
1、前言
在《如何快速搭建一个简易的ELK日志分析系统》和《基于Filebeat实现ELK日志分析系统的多源日志采集》两篇博文中,实现了ELK系统的搭建和基于Filebeat实现的多源日志的收集功能,基本上实现了集中式日志管理分析系统的功能。近期,按照上述的步骤,为生产环境搭建了一套集中日志管理系统,其中遇见了几个细节问题,记录下来,以便持续改进。
2、优化点
1>、FileBeat配置name属性。
在FileBeat的filebeat.yml配置文件中,可以配置name属性(默认使用的是hostname名称),唯一标识该FileBeat采集的来源。
因为在我们的实际工作中,有很多系统的日志需要采集,我们可以通过修改每个部署FileBeat的name属性(保证唯一),将来在使用kibana查看日志的时候,通过beat.name属性进行条件筛选,只看对应服务器上的日志。
2>、FileBeat多行日志处理
在原来的博文中只是实现了日志的采集,在实际使用过程中发现,它会把每行记录都生成一条数据记录,这样不方便查看错误日志打印的堆栈信息,为了解决这个问题,还是需要修改FileBeat的filebeat.yml配置文件即可。
multiline:
pattern: '^[0-2][0-9]:[0-5][0-9]:[0-5][0-9]'
negate: true
match: after
注:在filebeat.yml配置文件中默认包含了该配置属性,只是被注释掉了,所以只需要去掉注释,并修改对应属性值即可。
上面配置的意思是:不以时间格式开头的行都合并到上一行的末尾(正则写的不好,忽略忽略)
pattern:正则表达式
negate:true 或 false;默认是false,匹配pattern的行合并到上一行;true,不匹配pattern的行合并到上一行
match:after 或 before,合并到上一行的末尾或开头
其他配置,默认也是注释的(没特殊要求可以不管它 ):
max_lines: 500 #合并最大行,默认500
timeout: 5s #一次合并事件的超时时间,默认5s,防止合并消耗太多时间甚至卡死
修改前:
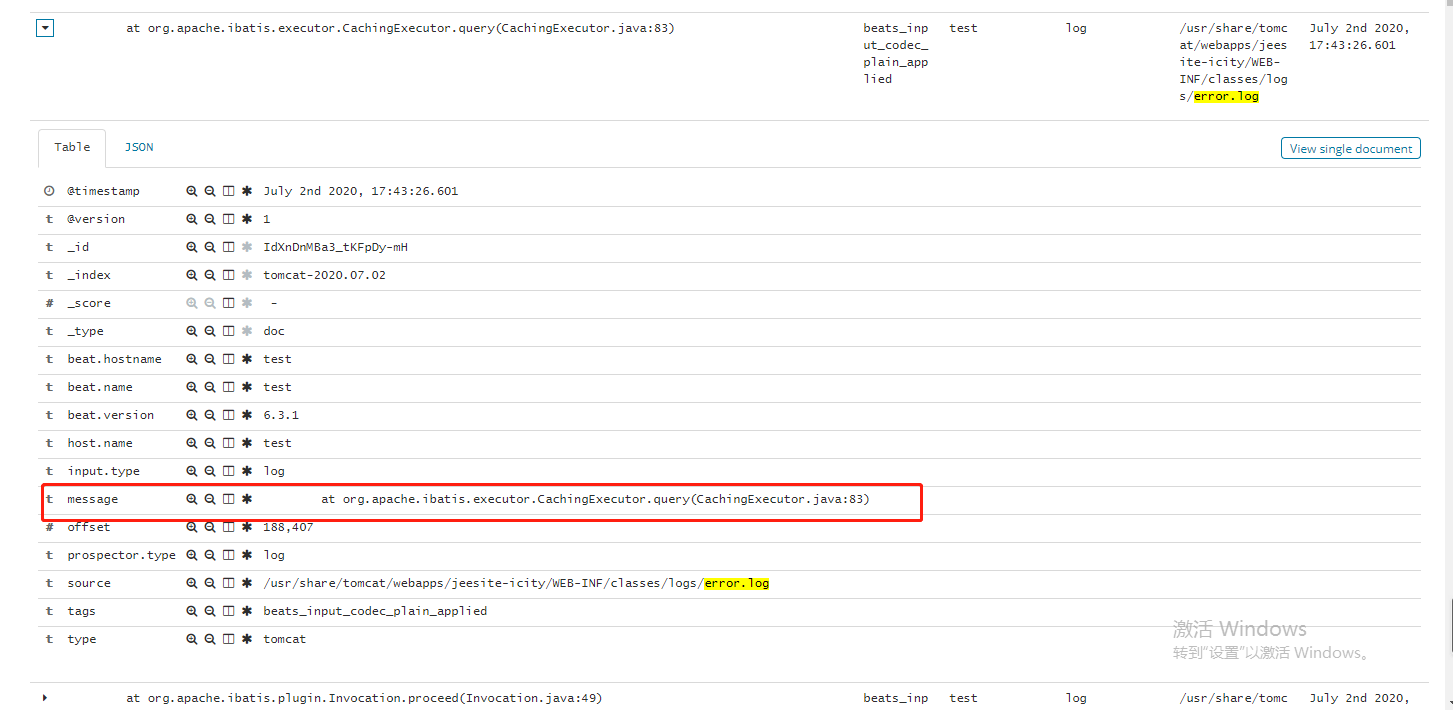
修改后,方便查看:
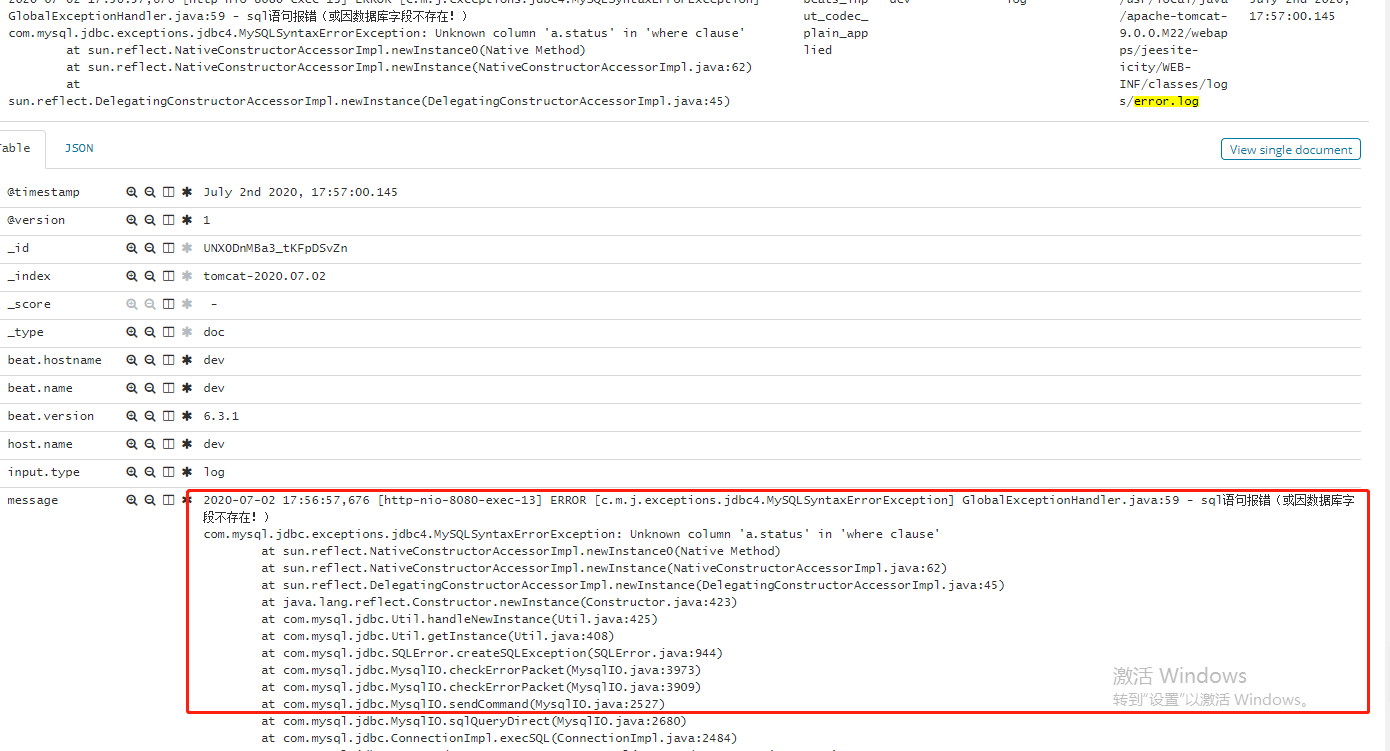
3>、后台启动问题
在启动Elasticsearch、Logstach、Filebeat时,涉及到了后台启动的问题,在学习搭建ELK平台的时候,为了方便查看日志,一直采用了命令行直接启动的方式,后来关掉shell客户端后,所有的服务就会停到,为真实环境使用带了很大的不方便。下面总结了Elasticsearch、Logstach、Filebeat等后台启动的方法,如下:
- Elasticsearch启动
只需要添加一个-d的参数即可,如下所示:
bin/elasticsearch -d #后台运行,避免关掉客户端就会停掉ES。
- Filebeat启动
nohup ./filebeat -e -c filebeat.yml #通过nohup实现后台启动
- Logstach启动
和filebeat类似,可以通过nohup命令实现。
nohup bin/logstash -f job/nginx.conf
4>、Kibana查看日志-根据时间排序
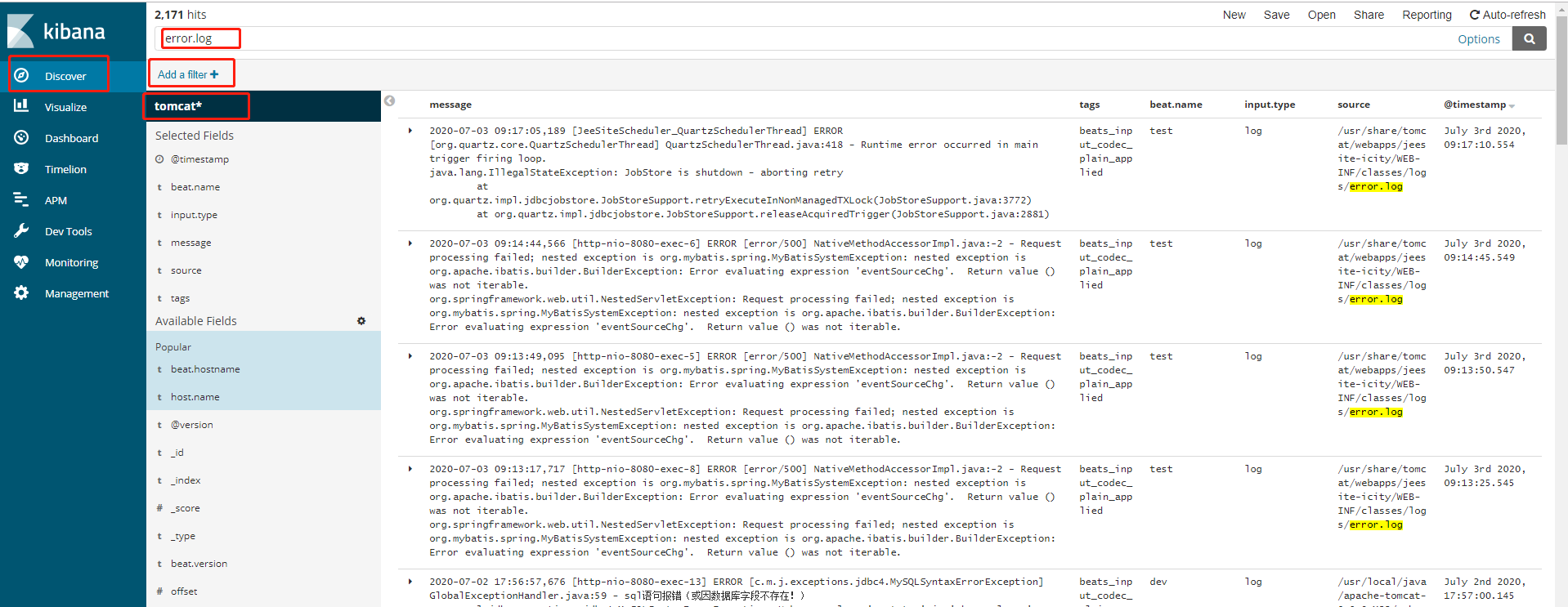
通过kibana的Descover功能,我们可以查看日志平台上的所有日志,可以通过左边的配置,设置需要查看列等信息,如下所示:
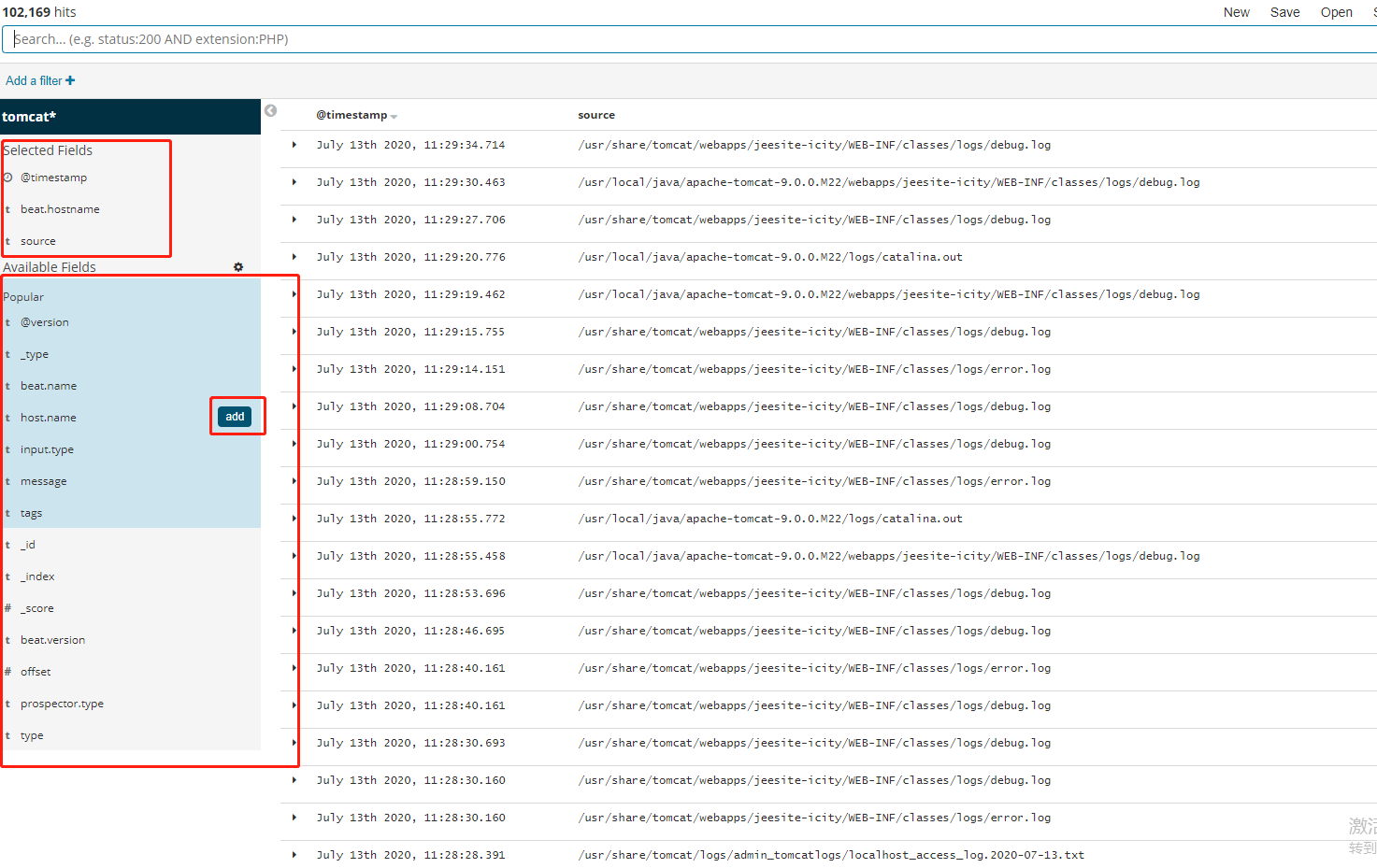
在实际使用过程中,日志默认是根据字段timestamp字段排序的,而且是正序,这样老的日志就会排到前面,非常不方便使用。我们可以通过吧timesstamp字段添加到字段列中,然后上面会有一个排序按钮,如下所示,我们可以通过该按钮实现日志采集时间的倒序。
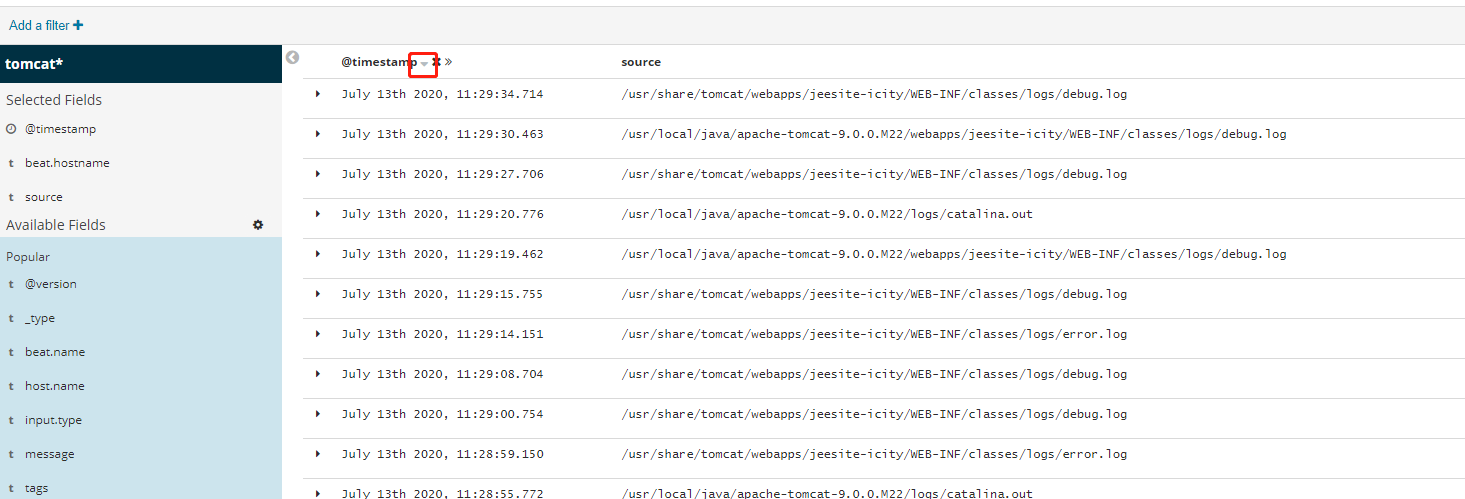
5>、Kibana查看日志优化(进行中)
现在为了方便查询不同系统中,不同日志类型的日志,基本上是通过Kibana的检索条件实现的,期望实现各个系统的日志可以分离,然后可以根据日志的产生日期进行过滤,也可以根据日志的类型进行分离,还在持续学习中。有思路的童鞋,欢迎留言交流。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/68820.html

