
一、概述
在Mybatis的解析器模块中,除了前面分析的解析占位符的PropertyParser、GenericTokenParser等类,还有XPathParser、XNode等用于解析XML的类。而且通常,是由这些解析XML的类完成了配置文件或代码片段的解析后,然后才进入占位符的解析过程的。下面分别来分析XPathParser类和XNode类。
二、XPathParser类
XPathParser类封装了Document、EntityResolver 和XPath等对象,然后提供了一系列的解析XML的方法。
1、字段
/**
* Document对象
*/
private final Document document;
/**
* 是否开启验证
*/
private boolean validation;
/**
* 用于加载本地的DTD文件
*/
private EntityResolver entityResolver;
/**
* 对应配置文件中<propteries>标签定义的键位对集合
*/
private Properties variables;
/**
* XPath对象
*/
private XPath xpath;
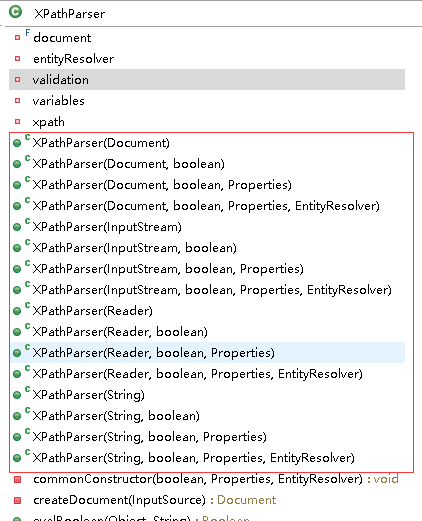
XPathParser类一共定义了5个字段属性,分别是:
- Document(Document对象)
Document 对象代表整个 XML 文档,是一棵文档树的根,可为我们提供对文档数据的最初(或最顶层)的访问入口。 - EntityResolver (加载本地的DTD文件)
如果解析mybatis-config.xml 配置文件,默认联网加载http://mybatis.org/dtd/mybatis-3- config.dtd 这个DTD 文档,当网络比较慢时会导致验证过程缓慢。在实践中往往会提前设置EntityResolver 接口对象加载本地的DTD 文件,从而避免联网加载DTD文件。 - XPath (XPath对象)
XPath 是一种为查询XML 文档而设计的语言,它可以与DOM 解析方式配合使用,实现对XML 文档的解析。 - validation(是否开启验证标记)
该标记表示设置解析器在解析文档的时候是否校验文档,在创建DocumentBuilderFactory实例对象时进行设置。 - variables(配置参数集合)。
对应配置文件中节点下定义的键值对集合,包括通过url或者resource读取的键值对集合。
2、 构造函数
XPathParser类提供了一系列的构造函数,所有的构造函数内部都通过通用的commonConstructor()方法实现对相关字段属性的初始化,部分构造函需要通过createDocument()方法把指定的数据源转换成Document对象。所有的构造函数,大致可以分为四类:
-
XPathParser(Document, boolean, Properties, EntityResolver)
该构造函数以Document作为参数,进行初始化XPathParser实例对象。同时还提供了XPathParser(Document, boolean, Properties)、XPathParser(Document, boolean)、XPathParser(Document)三个重载方法。
public XPathParser(Document document, boolean validation, Properties variables, EntityResolver entityResolver) {
commonConstructor(validation, variables, entityResolver);
this.document = document;
}
-
XPathParser(InputStream, boolean, Properties, EntityResolver)
该构造函数以InputStream作为参数,进行初始化XPathParser实例对象。同时还提供了XPathParser(InputStream, boolean, Properties)、XPathParser(InputStream, boolean)、XPathParser(InputStream)三个重载方法。其中,InputStream参数在构造方法中,最终还是通过createDocument方法转换成了Document对象。
public XPathParser(InputStream inputStream, boolean validation, Properties variables, EntityResolver entityResolver) {
commonConstructor(validation, variables, entityResolver);
this.document = createDocument(new InputSource(inputStream));
}
-
XPathParser(Reader, boolean, Properties, EntityResolver)
该构造函数以Reader作为参数,进行初始化XPathParser实例对象。同时还提供了XPathParser(Reader, boolean, Properties)、XPathParser(Reader, boolean)、XPathParser(Reader)三个重载方法。其中,Reader参数在构造方法中,最终还是通过createDocument方法转换成了Document对象。
public XPathParser(Reader reader, boolean validation, Properties variables, EntityResolver entityResolver) {
commonConstructor(validation, variables, entityResolver);
this.document = createDocument(new InputSource(reader));
}
-
XPathParser(String, boolean, Properties, EntityResolver)
该构造函数以String作为参数,这个参数是XML文档对应的路径,然后根据该文档路径进行初始化XPathParser实例对象。同时还提供了XPathParser(String, boolean, Properties)、XPathParser(String, boolean)、XPathParser(String)三个重载方法。其中,String参数(文档路径)在构造方法中,最终还是通过createDocument方法转换成了Document对象。
public XPathParser(String xml, boolean validation, Properties variables, EntityResolver entityResolver) {
commonConstructor(validation, variables, entityResolver);
this.document = createDocument(new InputSource(new StringReader(xml)));
}
类结构:
3、 createDocument方法
该方法主要实现根据输入源创建Document对象。创建Document对象的过程如下:
- 创建DocumentBuilderFactory对象,并设置相关参数。
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); - 创建DocumentBuilder对象,并设置相关参数。
DocumentBuilder builder = factory.newDocumentBuilder(); - 解析Document对象。
builder.parse(inputSource);
createDocument方法创建Document对象的具体过程如下所示:
private Document createDocument(InputSource inputSource) {
// important: this must only be called AFTER common constructor
try {
//创建DocumentBuilderFactory实例对象
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
/**
* 设置是否启用DTD验证
*/
factory.setValidating(validation);
/**
* 设置是否支持XML名称空间
*/
factory.setNamespaceAware(false);
/**
* 设置解析器是否忽略注释
*/
factory.setIgnoringComments(true);
/**
* 设置必须删除元素内容中的空格(有时也可以称作“可忽略空格”,请参阅 XML Rec 2.10)。
* 注意,只有在空格直接包含在元素内容中,并且该元素内容是只有一个元素的内容模式时,
* 才能删除空格(请参阅 XML Rec 3.2.1)。由于依赖于内容模式,因此此设置要求解析器处于验证模式。默认情况下,其值设置为 false。
*/
factory.setIgnoringElementContentWhitespace(false);
/**
* 指定由此代码生成的解析器将把 CDATA 节点转换为 Text 节点,并将其附加到相邻(如果有)的 Text 节点。默认情况下,其值设置为 false。
*/
factory.setCoalescing(false);
/**
* 指定由此代码生成的解析器将扩展实体引用节点。默认情况下,此值设置为 true。
*/
factory.setExpandEntityReferences(true);
//创建DocumentBuilder实例对象
DocumentBuilder builder = factory.newDocumentBuilder();
//指定使用 EntityResolver 解析要解析的 XML 文档中存在的实体。将其设置为 null 将会导致底层实现使用其自身的默认实现和行为。
builder.setEntityResolver(entityResolver);
//指定解析器要使用的 ErrorHandler。将其设置为 null 将会导致底层实现使用其自身的默认实现和行为。
builder.setErrorHandler(new ErrorHandler() {
@Override
public void error(SAXParseException exception) throws SAXException {
throw exception;
}
@Override
public void fatalError(SAXParseException exception) throws SAXException {
throw exception;
}
@Override
public void warning(SAXParseException exception) throws SAXException {
}
});
return builder.parse(inputSource);
} catch (Exception e) {
throw new BuilderException("Error creating document instance. Cause: " + e, e);
}
}
4、 commonConstructor方法
构造器通用代码块,用于初始化validation、entityResolver、variables、xpath等属性字段。其中,validation、entityResolver、variables三个参数通过参数传递过来;xpath属性是通过XPathFactory创建。具体代码片段:
private void commonConstructor(boolean validation, Properties variables, EntityResolver entityResolver) {
this.validation = validation;
this.entityResolver = entityResolver;
this.variables = variables;
XPathFactory factory = XPathFactory.newInstance();
this.xpath = factory.newXPath();
}
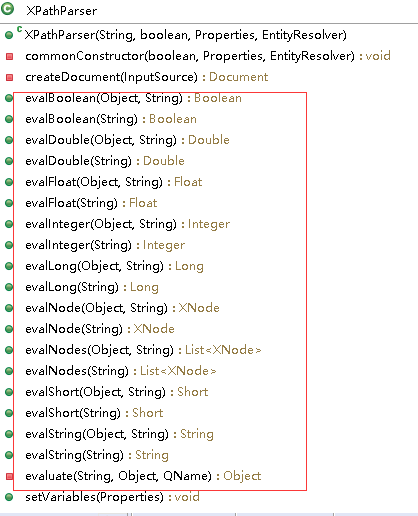
4、 evalXXX方法
XPathParser类提供了一系列的evalXXX方法,见下图,这些方法主要用于解析boolean 、short、long 、int 、String 、Node等类型的信息。底层是通过evaluate()方法实现。其中,evalString()方法中,会通过调用PropertyParser.parse()处理占位符;evalNode()、evalNodes()方法中,根据解析结果会创建XNode对象。具体创建过程,在XNode类源码分析中学习。
evaluate()方法代码:
private Object evaluate(String expression, Object root, QName returnType) {
try {
//计算指定上下文中的 XPath 表达式并返回指定类型的结果。
//如果 returnType 不是 XPathConstants (NUMBER、STRING、BOOLEAN、NODE 或 NODESET) 中定义的某种类型,则抛出 IllegalArgumentException。
//如果 item 为 null 值,则将使用一个空文档作为上下文。如果 expression 或 returnType 为 null,则抛出 NullPointerException。
return xpath.evaluate(expression, root, returnType);
} catch (Exception e) {
throw new BuilderException("Error evaluating XPath. Cause: " + e, e);
}
}
三、XNode类
XNode类对应了配置文件中一个元素节点的信息。
1、 字段
/**
* org.w3c.dorn.Node对象
*/
private final Node node;
/**
* Node节点名称
*/
private final String name;
/**
* 节点的内容
*/
private final String body;
/**
* 节点属性集合
*/
private final Properties attributes;
/**
* 配置文件中<properties>节点下定义的键位对
*/
private final Properties variables;
/**
* XPathParser对象,当前XNode对象由此XPathParser对象生成
*/
private final XPathParser xpathParser;
2、 构造器
构造器主要实现对象的实例化、字段属性的赋值。其中attributes 属性字段通过parseAttributes()方法解析node对象来获取,主要保存了节点包含的所有属性的键值对,body属性字段通过parseBody()方法解析node对象来获取,主要处理当前节点的子元素,可能是文本内容,也可能是子标记,如果是文本内容,由getBodyData()方法处理,否则parseBody()方法处理。
在parseAttributes()方法和getBodyData()方法中,都调用了PropertyParser.parse()方法,主要实现了对这些内容可能包含的占位符进行处理。
public XNode(XPathParser xpathParser, Node node, Properties variables) {
this.xpathParser = xpathParser;
this.node = node;
this.name = node.getNodeName();
this.variables = variables;
this.attributes = parseAttributes(node);
this.body = parseBody(node);
}
private Properties parseAttributes(Node n) {
Properties attributes = new Properties();
NamedNodeMap attributeNodes = n.getAttributes();
if (attributeNodes != null) {
for (int i = 0; i < attributeNodes.getLength(); i++) {
Node attribute = attributeNodes.item(i);
String value = PropertyParser.parse(attribute.getNodeValue(), variables);
attributes.put(attribute.getNodeName(), value);
}
}
return attributes;
}
private String parseBody(Node node) {
String data = getBodyData(node);
if (data == null) {
NodeList children = node.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
Node child = children.item(i);
data = getBodyData(child);
if (data != null) {
break;
}
}
}
return data;
}
private String getBodyData(Node child) {
if (child.getNodeType() == Node.CDATA_SECTION_NODE
|| child.getNodeType() == Node.TEXT_NODE) {
String data = ((CharacterData) child).getData();
data = PropertyParser.parse(data, variables);
return data;
}
return null;
}
3、 newXNode()方法
根据Node对象,创建XNode对象实例。
public XNode newXNode(Node node) {
return new XNode(xpathParser, node, variables);
}
4、 evalXXX()方法
该系列方法就是通过xpathParser.evalXXX()方法获取当前节点中指定类型数据的方法。
5、 getXXXAttribute()、getXXXBody()方法
getXXXAttribute()该系列方法主要是获取当前节点指定类型属性的方法,getXXXBody()系列方法主要是获取当前节点指定类型内容的方法。
6、 getPath()方法
获取节点路径的方法。
public String getPath() {
StringBuilder builder = new StringBuilder();
Node current = node;
while (current != null && current instanceof Element) {
if (current != node) {
builder.insert(0, "/");
}
builder.insert(0, current.getNodeName());
current = current.getParentNode();
}
return builder.toString();
}
7、 getParent()方法
获取父节点,仅限于父节点是Element类型的对象时。
public XNode getParent() {
Node parent = node.getParentNode();
if (parent == null || !(parent instanceof Element)) {
return null;
} else {
return new XNode(xpathParser, parent, variables);
}
}
8、 getValueBasedIdentifier方法
基于标志符获取值,比如:employee[${id_var}]_height。
public String getValueBasedIdentifier() {
StringBuilder builder = new StringBuilder();
XNode current = this;
while (current != null) {
if (current != this) {
builder.insert(0, "_");
}
String value = current.getStringAttribute("id",
current.getStringAttribute("value",
current.getStringAttribute("property", null)));
if (value != null) {
value = value.replace('.', '_');
builder.insert(0, "]");
builder.insert(0,
value);
builder.insert(0, "[");
}
builder.insert(0, current.getName());
current = current.getParent();
}
return builder.toString();
}
9、 getChildrenAsProperties()方法
该方法是解析当前节点下所有子节点的属性值,并把其中name属性和value属性的属性值,转换成Properties形式的键值对。
public Properties getChildrenAsProperties() {
Properties properties = new Properties();
for (XNode child : getChildren()) {
String name = child.getStringAttribute("name");
String value = child.getStringAttribute("value");
if (name != null && value != null) {
properties.setProperty(name, value);
}
}
return pro
public List<XNode> getChildren() {
List<XNode> children = new ArrayList<XNode>();
NodeList nodeList = node.getChildNodes();
if (nodeList != null) {
for (int i = 0, n = nodeList.getLength(); i < n; i++) {
Node node = nodeList.item(i);
if (node.getNodeType() == Node.ELEMENT_NODE) {
children.add(new XNode(xpathParser, node, variables));
}
}
}
return children;
}
四、总结
Mybatis源码中解析器模块主要包括了XNode、XPathParser、PropertyParser、GenericTokenParser、TokenHandler、ParsingException等类或接口。其中,ParsingException异常类,比较简单没有具体分析。其他已经逐步分析了,这些类或接口主要用解析XML和文本中占位符的处理。前面这些内容只是简单分析了代码结构,并且分析了每个类中每个属性字段或方法的作用,可以从中了解Mybatis解析器的基本用法。下一步,将思考这些类或接口从设计理念上的一些东西,期待中。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/68917.html

