
文章目录
1 使用场景
- 判断用户输入的字符串是否是正确的手机号、邮箱等格式
- 判断用户输入的密码是否同时包含了大小写字母和数字
- 判断字符串是否是有效的时间
- String.split()方法传入正则表达式分割字符串
- 使用正则表达式来搜索字符串等等
2 正则表达式结构组成
正则表达式通常由一些普通字符和一些元字符组成。
- 普通字符:就是本身作为一个字符时,它不具有其他含义,像我们常用的大小写字母和数字
- 元字符:就是除了本身作为一个字符外,还可以表达其他含义。





3 匹配规则
3.1 匹配普通字符
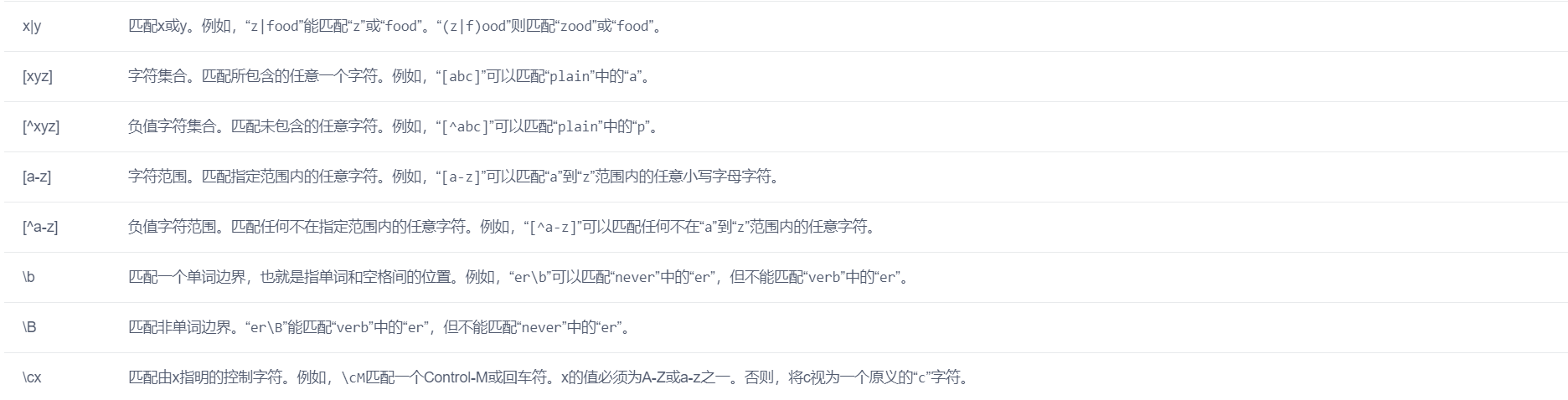
对于正则表达式abc来说,它
只能精确地匹配字符串"abc",不能匹配”ab”,“Abc”,”abcd”等其他任何字符串。
public class Regex {
public static String regex = "abc";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
check("abc");
check("ab");
check("Abc");
check("ABC");
check("abcd");
check("123");
}
public static void check(String str) {
boolean result = str.matches(regex);
if (result) {
System.out.println(str + "匹配成功");
} else {
System.out.println(str + "匹配失败");
}
}
}
为避免篇幅过长,下面的代码不再贴check(String str)方法及public class Regex ,只贴不重复部分及重要部分
3.2 匹配元字符
3.2.1 匹配字符内容
在Java定义的正则里,由于一个\表示的是字符串转义,因此在Java定义带有\的元字符时,还需要多写一个\才行
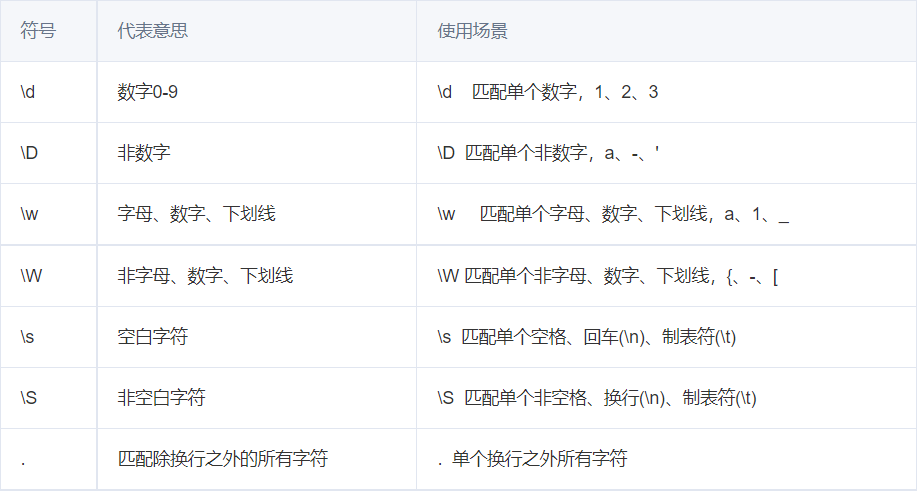
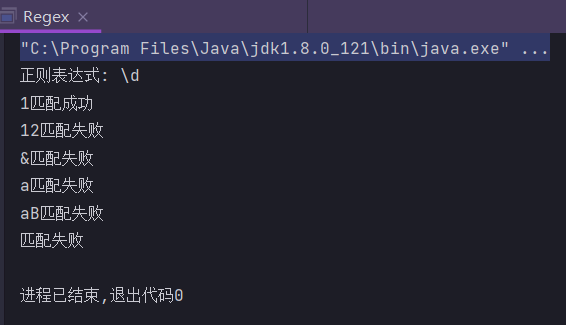
\d
单个数字0-9
public static String regex = "\\d";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
check("1");
check("12");
check("&");
check("a");
check("aB");
check("");
}
\D
单个非数字,
不匹配空字符串
public static String regex = "\\D";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
check("a");
check("ab");
check("A");
check("1");
check("");
check("@");
check("\n");
check("\r");
check("\t");
}
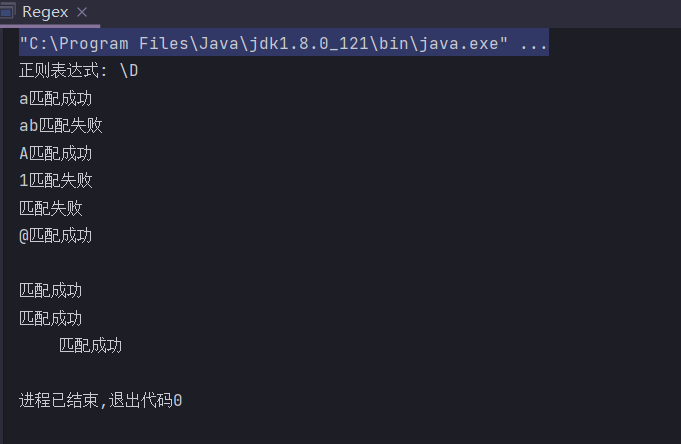
\w
单个字母或数字或下划线,
不匹配中文字符
public static String regex = "\\w";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
check("1");
check("12");
check("a");
check("ab");
check("_");
check("-");
check("");
check("~");
check("\n");
}
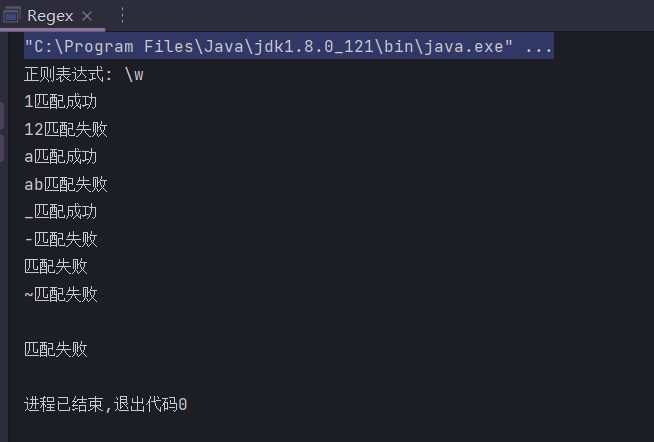
\W
单个非数字且非字母且非下划线,
不匹配空字符串
public static String regex = "\\W";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
check("1");
check("12");
check("a");
check("ab");
check("_");
check("-");
check("");
check("~");
check("*");
check("\n");
}
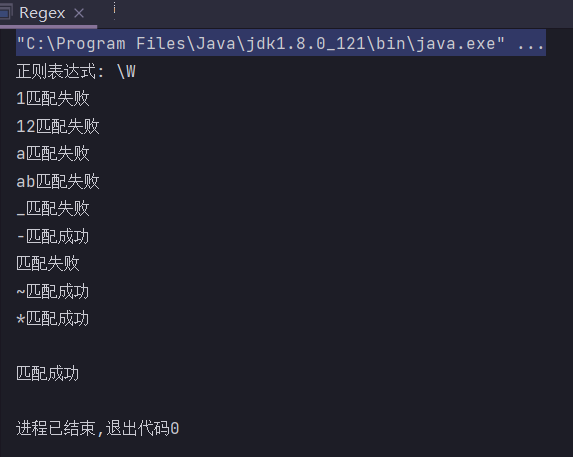
\s
单个空白字符,如单个空格或回车(\n)或制表(\t),
不匹配空字符串
public static String regex = "\\s";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
check("1");
check("a");
check("_");
check("@");
check("");
check("\n");
check("\r");
check("\t");
check(" ");
check(" ");
}

\S
非空白字符,
不匹配空字符串
public static String regex = "\\S";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
check("1");
check("12");
check("a");
check("_");
check("@");
check("");
check("\n");
check("\r");
check("\t");
check(" ");
check(" ");
}
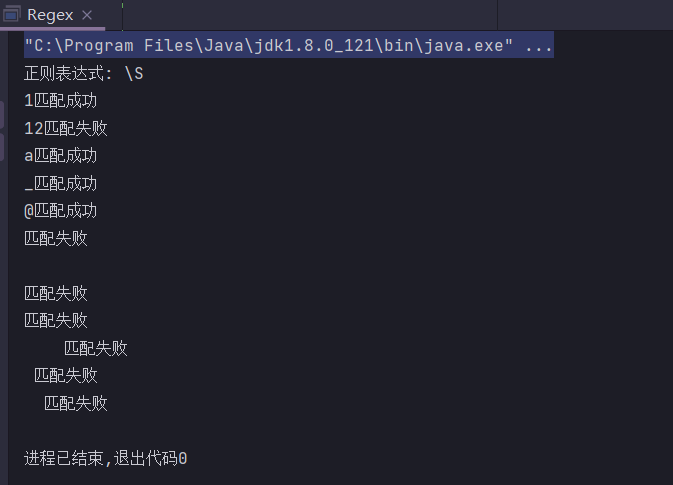
.
单个除换行(“\n”或”\r”)以外所有字符,可以匹配制表(“\t”)以及单个空格
public static String regex = ".";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
check("1");
check("12");
check("a");
check("_");
check("@");
check("");
check("\n");
check("\r");
check("\t");
check(" ");
check(" ");
}

3.2.2 匹配次数
未引入次数之前,我们匹配几个字符就得在正则表达式中重复写几次,例如匹配5个数字,之前是”\d\d\d\d\d”,引入次数之后可以写为”\d{5}”
public static String regex = "\\d\\d\\d\\d\\d";
public static String regex = "\d{5}";
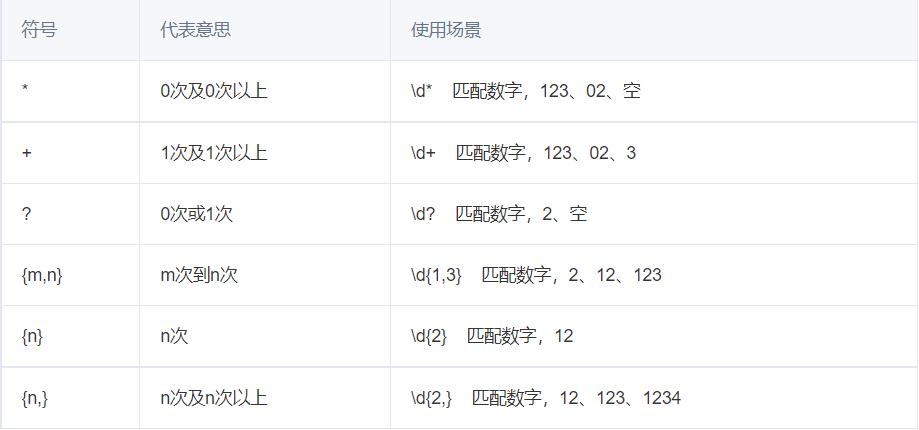
*
匹配0次及0次以上
public static String regex = "1*";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
check("1");
check("1111");
check("");
check("2");
}
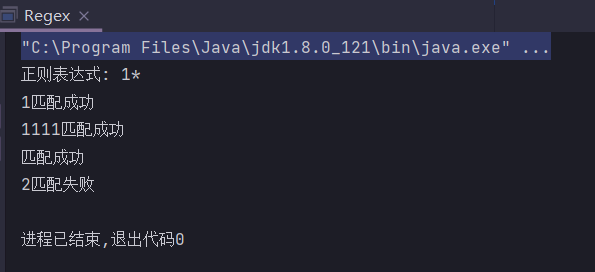
+
匹配1次及1次以上
public static String regex = "1+";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
check("1");
check("1111");
check("");
check("2");
}
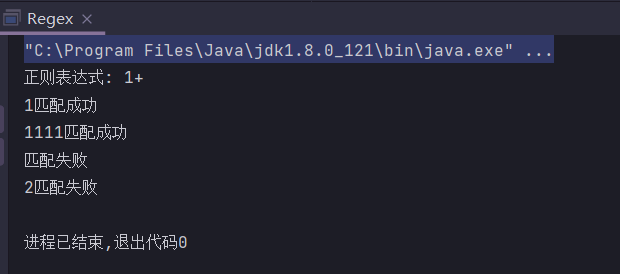
?
匹配0次或1次
public static String regex = "1?";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
check("1");
check("1111");
check("");
check("2");
}
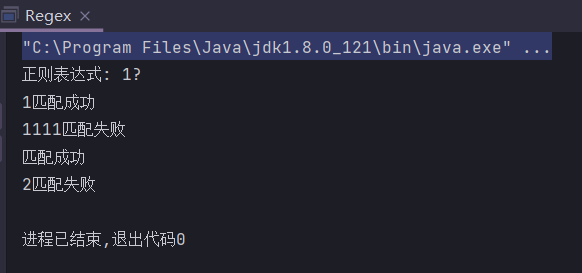
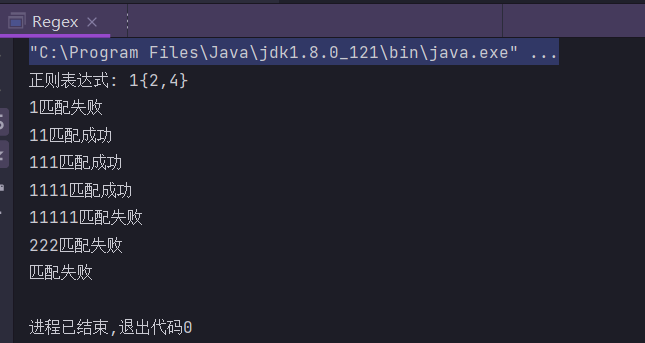
{m,n}
匹配m次到n次,包括m次和n次
public static String regex = "1{2,4}";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
check("1");
check("11");
check("111");
check("1111");
check("11111");
check("222");
check("");
}
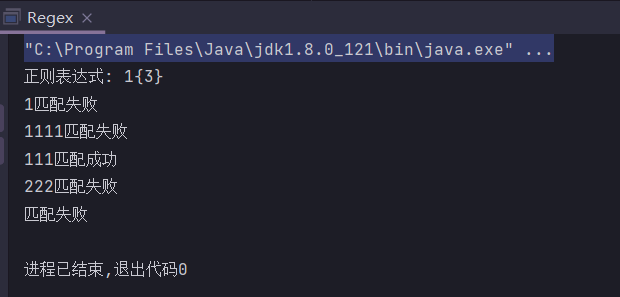
{n}
匹配n次
public static String regex = "1{3}";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
check("1");
check("1111");
check("111");
check("222");
check("");
}
{n,}
匹配n次及n次以上
public static String regex = "1{3,}";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
check("1");
check("1111");
check("111");
check("222");
check("");
}

3.2.3 字符簇
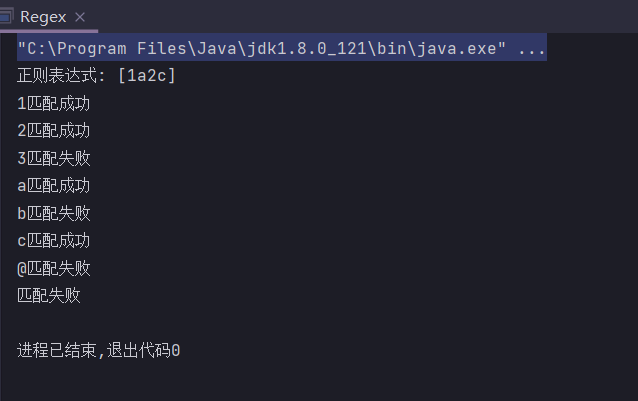
[]
匹配其中任意一个字符
[1a2c] //匹配1或a或2或c
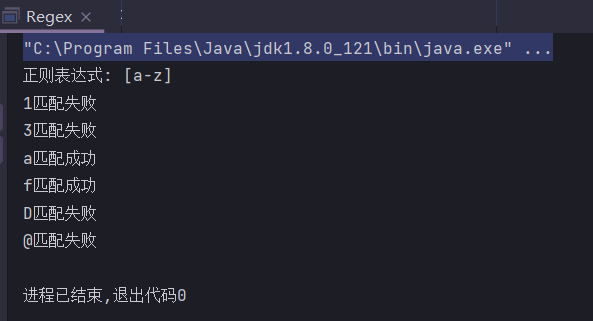
[a-z] // 匹配所有的小写字母
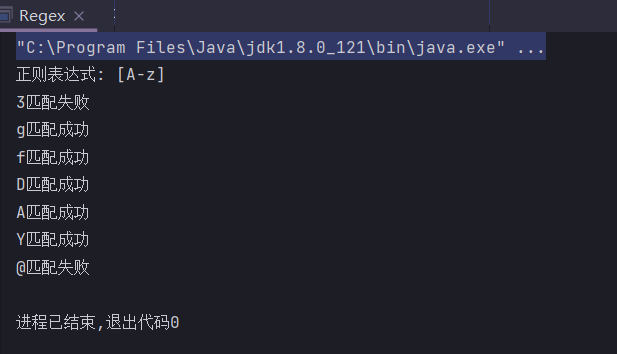
[A-Z] // 匹配所有的大写字母
[a-zA-Z] // 匹配所有的字母
[A-z] // 匹配所有的字母,不能写为[a-Z],因为大写字母的Ascii码排在小写字母前
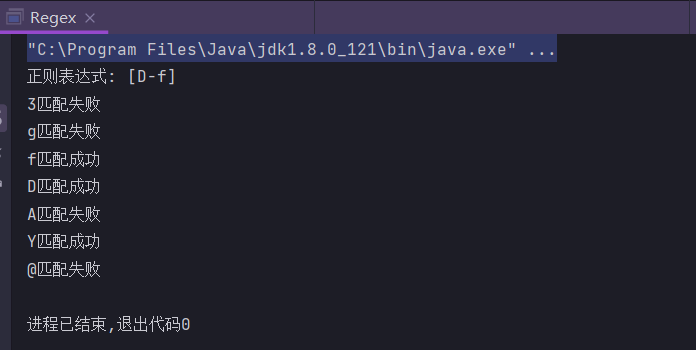
[D-f] // 匹配D-Z,a-f之间任意一个字母
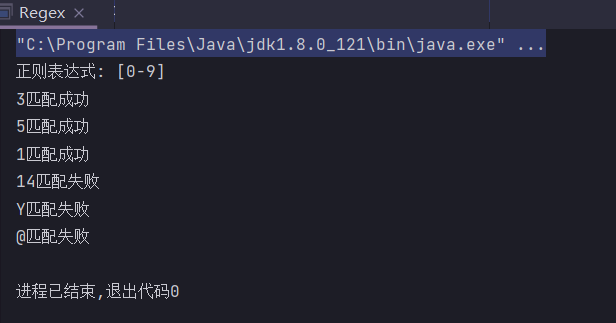
[0-9] // 匹配所有的数字
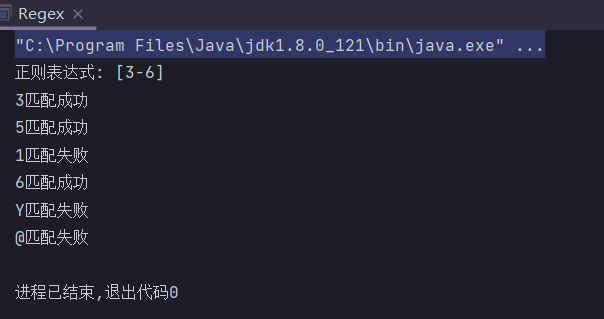
[3-6] //匹配3-6之间任意一个数字
public static String regex = "[1a2c]";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
check("1");
check("2");
check("3");
check("a");
check("b");
check("c");
check("@");
check("");
}


[^ ]
表示不与中括号里的任意字符匹配,其它均可以匹配
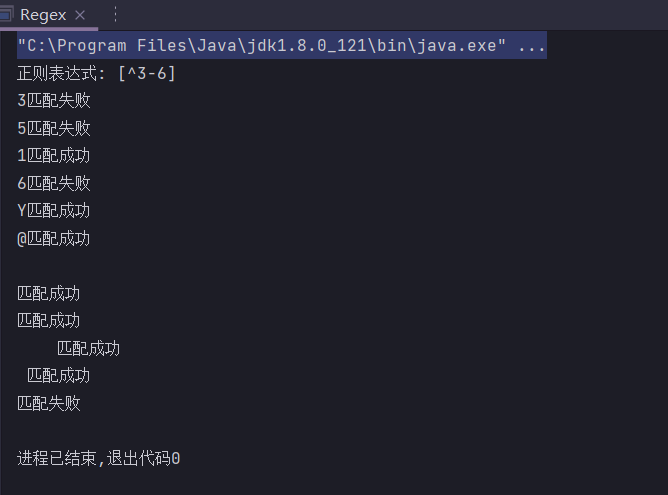
public static String regex = "[^3-6]";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
check("3");
check("5");
check("1");
check("6");
check("Y");
check("@");
check("\n");
check("\r");
check("\t");
check(" ");
check("");
}
3.2.3 匹配位置
^$只是约定而已,加不加效果都一样,算是一种规范,因为正则表达式的匹配规则是从左到右按规则匹配。
^
限定开头,比如”^abc”,表示匹配以”abc”开头的字符串
”^”这个字符是
在中括号”[]”中被使用的话就是表示字符类的否定,如果不是的话就是表示限定开头。这里说的是直接在”[]”中使用,不包括嵌套使用。 其实也就是说”[]”代表的是一个字符集,”^”只有在字符集中才是反向字符集的意思。
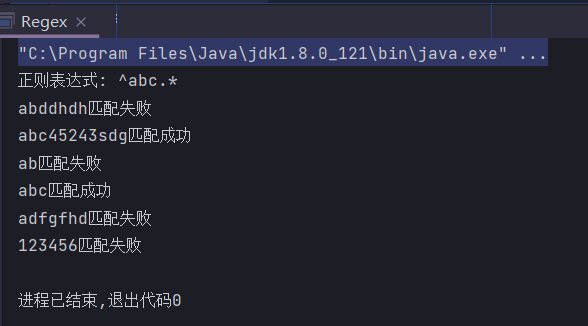
public static String regex = "^abc.*";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
check("abddhdh");
check("abc45243sdg");
check("ab");
check("abc");
check("adfgfhd");
check("123456");
}
$
限定结尾,比如”123$”,表示匹配以”123″结尾的字符串
public static String regex = ".*123$";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
check("abddhdh");
check("abc452dgs123");
check("ab12");
check("abc233");
check("123sgaghah");
}

\b
匹配一个单词边界。
什么是单词边界呢,我们以”\b”为分割来研究一下
import java.util.regex.Pattern;
public class Regex {
public static String regex = "\\b";
public static String input = "1a\nA_h\raf\thk 46_64@$软件h。r";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
System.out.println("被分割的字符串: " + input);
Pattern pattern = Pattern.compile(regex);
String[] result = pattern.split(input);
for (String str : result) {
System.out.println("子串:" + str);
}
}
}
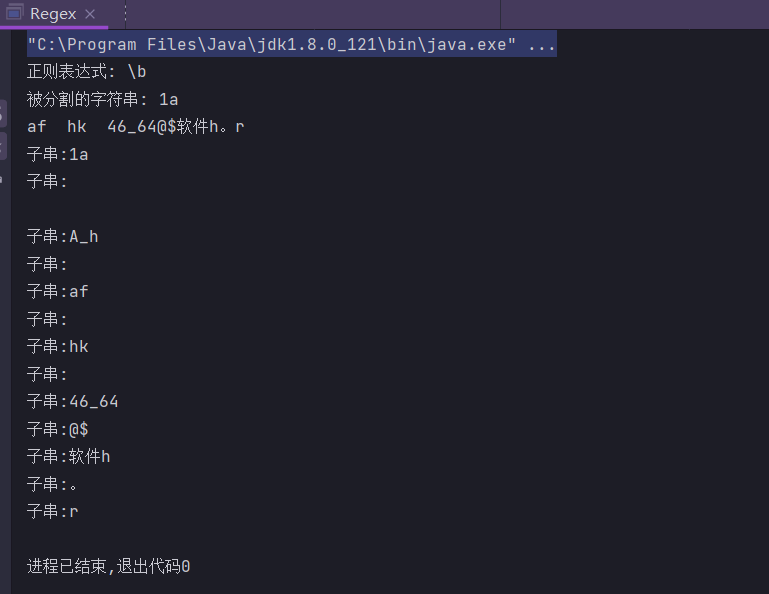
由此可知,单词边界就是单词和符号之间的边界,这里的单词可以是
中文字符,数字,字母,下划线;符号可以是中文符号,英文符号,空格,制表符(“\t”),换行(“\n”或”\r”)。
举例
public class Regex {
public static String regex = "\\ba\\b";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
check(" a ");
}
public static void check(String str) {
boolean result = str.matches(regex);
if (result) {
System.out.println(str + "匹配成功");
} else {
System.out.println(str + "匹配失败");
}
}
}

有的人可能认为如上代码会匹配成功,然而不是,因为
空格并不是单词边界,空格与a之间的那个才叫单词边界。
check("a");
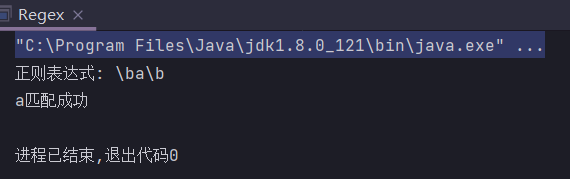
字符串开始与第一个字符之间、最后一个字符与字符串结束之间也算单词边界
一般来说\b不用来判断当前字符串是否符合某种规则,一般用于搜索,后面会有介绍
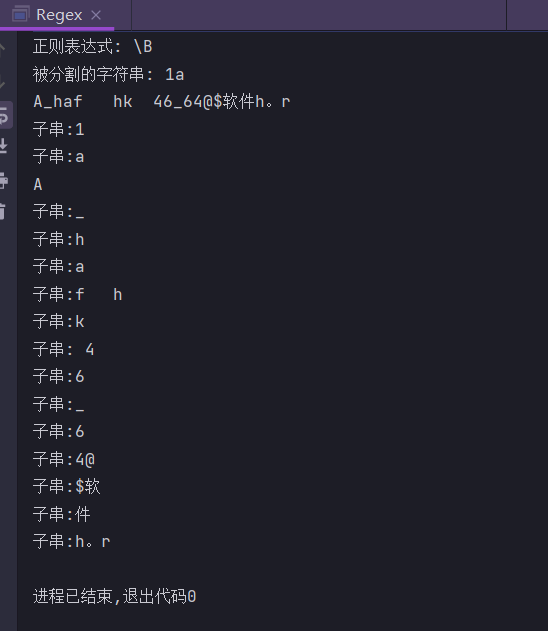
\B
匹配一个非单词边界。与”\b”相反,分割的时候,“\b”是假如一个单词和一个符号相连就会进行分割,而”\B”是如果两个单词相连就会进行分割。
import java.util.regex.Pattern;
public class Regex {
public static String regex = "\\B";
public static String input = "1a\nA_haf\thk 46_64@$软件h。r";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
System.out.println("被分割的字符串: " + input);
Pattern pattern = Pattern.compile(regex);
String[] result = pattern.split(input);
for (String str : result) {
System.out.println("子串:" + str);
}
}
}
3.2.4 分支条件
|
表示或,比如ab|cd|fg,匹配ab或cd或fg
public static String regex = "ab|cd|fg";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
check("ab");
check("cd");
check("fg");
check("abc");
check("abcd");
check("abcdfg");
check("123456");
}

3.2.5 分组
小括号”()”,称之为分组,分组匹配的内容可以在后续的正则中重复使用,只需要指定分组的序号即可,分组的序号是从左往右从1开始递增的。
\num
当\后面跟数字,表示匹配第几个括号中的结果。比如ab(cd)(gh)\1\2,这里的\1就表示”cd”,\2就表示”gh”,ab(cd)(gh)\1\2等同于abcdghcdgh。
public static String regex = "ab(cd)(gh)\\1\\2";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
check("123sgaghah");
check("abcdgh");
check("abcdghcdgh");
}

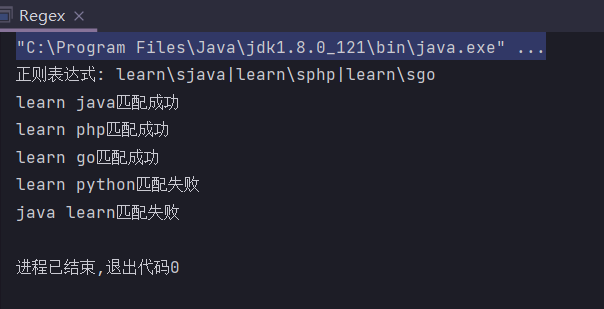
小括号”()“还有其他的作用,比如现在我们想要匹配字符串learn java、learn php和learn go怎么办?一个最简单的规则是learn\sjava|learn\sphp|learn\sgo,但是这个规则太复杂了,可以把公共部分提出来,然后用”()”把子规则括起来表示成learn\s(java|php|go)。
public static String regex = "learn\\sjava|learn\\sphp|learn\\sgo";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
check("learn java");
check("learn php");
check("learn go");
check("learn python");
check("java learn");
}
public static String regex = "learn\\s(java|php|go)";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
check("learn java");
check("learn php");
check("learn go");
check("learn python");
check("java learn");
}

匹配规则优先级,越上面的优先级越高

4 分组提取匹配的子串
虽然正则匹配规则很简单,但是往往匹配成功后,下一步是提取匹配成功的字串如区号和电话号码,分别存入数据库。当然可以用String提供的indexOf()和substring()这些方法,但它们从正则匹配的字符串中提取子串没有通用性,下一次要提取还得改代码。
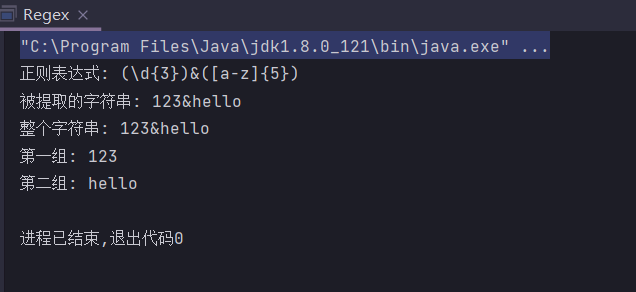
正确的方法是用小括号”()”先把要提取的规则分组,然后按括号提取子串。现在我们没办法用String.matches()这样简单的判断方法了,必须引入java.util.regex包,用Pattern对象匹配,匹配后获得一个Matcher对象,如果匹配成功,就可以直接从Matcher.group(index)返回子串,group(0)为整个字符串,group(1)为第一个子串,group(2)为第二个子串
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Regex {
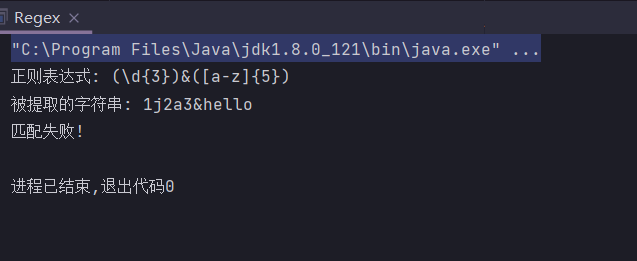
public static String regex = "(\\d{3})&([a-z]{5})";
public static String input = "123&hello";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
System.out.println("被提取的字符串: " + input);
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(input);
if (matcher.matches()) {
String whole = matcher.group(0);
String group1 = matcher.group(1);
String group2 = matcher.group(2);
System.out.println("整个字符串: " + whole);
System.out.println("第一组: " + group1);
System.out.println("第二组: " + group2);
} else {
System.out.println("匹配失败!");
}
}
}
使用Matcher时,必须首先调用matches()判断是否匹配成功,匹配成功后,才能调用group()提取子串。
5 贪婪匹配与非贪婪匹配
正则表达式
默认使用贪婪匹配:任何一个规则,它总是尽可能多地向后匹配。
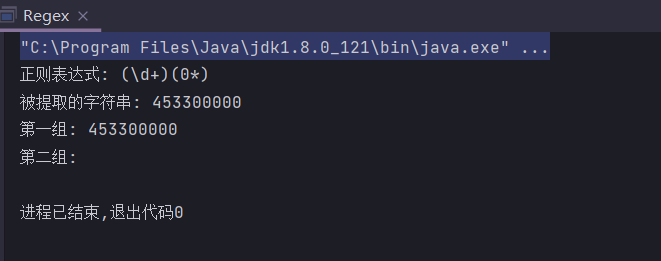
- 给定一个字符串表示的数字453300000,判断该数字末尾0的个数,正则表达式为”(\d+)(0*)“,我们期盼的结果是分为两组,分别为”4533″和”00000”,然而运行结果却不像我们所期盼的这样。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Regex {
public static String regex = "(\\d+)(0*)";
public static String input = "453300000";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
System.out.println("被提取的字符串: " + input);
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(input);
if (matcher.matches()) {
String group1 = matcher.group(1);
String group2 = matcher.group(2);
System.out.println("第一组: " + group1);
System.out.println("第二组: " + group2);
} else {
System.out.println("匹配失败!");
}
}
}
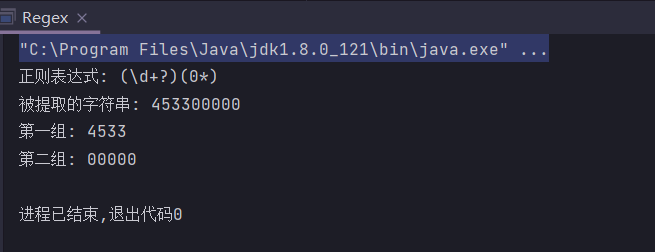
那么如何得到我们期盼的结果呢,答案是
非贪婪匹配,使其尽可能少地向后匹配。
给定一个匹配规则,只需要在表示匹配次数的元字符后面加上?就变成了非贪婪匹配。
- 还是刚才这个例子,我们只需要将”(\d+)(0*)“改为”(\d+?)(0*)”即为非贪婪匹配
*? // 重复任意次,但尽可能少重复
+? // 重复1次或更多次,但尽可能少重复
?? // 重复O次或1次,但尽可能少重复
{m,n}? // 重复m到n次,但尽可能少重复
{n,}? // 重复n次以上,但尽可能少重复
6 搜索和替换
6.1 搜索
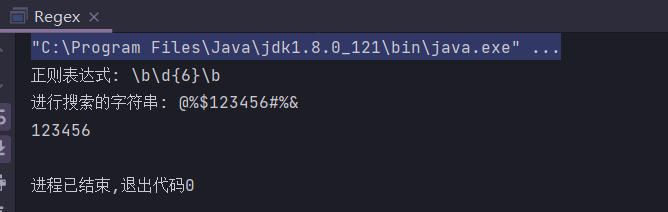
假如我们想要用户输入连续的6位数字,而用户却输入了”@%$123456#%&”,此时我们就可以使用合适的正则表达式将我们需要的部分搜索提取出来。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Regex {
public static String regex = "\\b\\d{6}\\b";
public static String input = "@%$123456#%&";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
System.out.println("进行搜索的字符串: " + input);
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(input);
if (matcher.find()) {
System.out.println(matcher.group());
} else {
System.out.println("未搜索到");
}
}
}
有的时候用户输入的内容可能不止一个符合条件的子串,此时我们可以反复调用find()方法,在整个串中搜索符合条件的子串。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Regex {
public static String regex = "\\b\\d{6}\\b";
public static String input = "@%$123456#%&456789$%%";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
System.out.println("进行搜索的字符串: " + input);
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(input);
while (matcher.find()) {
System.out.println(matcher.group());
}
}
}

6.2 替换
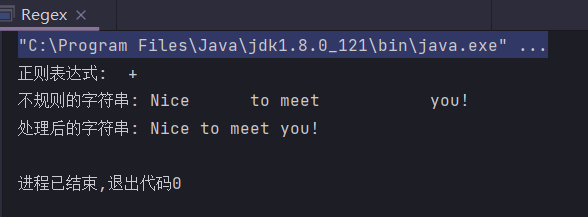
假如我们得到了一个不规范的句子”Nice to meet you!”,其中英文单词间隔了多个空格,我们想要消除这些多余的空格,就需要使用替换,将连续多个空格替换为单个空格。
public class Regex {
public static String regex = " +";
public static String input = "Nice to meet you!";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
System.out.println("不规则的字符串: " + input);
System.out.println("处理后的字符串: " + input.replaceAll(regex, " "));
}
}
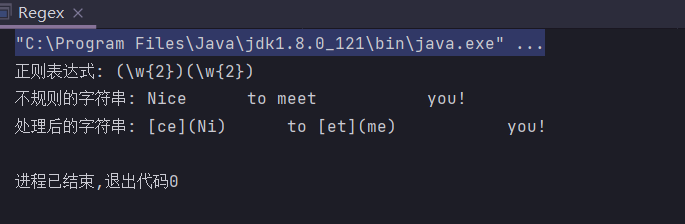
反向引用
如果我们要把搜索到的指定字符串按规则替换,比如各加一个”[]”,这个时候,使用replaceAll()的时候,我们传入的第二个参数可以使用$1,$2等来反向引用匹配到的子串。
public class Regex {
public static String regex = "(\\w{2})(\\w{2})";
public static String input = "Nice to meet you!";
public static void main(String[] args) {
System.out.println("正则表达式: " + regex);
System.out.println("不规则的字符串: " + input);
System.out.println("处理后的字符串: " + input.replaceAll(regex, "[$2]($1)"));
}
}
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/71482.html

