave.master-data-source-name=master
# 从库数据源名称列表,多个逗号分隔
spring.shardingsphere.masterslave.slave-data-source-names=slave
#配置Mybatis
mybatis.mapper-locations=classpath:mappings/**/*Mapper.xml
mybatis.type-aliases-package=com.qriver.shardingjdbc
#日志
logging.level.com.qriver.shardingjdbc=debug
4.3、业务实现
&esmp;我们为了演示读写分离,我们这里主要实现一个insert方法,一个findAll方法。首先,entity类如下:
/**
* 实体类
*/
public class DemoEntity implements Serializable {
private int id;
private String name;
//省略setter or getter 方法
}
Mapper映射接口:
@Mapper
public interface DemoMapper {
public void insert(DemoEntity entity);
public List<DemoEntity> findAll();
}
Mapper映射接口对应的配置文件:
<mapper namespace="com.qriver.shardingjdbc.mapper.DemoMapper">
<select id="findAll" resultType="com.qriver.shardingjdbc.entity.DemoEntity">
SELECT T.* FROM test T
</select>
<insert id="insert" parameterType="com.qriver.shardingjdbc.entity.DemoEntity">
INSERT INTO test (id,name) VALUES (#{id},#{name})
</insert>
</mapper>
DemoService类:
@Service
public class DemoService {
@Autowired
private DemoMapper demoMapper;
public void insert(DemoEntity entity){
demoMapper.insert(entity);
}
public List<DemoEntity> findAll(){
return demoMapper.findAll();
}
}
4.4、测试类
这里为了演示读写分离,我们取消了两个数据库间的同步。首先,通过执行insertTest方法,可以发现数据会插入到master数据库中,而执行findAllTest()方法时,读取的数据是slave数据库中的数据。
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(classes = ShardingJdbcApplication.class)
public class DemoTest {
@Autowired
private DemoService demoService;
@Test
public void insertTest(){
DemoEntity demo = new DemoEntity();
demo.setId(16);
demo.setName("test");
demoService.insert(demo);
}
@Test
public void findAllTest(){
List<DemoEntity> list = demoService.findAll();
for(int i=0;list !=null && i < list.size();i++){
DemoEntity demo = list.get(i);
System.out.println(demo.toString());
}
}
}
5、实践2-分库分表
分库分表一般分以下情况:
- 同库不同表(同库水平拆分)
- 分库不分表(垂直拆分)
- 分库分表(不同库水平拆分)
为了实现上述三种情况,我们还是使用前面基于Mycat实现的情况进行验证(创建三个表user、role和order。其中,user只在192.168.1.8上(数据库db8),且分成user_0、user_1两个表,role只在192.168.1.9上(db9),order在192.168.1.8/9上)。
| 数据库 | user(逻辑表) | role(逻辑表) | org(逻辑表) | order(逻辑表) |
|---|---|---|---|---|
| db8(192.168.1.8) | user_0、user_1 | org | order_0、order_1 | |
| db9(192.168.1.9) | role | order_0、order_1 |
5.1、同库不同表
这里主要实现在db_8这一个库中,把user表拆分成了user_0和user_1两个表。分表采用内置的算法。
# 数据源名称集合,对应下面数据源配置的名称
spring.shardingsphere.datasource.names=master
# 主数据源
spring.shardingsphere.datasource.master.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.master.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master.url=jdbc:mysql://192.168.1.8:3306/db_8?useSSL=true&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.master.username=root
spring.shardingsphere.datasource.master.password=123456
# 分表配置
spring.shardingsphere.sharding.tables.user.actual-data-nodes=master.user_${0..1}
# inline 表达式(根据Id求余)
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user_${id.longValue() % 2}
5.2、分库不分表
&esmp;这里主要实现org落在db_8上,role落在db_9上。配置如下:
# 数据源名称集合,对应下面数据源配置的名称
spring.shardingsphere.datasource.names=db8,db9
# 数据源2
spring.shardingsphere.datasource.db8.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db8.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db8.url=jdbc:mysql://192.168.1.8:3306/db_8?useSSL=true&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.db8.username=root
spring.shardingsphere.datasource.db8.password=123456
# 数据源1
spring.shardingsphere.datasource.db9.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db9.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db9.url=jdbc:mysql://192.168.1.9:3306/db_9?useSSL=true&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.db9.username=root
spring.shardingsphere.datasource.db9.password=123456
# 绑定role表所在节点
spring.shardingsphere.sharding.tables.role.actual-data-nodes=db9.role
# 绑定org表所在节点
spring.shardingsphere.sharding.tables.org.actual-data-nodes=db8.org
5.3、分库分表
&esmp;主要实现拆分order表,首先根据id,拆分数据库,然后根据f1字段拆分表,配置如下:
# 数据源名称集合,对应下面数据源配置的名称
spring.shardingsphere.datasource.names=db0,db1
# 数据源2
spring.shardingsphere.datasource.db0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db0.url=jdbc:mysql://192.168.1.8:3306/db_8?useSSL=true&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.db0.username=root
spring.shardingsphere.datasource.db0.password=123456
# 数据源1
spring.shardingsphere.datasource.db1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db1.url=jdbc:mysql://192.168.1.9:3306/db_9?useSSL=true&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.db1.username=root
spring.shardingsphere.datasource.db1.password=123456
# 分表配置
spring.shardingsphere.sharding.tables.order.actual-data-nodes=db$->{0..1}.order_$->{0..1}
spring.shardingsphere.sharding.tables.order.table-strategy.inline.sharding-column=f1
spring.shardingsphere.sharding.tables.order.table-strategy.inline.algorithm-expression=order_$->{f1 % 2}
#spring.shardingsphere.sharding.tables.order.key-generator.column=id
#spring.shardingsphere.sharding.tables.order.key-generator.type=SNOWFLAKE
# 自定义算法分库配置
#spring.shardingsphere.sharding.default-database-strategy.standard.sharding-column=id
#spring.shardingsphere.sharding.default-database-strategy.standard.precise-algorithm-class-name=xxx.MyPreciseShardingAlgorithm
# 分库配置
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=db$->{id % 2}
在使用sharding-jdbc进行分库分表、读写分离操作时,主要是通过配置文件来完成的。其他业务逻辑的实现和普通的java逻辑是没有区别的。
参考
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/68748.html

