
1、简介
Spark是一个统一的、用于大数据分析处理的、快速且通用的集群计算系统。它开创了不以MapReduce为执行引擎的数据处理框架,提供了Scala、Java、Python和R这4种语言的高级API,以及支持常规执行图的优化引擎。
Spark还支持包括用于离线计算的Spark Core、用于结构化数据处理的Spark SQL、用于机器学习的MLlib、用于图形处理的GraphX和进行实时流处理的Spark Streaming等高级组件,它在项目中通常用于迭代算法和交互式分析。
Spark和MapReduce的区别
- Spark是基于MapReduce的思想而诞生,二者同为分布式并行计算框架。
- MapReduce进行的是离线数据分析处理,Spark主要进行实时流式数据的分析处理。
- 在数据处理中,MapReduce将Map结果写入磁盘中,影响整体数据处理速度;Spark的DAG执行引擎,充分利用内存,减少磁盘I/O,迭代运算效率高
- MapReduce只提供了Map和Reduce两种操作;Spark有丰富的API,提供了多种数据集操作类型(如Transformation操作中的map、filter、groupBy、join,以及Action操作中的count和collect等)。
- Spark和MapReduce相比其内存消耗较大,因此在大规模数据集离线计算、时效要求不高的项目中,应优先考虑MapReduce,而在进行数据的在线处理、实时数据计算时,更倾向于选择Spark。
2、弹性分布式数据集RDD
在实际数据挖掘项目中,通常会在不同计算阶段之间重复用中间数据结果,即上一阶段的输出结果会作为下一阶段的输入,如多种迭代算法和交互式数据挖掘工具的应用等。MapReduce框架将Map后的中间结果写入磁盘,大量磁盘I/O拖慢了整体的数据处理速度。RDD(Resilient Distributed Dataset)的出现弥补了MapReduce的缺点,很好地满足了基于统一的抽象将结果保存在内存中的需求。Spark建立在统一的抽象RDD上,这使Spark的各个组件得以紧密集成,完成数据计算任务。
分布式数据集RDD是Spark最核心的概念,它是在分布式集群节点中跨多个分区存储的一个只读的元素集合,是Spark中最基本的数据抽象。每个RDD可以分为多个分区,每个分区都是一个数据集片段,同一个RDD的不同分区可以保存在集群中不同的节点上,即RDD是不可变的、可分区的、里面数据可进行并行计算的、包含多个算子的集合。
RDD提供了一种抽象的数据架构,根据业务逻辑将现有RDD通过转换操作生成新的RDD,这一系列不同的RDD互相依赖实现了管道化,采用惰性调用的方式避免了多次转换过程中的数据同步等待,且中间数据无须保存,直接通过管道从上一操作流入下一操作,减少了数据复制和磁盘I/O。
RDD有转换(Transformation)和动作(Action)两大类操作,转换是加载一个或多个RDD,从当前的RDD转换生成新的目标RDD,转换是惰性的,它不会立即触发任何数据处理的操作,有延迟加载的特点,主要标记读取位置、要做的操作,但不会真正采取实际行动,而是指定RDD之间的相互依赖关系;动作则是指对目标RDD执行某个动作,触发RDD的计算并对计算结果进行操作(返回给用户或保存在外部存储器中)。
3、Scala安装
1、下载
wget https://downloads.lightbend.com/scala/2.12.11/scala-2.12.11.tgz --no-check-certificate
2、解压
tar -zxvf scala-2.12.11.tgz -C ../servers/
3、配置环境变量
打开配置文件,
vim /etc/profile
增加如下配置:
export SCALA_HOME=/export/servers/scala-2.12.11
export PATH=:$SCALA_HOME/bin:$PATH
刷新配置
source/etc/profile
4、验证
scala -version


5、在node02、node03环境上配置scala环境
首先复制文件到node02、node03服务器上。
scp -r scala-2.12.11/ node02:$PWD
scp -r scala-2.12.11/ node03:$PWD
然后配置环境变量、验证即可。
4、Spark安装
1、下载
wget http://archive.apache.org/dist/spark/spark-2.4.6/spark-2.4.6-bin-hadoop2.7.tgz
2、解压、重命名
tar -zxvf spark-2.4.6-bin-hadoop2.7.tgz -C ../servers/
cd ../servers
mv spark-2.4.6-bin-hadoop2.7 spark-2.4.6
3、修改环境变量
打开配置文件,
vim /etc/profile
增加如下配置:
export SPARK_HOME=/export/servers/spark-2.4.6
export PATH=:$SPARK_HOME/bin:$PATH
刷新配置
source/etc/profile
4、修改spark-env.sh
复制配置文件spark-env.sh.template,并将其重命名为spark-env.sh。然后增加如下配置:
export SPARK_DIST_CLASSPATH=$(/export/servers/hadoop-2.7.5/bin/hadoop classpath)
export JAVA_HOME=/export/servers/jdk1.8.0_251
export SCALA_HOME=/export/servers/scala-2.12.11
export HADOOP_HOME=/export/servers/hadoop-2.7.5
export HADOOP_CONF_DIR=/export/servers/hadoop-2.7.5/etc/hadoop
export SPARK_MASTER_IP=192.168.1.8
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=2
5、复制spark到node02、node03
scp -r spark-2.4.6/ node02:$PWD
scp -r spark-2.4.6/ node03:$PWD
6、启动
sbin/start-all.sh

5、Spark实例
完整实例地址:《传送门》。实现了经典的统计单词出现次数的统计功能。
1、项目依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>2.4.6</version>
</dependency>
2、java类
public class SparkWordCount {
public static void main(String[] args) {
String hdfsHost = args[0];
String hdfsPort = args[1];
String textFileName = args[2];
SparkConf sparkConf = new SparkConf().setAppName("Spark WordCount Application (java)");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
String hdfsBasePath = "hdfs://" + hdfsHost + ":" + hdfsPort;
//文本文件的hdfs路径
String inputPath = hdfsBasePath + "/input/" + textFileName;
//输出结果文件的hdfs路径
String outputPath = hdfsBasePath + "/output/"
+ new SimpleDateFormat("yyyyMMddHHmmss").format(new Date());
System.out.println("input path : " + inputPath);
System.out.println("output path : " + outputPath);
//导入文件
JavaRDD<String> textFile = javaSparkContext.textFile(inputPath);
JavaPairRDD<String, Integer> counts = textFile
//每一行都分割成单词,返回后组成一个大集合
.flatMap(s -> Arrays.asList(s.split(" ")).iterator())
//key是单词,value是1
.mapToPair(word -> new Tuple2<>(word, 1))
//基于key进行reduce,逻辑是将value累加
.reduceByKey((a, b) -> a + b);
//先将key和value倒过来,再按照key排序
JavaPairRDD<Integer, String> sorts = counts
//key和value颠倒,生成新的map
.mapToPair(tuple2 -> new Tuple2<>(tuple2._2(), tuple2._1()))
//按照key倒排序
.sortByKey(false);
//取前10个
List<Tuple2<Integer, String>> top10 = sorts.take(10);
//打印出来
for(Tuple2<Integer, String> tuple2 : top10){
System.out.println(tuple2._2() + "\t" + tuple2._1());
}
//分区合并成一个,再导出为一个txt保存在hdfs
javaSparkContext.parallelize(top10).coalesce(1).saveAsTextFile(outputPath);
//关闭context
javaSparkContext.close();
}
}
3、打包
我这里选择了使用IntelliJ IDEA的maven打包工具,如下所示:
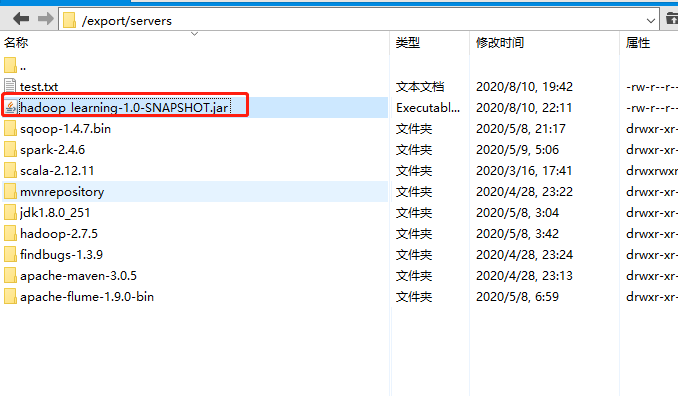
打包后,jar位置:

4、然后把该jar包,放到spark服务器上。
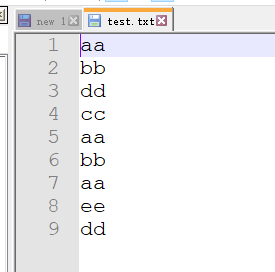
5、准备测试数据。
测试数据,test.txt,内容如下:
然后创建hdfs目录:
./hadoop-2.7.5/bin/hdfs dfs -mkdir /input
再把test.txt放到hdfs上。
./hadoop-2.7.5/bin/hdfs dfs -put test.txt /input
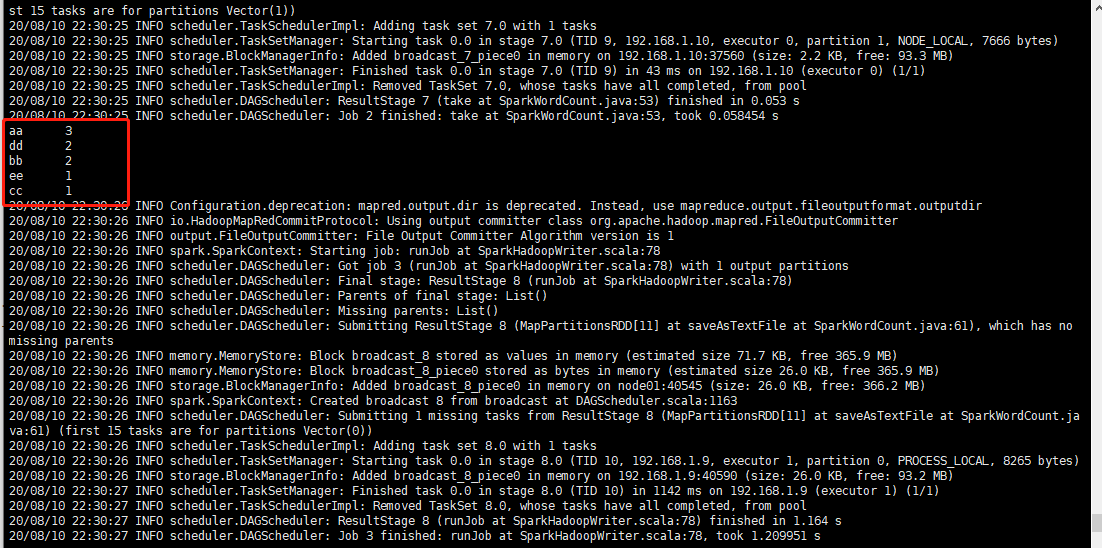
6、启动统计任务
./spark-2.4.6/bin/spark-submit --master spark://192.168.1.8:7077 --class com.qriver.spark.SparkWordCount --executor-memory 512m --total-executor-cores 2 hadoop_learning-1.0-SNAPSHOT.jar 192.168.1.8 8020 test.txt
启动日志:
7、查看结果
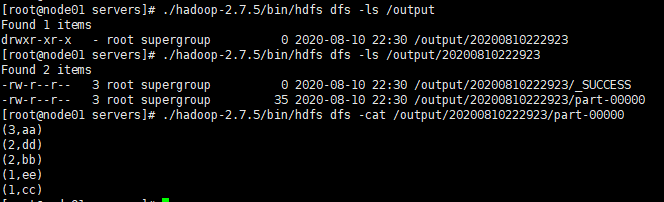
./hadoop-2.7.5/bin/hdfs dfs -ls /output
./hadoop-2.7.5/bin/hdfs dfs -ls /output/20200810222923
./hadoop-2.7.5/bin/hdfs dfs -cat /output/20200810222923/part-00000
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/68808.html

