
文章目录
1、HashMap的数据结构
数据结构中有数组和链表来实现对数据的存储。
-
数组
数组存储区间是连续的,占用内存严重。数组的特点是:寻址容易,插入和删除困难; -
链表
链表存储区间离散,占用内存比较宽松。链表的特点是:寻址困难,插入和删除容易。 -
HashMap数据结构
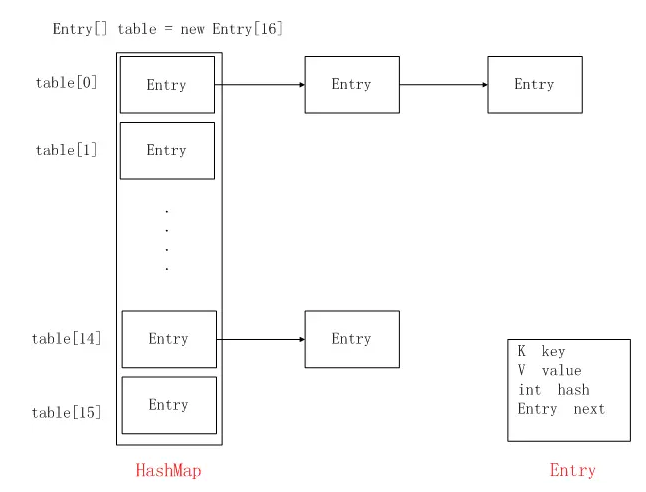

根据图片可以很直观的看到,HashMap是由数组和链表两种数据结构组合而成的,其节点类型均为名为Entry的类。采用这种数据结果,即是综合了两种数据结果的优点,既能便于读取数据,也能方便的进行数据的增删。
-
哈希值
Hash是一种算法,能将一个任意长度的二进制值通过一个映射关系转换成一个固定长度的二进制值。在HashMap中,哈希算法主要是用于根据key的值算出存放数组的index值。HashMap中的存储都是根据key的哈希值有关的。
哈希算法又被称为散列的过程,那么什么是散列呢?散列即把数据均匀的存放到数组中的各个位置,从而尽量避免出现多个数据存放在一块区间内。优秀的哈希算法应该具备以下两点:
- 保证散列值非常均匀
- 保证冲突极少出现
哈希函数有很多种,在这里我以除留取余法(取模)为例,首先定义一个数组的长度,假设为16。那么此时的索引为key摸于m,m的取值规则是比数组长度小的最大质数。在这个情况下m为13。由于这种算法会导致这样的情况出现,即不同的key经过哈希运算之后得到了一样的index,如key为2和15的index值都为2,那么此时就需要我们处理冲突了。
2、java实现HashMap
2.1Map接口
HashMap的顶层接口是Map,那么我们自己实现的Map也需要一个接口,在这里我定义接口的名称为MyMap。这个接口中应该含有的方法包括:
-
put(K k,V v)
-
get(K k)
-
size()
-
和一个内部接口:
Entry
这个内部接口中包含两个方法:
getKey()
getValue()
package map;
public interface MyMap<K, V> {
/**
* put方法
*/
V put(K k, V v);
/**
* get方法
*/
V get(K k);
/**
* map大小
*/
int size();
/**
* Entry内部接口
*/
interface Entry<K, V> {
/**
* 根据entry对象获取key值
*/
K getKey();
/**
* 根据entry对象获取value值
*/
V getValue();
}
}
2.2 内部类Entry的实现
接口设计完毕之后,我们需要创建一个类来实现这个接口的方法。我创建了一个名为MyHashMap的类实现MyMap接口。
这里我们需要一个内部类来实现MyMap的内部接口,内部类的实例对象即数组中存储的entry对象,所以我们需要定义三个成员变量,分别是K,V和Next。next的类型就是entry本身,因为它指向的是下一个entry对象。
内部类代码:
public class MyHashMap<K, V> implements MyMap<K, V> {
/**
* 用内部类实现myMap的内部接口
*/
class Entry<K, V> implements MyMap.Entry<K, V> {
K k;
V v;
Entry<K, V> next;
public Entry(K k, V v, Entry next) {
this.k = k;
this.v = v;
this.next = next;
}
@Override
public K getKey() {
return k;
}
@Override
public V getValue() {
return v;
}
}
}
2.3 定义成员变量
HashMap中含有以下几个成员变量:
- 默认数组长度
- 默认负载因子
- Entry数组
- HashMap的大小
//默认数组大小,初始大小为16
private static int defaultLength = 16;
//默认负载因子,为0.75
private static double defaultLoader = 0.75;
//Entry数组
private Entry<K, V>[] table = null;
//HashMap的大小
private int size = 0;
2.4 定义构造方法
在HashMap中默认数组长度和默认负载因子都是可以自定义的,那么我们定义一个可以自定义数组长度和负载因子的构造方法。
自定义长度和负载因子:
public MyHashMap(int length, double loader) {
defaultLength = length;
defaultLoader = loader;
// 初始化数组
table = new Entry[defaultLength];
}
默认:
public MyHashMap() {
this(defaultLength, defaultLoader);
}
2.5 定义哈希函数
哈希函数我们使用除留取余法。定义一个整型m,m的取值应该是一个比数组长度小的最大质数,为了简化算法我取数组的长度作为m的值。以key的哈希值模于m,得到index的值并且返回。
本例为了方便理解简单举例,如果需要分布更均匀些,请自己写。
/**
* 自定义哈希算法:根据key的哈希值得到一个index索引
* 即存放到数组中的下标
*
* @param k
* @return
*/
private int getIndex(K k) {
int m = defaultLength;
int index = k.hashCode() % m;// 取余(取模)
return index >= 0 ? index : -index;
}
2.6 实现put方法
我们需要通过哈希算法得到数组的下标,然后把一个包含键值对以及next指针的entry对象存到该位置中。
@Override
public V put(K k, V v) {
// 判断size是否达到扩容的标准
if (size >= defaultLength * defaultLoader) {
expand();
}
// 根据key和哈希算法算出数组下标
int index = getIndex(k);
System.out.println("下标为:" + index);
Entry<K, V> entry = table[index];
if ("key30".equals(k)) {// 无关实现,只是为了方便打断点。
System.out.println("打个断点");
}
// 判断entry是否为空
if (entry == null) {
/*
* 如果entry为空,则代表当前位置没有数据。 new一个entry对象,内部存放key,value。
* 此时next指针没有值,因为这个位置上只有一个entry对象
*/
table[index] = new Entry(k, v, null);
// map的大小加1
size++;
} else {
/*
* 如果entry不为空,则代表当前位置已经有数据了。 new一个entry对象,内部存放key,value。
* 把next指针设置为原本的entry对象并且把数组中的数据替换为新的entry对象
*/
table[index] = new Entry<K, V>(k, v, entry);
}
return table[index].getValue();
}
2.6.1 实现扩容方法
当数组大小已经超过负载的时候,需要对进行扩容,扩容后还需要将原先的值重新排列,以确保值分布均匀。此处重新散列我们借助了集合来实现。
/**
* 数组扩容
*/
private void expand() {
// 创建一个大小是原来两倍的entry数组
Entry<K, V>[] newTable = new Entry[2 * defaultLength];
// 重新散列
rehash(newTable);
}
// 重新散列的过程
private void rehash(Entry<K, V>[] newTable) {
System.out.println("重新散列开始*****");
// 创建一个list用于装载HashMap中所有的entry对象
List<Entry<K, V>> list = new ArrayList<Entry<K, V>>();
// 遍历整个数组
for (int i = 0; i < table.length; i++) {
// 如果数组中的某个位置没有数据,则跳过
if (table[i] == null) {
continue;
}
// 通过递归的方式将所有的entry对象装载到list中
findEntryByNext(table[i], list);
}
table = newTable;
if (list.size() > 0) {
// 把size重置
size = 0;
// 把默认长度设置为原来的两倍
defaultLength = 2 * defaultLength;
for (Entry<K, V> entry : list) {
if (entry.next != null) {
// 把所有entry的next指针置空
entry.next = null;
}
// 对新table进行散列
put(entry.getKey(), entry.getValue());
}
}
System.out.println("重新散列完成*****");
}
private void findEntryByNext(Entry<K, V> entry, List<Entry<K, V>> list) {
if (entry != null && entry.next != null) {
list.add(entry);
// 递归调用
findEntryByNext(entry.next, list);
} else {
list.add(entry);
}
}
2.7 实现get方法
get方法先去获取哈希值,而后再根据得到得位置来遍历链表,以确保找到key。
@Override
public V get(K k) {
// 获取此key对应的entry对象所存放的索引index
int index = getIndex(k);
// 非空判断
if (table[index] == null) {
return null;
}
// 调用方法找到真正的value值并返回。
return findValueByEqualKey(k, table[index]);
}
2.7.1 get的具体实现
/**
*
* 通过递归比较key值的方式找到真正我们要找的value值
*
* @param k
* @param entry
* @return
*/
private V findValueByEqualKey(K k, Entry<K, V> entry) {
/*
* 如果传进来的key等于这个entry的key值,说明这个就是我们要找的entry对象 那么直接返回这个entry的value
*/
if (k == entry.getKey() || k.equals(entry.getKey())) {
return entry.getValue();
} else {
/*
* 如果不相等,说明这个不是我们要找的entry对象, 通过递归的方式去比较它的next指针中的entry的key值,来找到真正的entry对象
*/
if (entry.next != null) {
return findValueByEqualKey(k, entry.next);
}
}
return entry.getValue();
}
注
- 文章是个人知识点整理总结,如有错误和不足之处欢迎指正。
- 如有疑问、或希望与笔者探讨技术问题(包括但不限于本章内容),欢迎添加笔者微信(o815441)。请备注“探讨技术问题”。欢迎交流、一起进步。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/69852.html

