
前提概述
Java 7开始引入了一种新的Fork/Join线程池,它可以执行一种特殊的任务:把一个大任务拆成多个小任务并行执行。
我们举个例子:如果要计算一个超大数组的和,最简单的做法是用一个循环在一个线程内完成:
算法原理介绍
相信大家此前或多或少有了解到ForkJoin框架,ForkJoin框架其实就是一个线程池ExecutorService的实现,通过工作窃取(work-stealing)算法,获取其他线程中未完成的任务来执行。可以充分利用机器的多处理器优势,利用空闲的线程去并行快速完成一个可拆分为小任务的大任务,类似于分治算法。
实现达成目标
-
ForkJoin的目标,就是利用所有可用的处理能力来提高程序的响应和性能。本文将介绍ForkJoin框架,依次介绍基础特性、案例使用、源码剖析和实现亮点。
-
java.util.concurrent.ForkJoinPool由Java大师Doug Lea主持编写,它可以将一个大的任务拆分成多个子任务进行并行处理,最后将子任务结果合并成最后的计算结果,并进行输出。
基本使用
入门例子,用Fork/Join框架使用示例,在这个示例中我们计算了1-5000累加后的值:
public class TestForkAndJoinPlus {
private static final Integer MAX = 400;
static class WorkTask extends RecursiveTask<Integer> {
// 子任务开始计算的值
private Integer startValue;
// 子任务结束计算的值
private Integer endValue;
public WorkTask(Integer startValue , Integer endValue) {
this.startValue = startValue;
this.endValue = endValue;
}
@Override
protected Integer compute() {
// 如果小于最小分片阈值,则说明要进行相关的数据操作
// 可以正式进行累加计算了
if(endValue - startValue < MAX) {
System.out.println("开始计算的部分:startValue = " + startValue + ";endValue = " + endValue);
Integer totalValue = 0;
for(int index = this.startValue ; index <= this.endValue ; index++) {
totalValue += index;
}
return totalValue;
}
// 否则再进行任务拆分,拆分成两个任务
else {
// 因为采用二分法,拆分,所以进行1/2切分数据量
WorkTask subTask1 = new WorkTask(startValue, (startValue + endValue) / 2);
subTask1.fork();//进行拆分机制控制
WorkTask subTask2 = new WorkTask((startValue + endValue) / 2 + 1 , endValue);
subTask2.fork();
return subTask1.join() + subTask2.join();
}
}
}
public static void main(String[] args) {
// 这是Fork/Join框架的线程池
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask<Integer> taskFuture = pool.submit(new MyForkJoinTask(1,1001));
try {
Integer result = taskFuture.get();
System.out.println("result = " + result);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace(System.out);
}
}
}
对此我封装了一个框架集合,基于JDK1.8+中的Fork/Join框架实现,参考的Fork/Join框架主要源代码也基于JDK1.8+。
WorkTaskCallable实现抽象模型层次操作转换
@Accessors(chain = true)
public class WorkTaskCallable<T> extends RecursiveTask<T> {
/**
* 断言操作控制
*/
@Getter
private Predicate<T> predicate;
/**
* 执行参数化分割条件
*/
@Getter
private T splitParam;
/**
* 操作拆分方法操作机制
*/
@Getter
private Function<Object,Object[]> splitFunction;
/**
* 操作合并方法操作机制
*/
@Getter
private BiFunction<Object,Object,T> mergeFunction;
/**
* 操作处理机制
*/
@Setter
@Getter
private Function<T,T> processHandler;
/**
* 构造器是否进行分割操作
* @param predicate 判断是否进行下一步分割的条件关系
* @param splitParam 分割参数
* @param splitFunction 分割方法
* @param mergeFunction 合并数据操作
*/
public WorkTaskCallable(Predicate predicate,T splitParam,Function<Object,Object[]> splitFunction,BiFunction<Object,Object,T> mergeFunction,Function<T,T> processHandler){
this.predicate = predicate;
this.splitParam = splitParam;
this.splitFunction = splitFunction;
this.mergeFunction = mergeFunction;
this.processHandler = processHandler;
}
/**
* 实际执行调用操作机制
* @return
*/
@Override
protected T compute() {
if(predicate.test(splitParam)){
Object[] result = splitFunction.apply(splitParam);
WorkTaskCallable workTaskCallable1 = new WorkTaskCallable(predicate,result[0],splitFunction,mergeFunction,processHandler);
workTaskCallable1.fork();
WorkTaskCallable workTaskCallable2 = new WorkTaskCallable(predicate,result[1],splitFunction,mergeFunction,processHandler);
workTaskCallable2.fork();
return mergeFunction.apply(workTaskCallable1.join(),workTaskCallable2.join());
}else{
return processHandler.apply(splitParam);
}
}
}
ArrayListWorkTaskCallable实现List集合层次操作转换
/**
* @project-name:wiz-shrding-framework
* @package-name:com.wiz.sharding.framework.boot.common.thread.forkjoin
* @author:LiBo/Alex
* @create-date:2021-09-09 17:26
* @copyright:libo-alex4java
* @email:liboware@gmail.com
* @description:
*/
public class ArrayListWorkTaskCallable extends WorkTaskCallable<List>{
static Predicate<List> predicateFunction = param->param.size() > 3;
static Function<List,List[]> splitFunction = (param)-> {
if(predicateFunction.test(param)){
return new List[]{param.subList(0,param.size()/ 2),param.subList(param.size()/2,param.size())};
}else{
return new List[]{param.subList(0,param.size()+1),Lists.newArrayList()};
}
};
static BiFunction<List,List,List> mergeFunction = (param1,param2)->{
List datalist = Lists.newArrayList();
datalist.addAll(param2);
datalist.addAll(param1);
return datalist;
};
/**
* 构造器是否进行分割操作
* @param predicate 判断是否进行下一步分割的条件关系
* @param splitParam 分割参数
* @param splitFunction 分割方法
* @param mergeFunction 合并数据操作
*/
public ArrayListWorkTaskCallable(Predicate<List> predicate, List splitParam, Function splitFunction, BiFunction mergeFunction,
Function<List,List> processHandler) {
super(predicate, splitParam, splitFunction, mergeFunction,processHandler);
}
public ArrayListWorkTaskCallable(List splitParam, Function splitFunction, BiFunction mergeFunction,
Function<List,List> processHandler) {
super(predicateFunction, splitParam, splitFunction, mergeFunction,processHandler);
}
public ArrayListWorkTaskCallable(Predicate<List> predicate,List splitParam,Function<List,List> processHandler) {
this(predicate, splitParam, splitFunction, mergeFunction,processHandler);
}
public ArrayListWorkTaskCallable(List splitParam,Function<List,List> processHandler) {
this(predicateFunction, splitParam, splitFunction, mergeFunction,processHandler);
}
public static void main(String[] args){
List dataList = Lists.newArrayList(0,1,2,3,4,5,6,7,8,9);
ForkJoinPool forkJoinPool = ForkJoinPool.commonPool();
ForkJoinTask<List> forkJoinResult = forkJoinPool.submit(new ArrayListWorkTaskCallable(dataList,param->Lists.newArrayList(param.size())));
try {
System.out.println(forkJoinResult.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
ForkJoin代码分析
ForkJoinPool构造函数
/**
* Creates a {@code ForkJoinPool} with parallelism equal to {@link
* java.lang.Runtime#availableProcessors}, using the {@linkplain
* #defaultForkJoinWorkerThreadFactory default thread factory},
* no UncaughtExceptionHandler, and non-async LIFO processing mode.
*
* @throws SecurityException if a security manager exists and
* the caller is not permitted to modify threads
* because it does not hold {@link
* java.lang.RuntimePermission}{@code ("modifyThread")}
*/
public ForkJoinPool() {
this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()),
defaultForkJoinWorkerThreadFactory, null, false);
}
/**
* Creates a {@code ForkJoinPool} with the indicated parallelism
* level, the {@linkplain
* #defaultForkJoinWorkerThreadFactory default thread factory},
* no UncaughtExceptionHandler, and non-async LIFO processing mode.
*
* @param parallelism the parallelism level
* @throws IllegalArgumentException if parallelism less than or
* equal to zero, or greater than implementation limit
* @throws SecurityException if a security manager exists and
* the caller is not permitted to modify threads
* because it does not hold {@link
* java.lang.RuntimePermission}{@code ("modifyThread")}
*/
public ForkJoinPool(int parallelism) {
this(parallelism, defaultForkJoinWorkerThreadFactory, null, false);
}
/**
* Creates a {@code ForkJoinPool} with the given parameters.
*
* @param parallelism the parallelism level. For default value,
* use {@link java.lang.Runtime#availableProcessors}.
* @param factory the factory for creating new threads. For default value,
* use {@link #defaultForkJoinWorkerThreadFactory}.
* @param handler the handler for internal worker threads that
* terminate due to unrecoverable errors encountered while executing
* tasks. For default value, use {@code null}.
* @param asyncMode if true,
* establishes local first-in-first-out scheduling mode for forked
* tasks that are never joined. This mode may be more appropriate
* than default locally stack-based mode in applications in which
* worker threads only process event-style asynchronous tasks.
* For default value, use {@code false}.
* @throws IllegalArgumentException if parallelism less than or
* equal to zero, or greater than implementation limit
* @throws NullPointerException if the factory is null
* @throws SecurityException if a security manager exists and
* the caller is not permitted to modify threads
* because it does not hold {@link
* java.lang.RuntimePermission}{@code ("modifyThread")}
*/
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode) {
this(checkParallelism(parallelism),
checkFactory(factory),
handler,
(asyncMode ? FIFO_QUEUE : LIFO_QUEUE),
"ForkJoinPool-" + nextPoolId() + "-worker-");
checkPermission();
}
/**
* Creates a {@code ForkJoinPool} with the given parameters, without
* any security checks or parameter validation. Invoked directly by
* makeCommonPool.
*/
private ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
int mode,
String workerNamePrefix) {
this.workerNamePrefix = workerNamePrefix;
this.factory = factory;
this.ueh = handler;
this.mode = (short)mode;
this.parallelism = (short)parallelism;
long np = (long)(-parallelism); // offset ctl counts
this.ctl = ((np << AC_SHIFT) & AC_MASK) | ((np << TC_SHIFT) & TC_MASK);
}
-
parallelism:可并行级别,Fork/Join框架将依据这个并行级别的设定,决定框架内并行执行的线程数量。并行的每一个任务都会有一个线程进行处理,但是千万不要将这个属性理解成Fork/Join框架中最多存在的线程数量。
-
factory:当Fork/Join框架创建一个新的线程时,同样会用到线程创建工厂。只不过这个线程工厂不再需要实现ThreadFactory接口,而是需要实现ForkJoinWorkerThreadFactory接口。后者是一个函数式接口,只需要实现一个名叫newThread的方法。
在Fork/Join框架中有一个默认的ForkJoinWorkerThreadFactory接口实现:DefaultForkJoinWorkerThreadFactory。
-
handler:异常捕获处理器。当执行的任务中出现异常,并从任务中被抛出时,就会被handler捕获。
-
asyncMode:这个参数也非常重要,从字面意思来看是指的异步模式,它并不是说Fork/Join框架是采用同步模式还是采用异步模式工作。Fork/Join框架中为每一个独立工作的线程准备了对应的待执行任务队列,这个任务队列是使用数组进行组合的双向队列。即是说存在于队列中的待执行任务,即可以使用先进先出的工作模式,也可以使用后进先出的工作模式。
-
先进先出
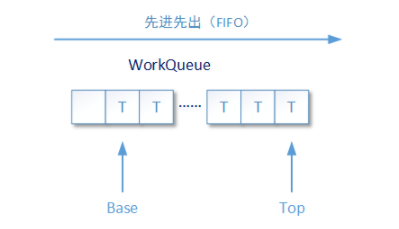

-
后进先出
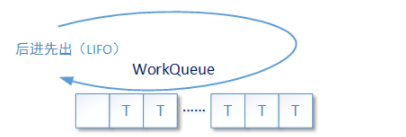
-
当asyncMode设置为true的时候,队列采用先进先出方式工作;反之则是采用后进先出的方式工作,该值默认为false
- asyncMode ? FIFO_QUEUE : LIFO_QUEUE,
-
需要注意点
-
ForkJoinPool 一个构造函数只带有parallelism参数,既是可以设定Fork/Join框架的最大并行任务数量;另一个构造函数则不带有任何参数,对于最大并行任务数量也只是一个默认值——当前操作系统可以使用的CPU内核数量(Runtime.getRuntime().availableProcessors())。实际上ForkJoinPool还有一个私有的、原生构造函数,之上提到的三个构造函数都是对这个私有的、原生构造函数的调用。
-
如果你对Fork/Join框架没有特定的执行要求,可以直接使用不带有任何参数的构造函数。也就是说推荐基于当前操作系统可以使用的CPU内核数作为Fork/Join框架内最大并行任务数量,这样可以保证CPU在处理并行任务时,尽量少发生任务线程间的运行状态切换(实际上单个CPU内核上的线程间状态切换基本上无法避免,因为操作系统同时运行多个线程和多个进程)。
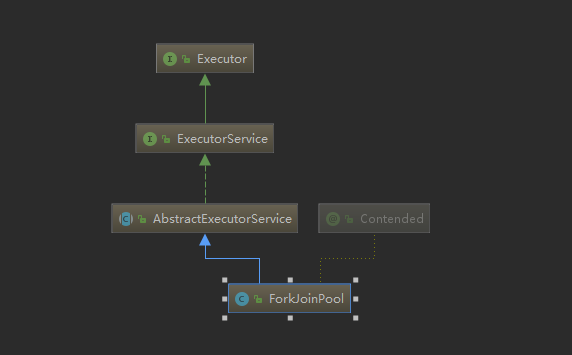
-
从上面的的类关系图可以看出来,ForkJoin框架的核心是ForkJoinPool类,基于AbstractExecutorService扩展(@sun.misc.Contended注解)。
-
ForkJoinPool中维护了一个队列数组WorkQueue[],每个WorkQueue维护一个ForkJoinTask数组和当前工作线程。ForkJoinPool实现了工作窃取(work-stealing)算法并执行ForkJoinTask。
ForkJoinPool类的属性介绍
-
ADD_WORKER: 100000000000000000000000000000000000000000000000 -> 1000 0000 0000 0000,用来配合ctl在控制线程数量时使用
-
ctl: 控制ForkJoinPool创建线程数量,(ctl & ADD_WORKER) != 0L 时创建线程,也就是当ctl的第16位不为0时,可以继续创建线程
-
defaultForkJoinWorkerThreadFactory: 默认线程工厂,默认实现是DefaultForkJoinWorkerThreadFactory
-
runState: 全局锁控制,全局运行状态
-
workQueues: 工作队列数组WorkQueue[]
-
config: 记录并行数量和ForkJoinPool的模式(异步或同步)
WorkQueue类
-
qlock: 并发控制,put任务时的锁控制
-
array: 任务数组ForkJoinTask<?>[]
-
pool: ForkJoinPool,所有线程和WorkQueue共享,用于工作窃取、任务状态和工作状态同步
-
base: array数组中取任务的下标
-
top: array数组中放置任务的下标
-
owner: 所属线程,ForkJoin框架中,只有一个WorkQueue是没有owner的,其他的均有具体线程owner
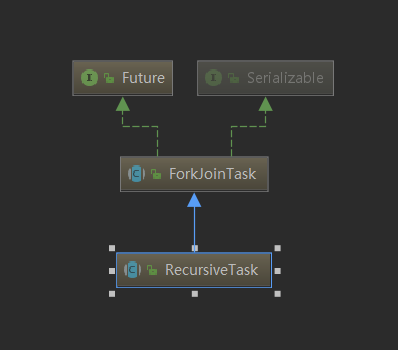
ForkJoinTask是能够在ForkJoinPool中执行的任务抽象类,父类是Future,具体实现类有很多,这里主要关注RecursiveAction和RecursiveTask。
- RecursiveAction是没有返回结果的任务
- RecursiveTask是需要返回结果的任务。
ForkJoinTask类属性的介绍
status: 任务的状态,对其他工作线程和pool可见,运行正常则status为负数,异常情况为正数。
ForkJoinTask功能介绍
-
ForkJoinTask任务是一种能在Fork/Join框架中运行的特定任务,也只有这种类型的任务可以在Fork/Join框架中被拆分运行和合并运行。
-
ForkJoinWorkerThread线程是一种在Fork/Join框架中运行的特性线程,它除了具有普通线程的特性外,最主要的特点是每一个ForkJoinWorkerThread线程都具有一个独立的任务等待队列(work queue),这个任务队列用于存储在本线程中被拆分的若干子任务。
只需要实现其compute()方法,在compute()中做最小任务控制,任务分解(fork)和结果合并(join)。
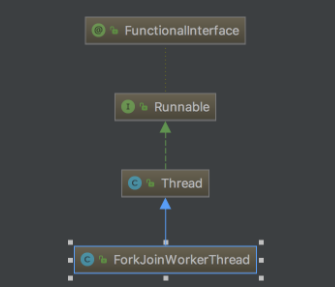
ForkJoinPool中执行的默认线程是ForkJoinWorkerThread,由默认工厂产生,可以自己重写要实现的工作线程。同时会将ForkJoinPool引用放在每个工作线程中,供工作窃取时使用。
ForkJoinWorkerThread类属性介绍
- pool: ForkJoinPool,所有线程和WorkQueue共享,用于工作窃取、任务状态和工作状态同步。
- workQueue: 当前线程的任务队列,与WorkQueue的owner呼应。
简易执行图
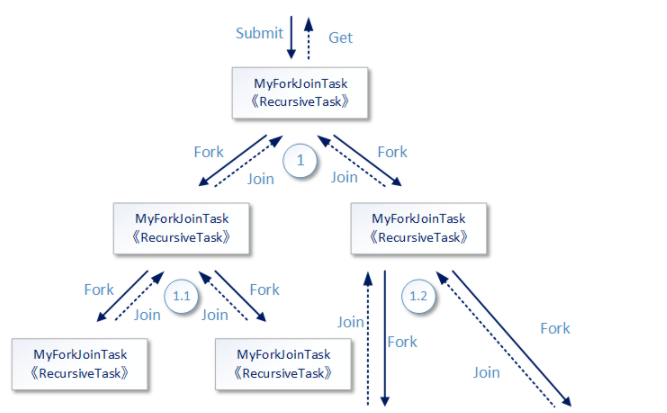
实际上Fork/Join框架的内部工作过程要比这张图复杂得多,例如如何决定某一个recursive task是使用哪条线程进行运行;再例如如何决定当一个任务/子任务提交到Fork/Join框架内部后,是创建一个新的线程去运行还是让它进行队列等待。
逻辑模型图(盗一张图:)
 ()
()
fork方法和join方法
Fork/Join框架中提供的fork方法和join方法,可以说是该框架中提供的最重要的两个方法,它们和parallelism“可并行任务数量”配合工作。
Fork方法介绍
- Fork就是一个不断分枝的过程,在当前任务的基础上长出n多个子任务,他将新创建的子任务放入当前线程的work queue队列中,Fork/Join框架将根据当前正在并发执行ForkJoinTask任务的ForkJoinWorkerThread线程状态,决定是让这个任务在队列中等待,还是创建一个新的ForkJoinWorkerThread线程运行它,又或者是唤起其它正在等待任务的ForkJoinWorkerThread线程运行它。
当一个ForkJoinTask任务调用fork()方法时,当前线程会把这个任务放入到queue数组的queueTop位置,然后执行以下两句代码:
if ((s -= queueBase) <= 2)
pool.signalWork();
else if (s == m)
growQueue();
当调用signalWork()方法。signalWork()方法做了两件事:1、唤配当前线程;2、当没有活动线程时或者线程数较少时,添加新的线程。
Join方法介绍
Join是一个不断等待,获取任务执行结果的过程。
private int doJoin() {
Thread t; ForkJoinWorkerThread w; int s; boolean completed;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) {
if ((s = status) < 0)
return s;
if ((w = (ForkJoinWorkerThread)t).unpushTask(this)) {
try {
completed = exec();
} catch (Throwable rex) {
return setExceptionalCompletion(rex);
}
if (completed)
return setCompletion(NORMAL);
}
return w.joinTask(this);
}
else
return externalAwaitDone();
}
- 第4行,(s=status)<0表示这个任务被执行完,直接返回执行结果状态,上层捕获到状态后,决定是要获取结果还是进行错误处理;
- 第6行,从queue中取出这个任务来执行,如果执行完了,就设置状态为NORMAL;
- 前面unpushTask()方法在队列中没有这个任务时会返回false,15行调用joinTask等待这个任务完成。
- 由于ForkJoinPool中有一个数组叫submissionQueue,通过submit方法调用而且非ForkJoinTask这种任务会被放到这个队列中。这种任务有可能被非ForkJoinWorkerThread线程执行,第18行表示如果是这种任务,等待它执行完成。
下面来看joinTask方法
final int joinTask(ForkJoinTask<?> joinMe) {
ForkJoinTask<?> prevJoin = currentJoin;
currentJoin = joinMe;
for (int s, retries = MAX_HELP;;) {
if ((s = joinMe.status) < 0) {
currentJoin = prevJoin;
return s;
}
if (retries > 0) {
if (queueTop != queueBase) {
if (!localHelpJoinTask(joinMe))
retries = 0; // cannot help
}
else if (retries == MAX_HELP >>> 1) {
--retries; // check uncommon case
if (tryDeqAndExec(joinMe) >= 0)
Thread.yield(); // for politeness
}
else
retries = helpJoinTask(joinMe) ? MAX_HELP : retries - 1;
}
else {
retries = MAX_HELP; // restart if not done
pool.tryAwaitJoin(joinMe);
}
}
}
- (1)这里有个常量MAX_HELP=16,表示帮助join的次数。第11行,queueTop!=queueBase表示本地队列中有任务,如果这个任务刚好在队首,则尝试自己执行;否则返回false。这时retries被设置为0,表示不能帮助,因为自已队列不为空,自己并不空闲。在下一次循环就会进入第24行,等待这个任务执行完成。
- (2)第20行helpJoinTask()方法返回false时,retries-1,连续8次都没有帮到忙,就会进入第14行,调用yield让权等待。没办法人口太差,想做点好事都不行,只有停下来休息一下。
- (3)当执行到第20行,表示自己队列为空,可以去帮助这个任务了,下面来看是怎么帮助的?
outer:for (ForkJoinWorkerThread thread = this;;) {
// Try to find v, the stealer of task, by first using hint
ForkJoinWorkerThread v = ws[thread.stealHint & m];
if (v == null || v.currentSteal != task) {
for (int j = 0; ;) { // search array
if ((v = ws[j]) != null && v.currentSteal == task) {
thread.stealHint = j;
break; // save hint for next time
}
if (++j > m)
break outer; // can't find stealer
}
}
// Try to help v, using specialized form of deqTask
for (;;) {
ForkJoinTask<?>[] q; int b, i;
if (joinMe.status < 0)
break outer;
if ((b = v.queueBase) == v.queueTop ||
(q = v.queue) == null ||
(i = (q.length-1) & b) < 0)
break; // empty
long u = (i << ASHIFT) + ABASE;
ForkJoinTask<?> t = q[i];
if (task.status < 0)
break outer; // stale
if (t != null && v.queueBase == b &&
UNSAFE.compareAndSwapObject(q, u, t, null)) {
v.queueBase = b + 1;
v.stealHint = poolIndex;
ForkJoinTask<?> ps = currentSteal;
currentSteal = t;
t.doExec();
currentSteal = ps;
helped = true;
}
}
// Try to descend to find v's stealer
ForkJoinTask<?> next = v.currentJoin;
if (--levels > 0 && task.status >= 0 &&
next != null && next != task) {
task = next;
thread = v;
}
}
- (1)通过查看stealHint这个字段的注释可以知道,它表示最近一次谁来偷过我的queue中的任务。因此通过stealHint并不能找到当前任务被谁偷了?所以第4行v.currentSteal != task完全可能。这时还有一个办法找到这个任务被谁偷了,看看currentSteal这个字段的注释表示最近偷的哪个任务。这里扫描所有偷来的任务与当前任务比较,如果相等,就是这个线程偷的。如果这两种方法都不能找到小偷,只能等待了。
- (2)当找到了小偷后,以其人之身还之其人之道,从小偷那里偷任务过来,相当于你和小偷共同执行你的任务,会加速你的任务完成。
- (3)小偷也是爷,如果小偷也在等待一个任务完成,权利反转(小偷等待的这个任务做为当前任务,小偷扮演当事人角色把前面的流程走一遍),这是一个递归的过程。
本文来自博客园,作者:洛神灬殇,转载请注明原文链接:https://www.cnblogs.com/liboware/p/15251089.html,任何足够先进的科技,都与魔法无异。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/70142.html

