
你会得到一个双链表,其中包含的节点有一个下一个指针、一个前一个指针和一个额外的 子指针 。这个子指针可能指向一个单独的双向链表,也包含这些特殊的节点。这些子列表可以有一个或多个自己的子列表,以此类推,以生成如下面的示例所示的 多层数据结构 。
给定链表的头节点 head ,将链表 扁平化 ,以便所有节点都出现在单层双链表中。让 curr 是一个带有子列表的节点。子列表中的节点应该出现在扁平化列表中的 curr 之后 和 curr.next 之前 。
返回 扁平列表的 head 。列表中的节点必须将其 所有 子指针设置为 null 。
示例 1:
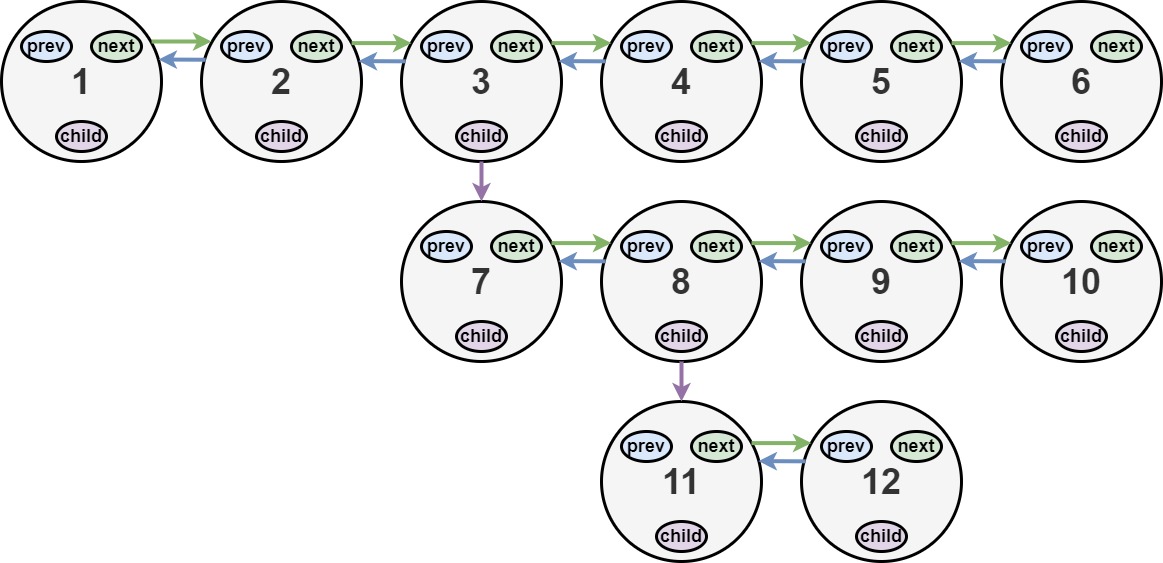

输入:head = [1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12]
输出:[1,2,3,7,8,11,12,9,10,4,5,6]
解释:输入的多级列表如上图所示。
扁平化后的链表如下图:

示例 2:
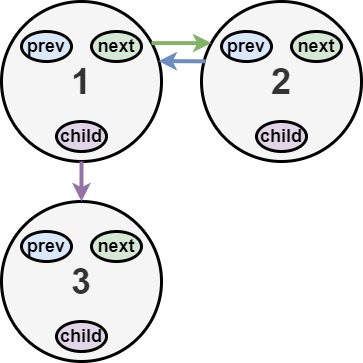
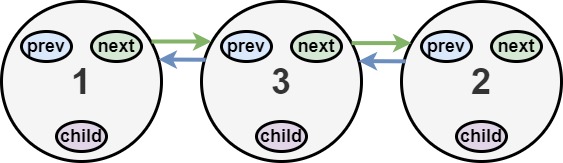
输入:head = [1,2,null,3]
输出:[1,3,2]
解释:输入的多级列表如上图所示。
扁平化后的链表如下图:
示例 3:
输入:head = []
输出:[]
说明:输入中可能存在空列表。
提示:
- 节点数目不超过
1000 1 <= Node.val <= 105
/*
// Definition for a Node.
class Node {
public int val;
public Node prev;
public Node next;
public Node child;
};
*/
class Solution {
public Node flatten(Node head) {
if(head==null) return head;
Stack<Node> stack = new Stack<Node>();
Node node = head;
while(node!=null)
{
if(node.child!=null)
{
if(node.next!=null)
{
stack.push(node.next);
node.child.prev = node;
node.next = node.child;
node.child = null;
node = node.next;
}
else
{
node.next = node.child;
node.child.prev = node;
node.child = null;
node = node.next;
}
}
else if(node.next!=null) node = node.next;
else if(node.next==null && stack.isEmpty()==false)
{
Node n = stack.pop();
node.next = n;
n.prev = node;
node = n;
}
else return head;
}
return head;
}
}
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/68956.html

