

背景介绍
最近的docker容器经常被kill掉,k8s中该节点的pod也被驱赶。
我有一个在主机中运行的Docker容器(也有在同一主机中运行的其他容器)。该Docker容器中的应用程序将会计算数据和流式处理,这可能会消耗大量内存。
该容器会不时退出。我怀疑这是由于内存不足,但不是很确定。我需要找到根本原因的方法。那么有什么方法可以知道这个集装箱的死亡发生了什么?
容器层级判断检测
提到docker logs $container_id查看该应用程序的输出。这永远是我要检查的第一件事。接下来,您可以运行docker inspect $container_id以查看状态的详细信息,例如:
"State": {
"Status": "exited",
"Running": false,
"Paused": false,
"Restarting": false,
"OOMKilled": false,
"Dead": false,
"Pid": 0,
"ExitCode": 2,
"Error": "",
"StartedAt": "2016-06-28T21:26:53.477229071Z",
"FinishedAt": "2016-06-28T21:26:53.478066987Z"
}
重要的一行是“ OOMKilled”,如果您超出了容器的内存限制,并且Docker杀死了您的应用程序,则该行将为true。您可能还需要查找退出代码,以查看其是否标识出您的应用退出的原因。
-
Docker内部,这仅表示docker本身是否会杀死您的进程,并要求您在容器上设置内存限制。
-
Docker外部,如果主机本身内存不足,Linux内核可以销毁进程。发生这种情况时,Linux通常会在/ var / log中写入日志。使用Windows和Mac上的Docker Desktop,您可以在docker设置中调整分配给嵌入式Linux VM的内存。
- 可以通过阅读日志来了解容器内的进程是否被OOM杀死。OOMkill是由内核启动的,因此每次发生时,都会在中包含很多行/var/log/kern.log,例如:
python invoked oom-killer: gfp_mask=0x14000c0(GFP_KERNEL), nodemask=(null), order=0, oom_score_adj=995
oom_kill_process+0x22e/0x450
Memory cgroup out of memory: Kill process 31204 (python) score 1994 or sacrifice child
Killed process 31204 (python) total-vm:7350860kB, anon-rss:4182920kB, file-rss:2356kB, shmem-rss:0kB
Linux操作系统的进程服务发生被killed的原因是什么
在Linux中,经常会遇到一些重要的进程无缘无故就被killed,而大多数的经验之谈就是系统资源不足或内存不足所导致的。
当Linux系统资源不足时,Linux内核可以决定终止一个或多个进程,内存不足时会在系统的物理内存耗尽时触发OOM killed,可以利用“dmesg | tail -N”命令来查看killed的近N行日志。

常规的宕机监控之类
在服务宕机或者重启之前我们的常规操作就是采用ps指令判定服务的增长趋势以及展示真实使用的资源的大小的前几位排名。
- Linux下显示系统进程的命令ps,最常用的有ps -ef 和ps aux。这两个到底有什么区别呢?
ps -ef指令代表着’SystemV风格’,而ps aux代表着’BSD风格‘。

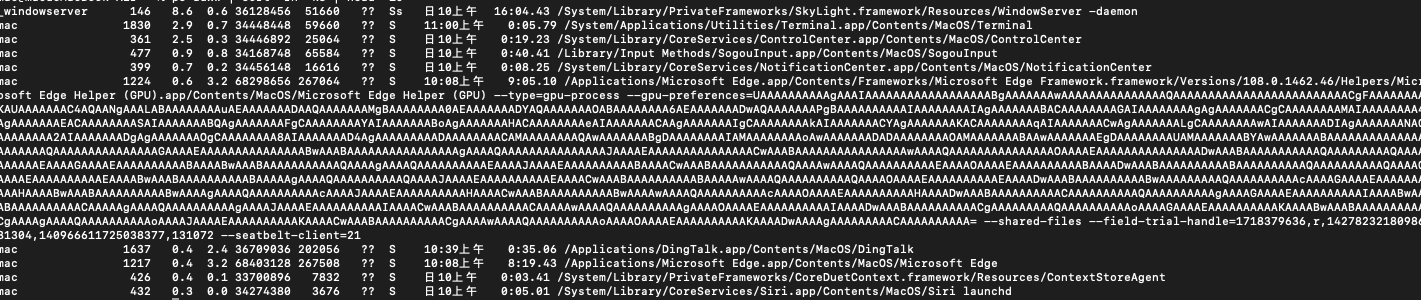
由上图所示,可以分析出对应的数据结构模型。
USER //用户名
%CPU //进程占用的CPU百分比
%MEM //占用内存的百分比
VSZ //该进程使用的虚拟內存量(KB)
RSS //该进程占用的固定內存量(KB)resident set size
STAT //进程的状态
START //该进程被触发启动时间
TIME //该进程实际使用CPU运行的时间
其中CPU算是第3个位置、内存MEM算是第4个位置,虚拟内存VSZ是第5个位置,记住这个后面我们会使用这个方式进行排序。
查看当前系统内CPU占用最多的前10个进程(栏位属于第3个)
ps auxw | sort -rn -k3 | head -10
ps auxw指令(BSD风格)
- u:以用户为主的格式来显示程序状况
- x:显示所有程序,不以终端机来区分
- w:采用宽阔的格式来显示程序状况
sort排序指令
sort -rn -k5
-n是按照数字大小排序(-n 这代表着排除n行的操作处理),-r是以相反顺序,-k是指定需要排序的栏位
ps auxw | head -1
内存消耗最多的前10个进程(栏位属于第4个)
ps auxw | head -1;ps auxw|sort -rn -k4|head -10
虚拟内存使用最多的前10个进程(栏位属于第5个)
ps auxw|head -1;ps auxw|sort -rn -k5|head -10
去掉x参数的结果
ps auw | head -1; ps auw|sort -rn -k4 | head -10
stat取值含义

D //无法中断的休眠状态(通常 IO 的进程);
R //正在运行可中在队列中可过行的;
S //处于休眠状态;
T //停止或被追踪;
W //进入内存交换 (从内核2.6开始无效);
X //死掉的进程 (基本很少见);
Z //僵尸进程;
< //优先级高的进程
N //优先级较低的进程
L //有些页被锁进内存;
s //进程的领导者(在它之下有子进程);
l //多线程,克隆线程(使用 CLONE_THREAD, 类似 NPTL pthreads);
+ //位于后台的进程组;
dmesg的命令分析
有几个工具/脚本/命令 可以更轻松地从该虚拟设备读取数据,其中最常见的是 dmesg 和 journalctl。
输入dmesg指令进行egrep正则表达式匹配killed的进程信息,将输出对应的进程信息。
dmesg | egrep -i -B100 'killed process'
或
dmesg | grep -i -B100 'killed process'
以上的指令就可以输出最近killed的信息,其中-B100,表示 ‘killed process’之前的100行内容,与head的指令非常的相似。

如果我们看到了oom-kill的字样之后,就可以判断它是被内存不足所导致的kill,oom-kill之后,就是描述那个被killed的程序的pid和uid。
Out of memory: Killed process 1138439 (python3) total-vm:8117956kB, anon-rss:5649844kB,内存不够
total_vm和rss的指标值

-
total_vm:总共使用的虚拟内存 Virtual memory use (in 4 kB pages),8117956/1024(得到MB)/1024(得到GB)=7.741GB
-
rss:常驻内存使用Resident memory use (in 4 kB pages) 5649844/1024/1024=5.388GB
案例1:查看到pod被驱赶的原因
[3899860.525793] Out of memory: Kill process 64058 (nvidia-device-p) score 999 or sacrifice child
[3899860.526961] Killed process 64058 (nvidia-device-p) total-vm:126548kB, anon-rss:2080kB, file-rss:0kB, shmem-rss:0kB
案例2:查看到docker容器被kill 的原因
[3899859.737598] Out of memory: Kill process 27562 (jupyter-noteboo) score 1000 or sacrifice child
[3899859.738640] Killed process 27562 (jupyter-noteboo) total-vm:215864kB, anon-rss:45928kB, file-rss:0kB, shmem-rss:0kB
journalctl命令 – 查看指定的日志信息
当内存不足时,内核会将相关信息记录到内核日志缓冲区中,该缓冲区可通过 /dev/kmsg 获得。除了上面的dmesg之外,还有一个journalctl。
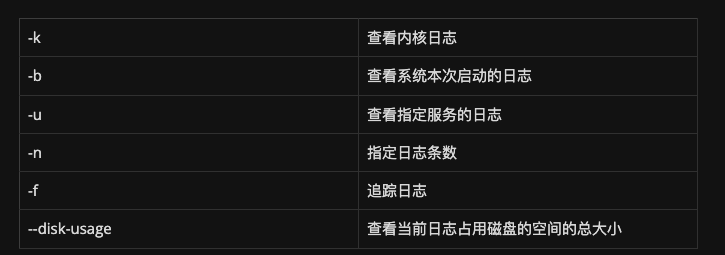
语法格式: journalctl [参数]
常用参数:
查看Killed日志
使用sudo dmesg | tail -7命令(任意目录下,不需要进入log目录,这应该是最简单的一种)而journalctl命令来自于英文词组“journal control”的缩写,其功能是用于查看指定的日志信息。
journalctl指令介绍
在RHEL7/CentOS7及以后版本的Linux系统中,Systemd服务统一管理了所有服务的启动日志,带来的好处就是可以只用journalctl一个命令,查看到全部的日志信息了。
查看所有日志(默认情况下 ,只保存本次启动的日志)
journalctl
查看内核日志(不显示应用日志)
journalctl -k
查看系统本次启动的日志
journalctl -b
journalctl -b -0
查看上一次启动的日志(需更改设置)
journalctl -b -1
查看指定时间的日志
journalctl --since=“2021-09-16 14:22:02”
journalctl --since “30 min ago”
journalctl --since yesterday
journalctl --since “2021-01-01” --until “2021-09-16 13:40”
journalctl --since 07:30 --until “2 hour ago”
显示尾部的最新10行日志
journalctl -n
显示尾部指定行数的日志
journalctl -n 15
实时滚动显示最新日志
journalctl -f
查看指定服务的日志
journalctl /usr/lib/systemd/systemd
比如查看docker服务的日志
systemctl status docker
查看某个 Unit 的日志
journalctl -u nginx.service
journalctl -u nginx.service --since today
实时滚动显示某个 Unit 的最新日志
journalctl -u nginx.service -f
合并显示多个 Unit 的日志
$ journalctl -u nginx.service -u php-fpm.service --since today
本文来自博客园,作者:洛神灬殇,转载请注明原文链接:https://www.cnblogs.com/liboware/p/16984760.html,任何足够先进的科技,都与魔法无异。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/70065.html

