
系列文章目录
Java基础篇之jdk、jre环境变量的配置
第一章 – Java基础语法
第七章 – Java网络编程
前言
集合是Java基础知识中的重难点部分,也是面试官频频问到的章节,虽然作为基础知识,但往往被小伙伴们忽视,使得面试时的回答往往不尽如人意,本人趁国庆闲暇时抽空整理这部分知识,包含基础用法、代码案例、源码解读等方面,文章阐述过程如有误,希望各位大佬、大牛们批评指正,小弟不甚感激,希望和伙伴们一起学习、进步!
一、集合框架图
1.单列集合
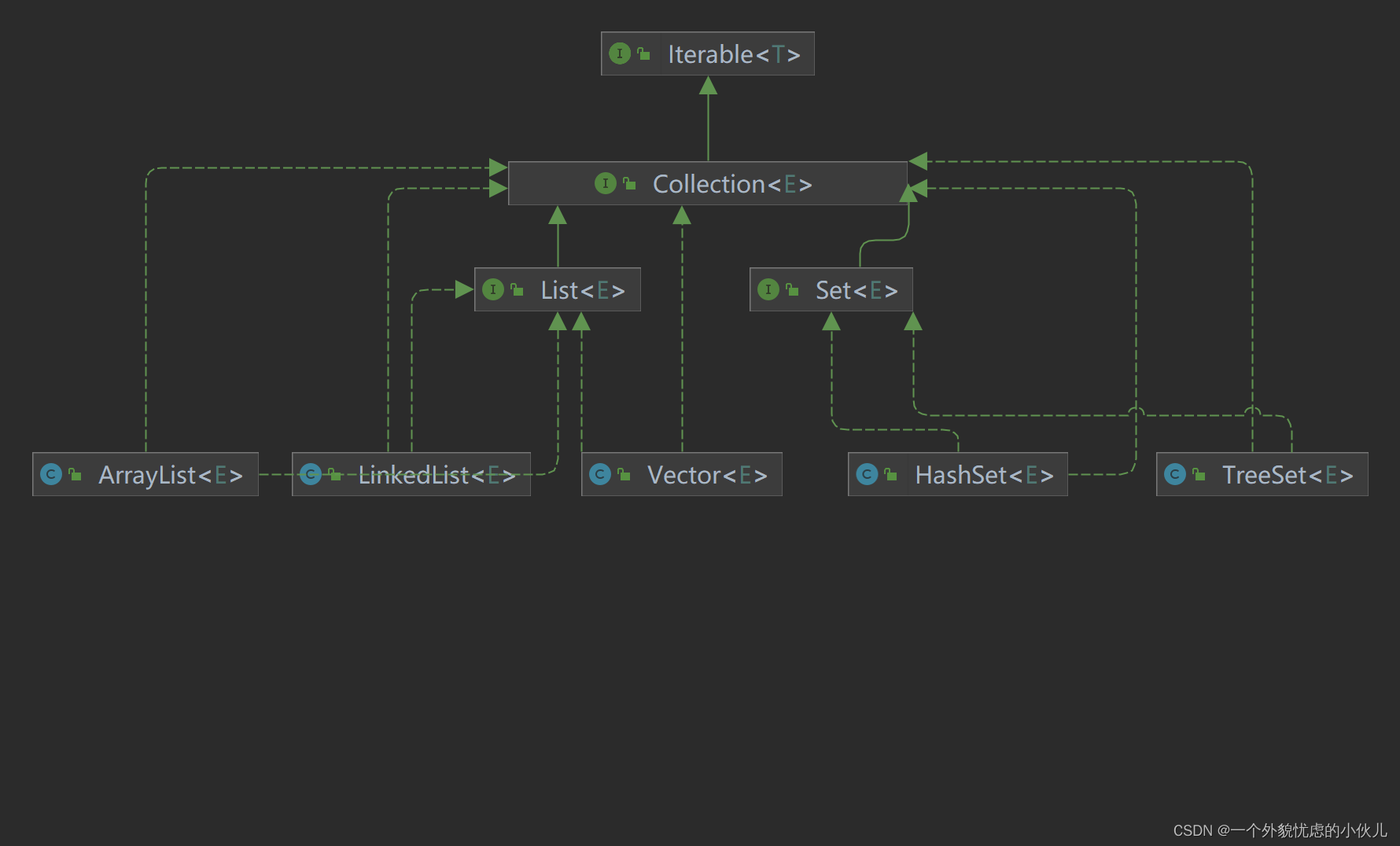
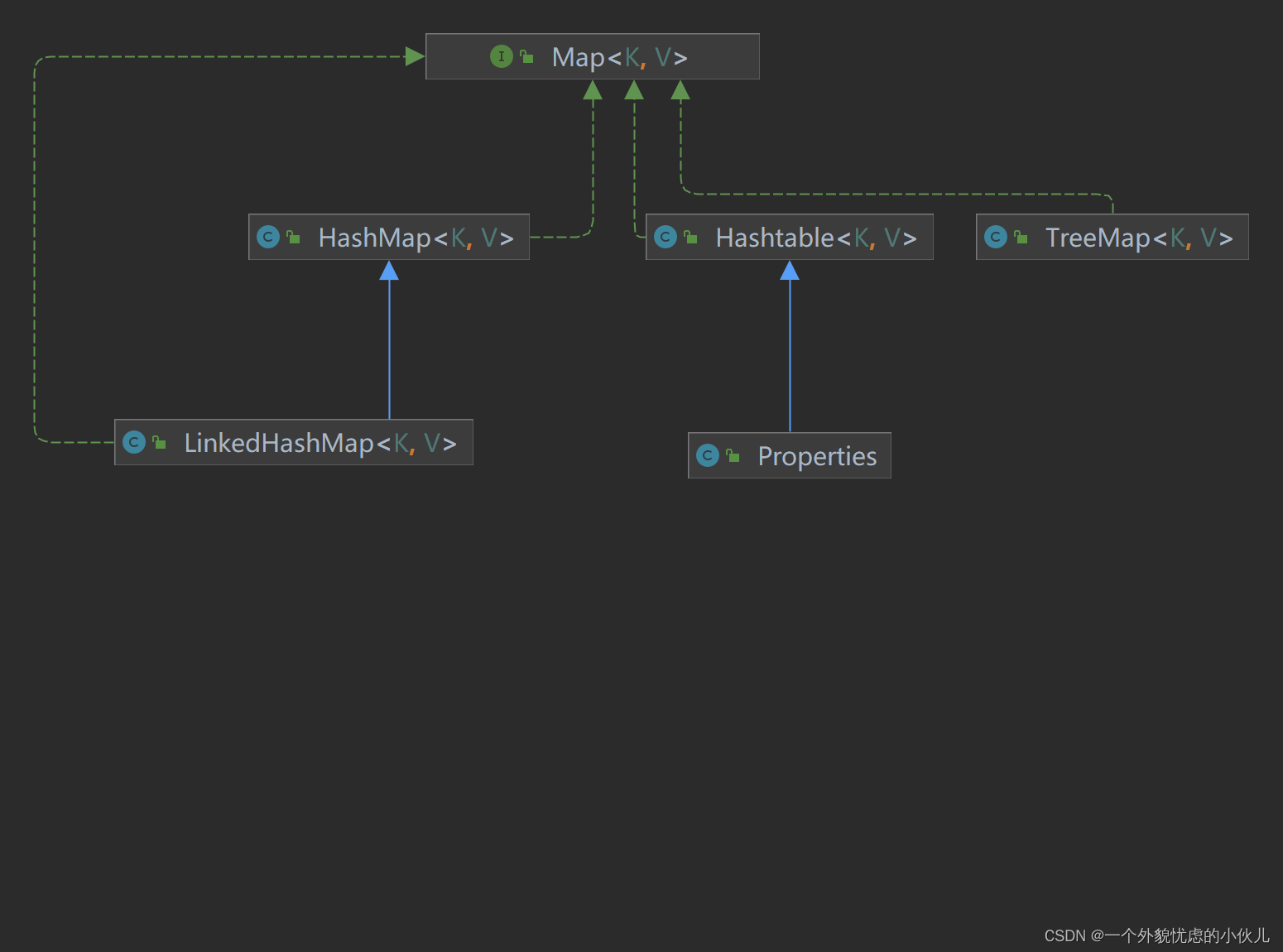
2.双列集合
二、Collection接口和常用方法
1.Collection接口基本特点
1.Collection接口子类可以存放多个元素,每个元素可以是Object
2.有些Collection的实现类,可以存放重复的元素,有些不可以
3.有些Collection的实现类,有些是有序的(List),有些是无序的(Set)
4.Collection没有直接的实现子类,是通过它的子接口Set和List来实现的
2.Collection接口常用方法
add : 添加单个元素
remove : 删除指定元素
contains : 查找元素是否存在
size : 获取元素个数
isEmpty :判断元素是否为空
clear :清空
addAll :添加多个元素
containsAll :查找多个元素是否都存在
removeAll :删除多个元素
3.Collection接口遍历元素方式
3.1使用Iterator迭代器遍历
1.Iterator对象称为迭代器,主要用于遍历Collection集合中的元素
2.所有实现了Collection接口的集合类都有一个iterator()方法,用于返回一个实现了Iterator接口的对象,即可以返回一个迭代器
3.Iterator的结构
4.Iterator仅用于遍历集合,Iterator本身并不存放对象
5.迭代器的执行原理

代码如下(示例):
Iterator iterator = coll.iterator();// 得到一个集合的迭代器
hasNext() //判断是否还有下一个元素
while(iterator.hasNext()){
next();// 1.指针下移 2.将下移后集合位置上的元素返回
}
提示:在调用iterator.next()方法之前,必须调用iterator.hasNext()进行检测。若不调用,且下一条记录无效,直接调用iterator.next()会抛出NoSuchElementException异常
3.2使用增强for循环遍历
for(Object object : col){
}
3.3使用普通for循环方式遍历
三、Set接口和常用方法
1.Set接口基本介绍
1.无序(添加和取出的顺序不一致),没有索引
2.不允许重复元素,所以最多包含一个null
2.Set接口常用方法
1.和List接口一样,Set接口也是Collection接口的子接口,因此,常用方法和Collection接口一样
3.Set接口的遍历方式
1.可以使用迭代器方式遍历
2.可以使用增强for方式遍历
3.不能使用索引的方式
4.取出的顺序虽然不是添加的顺序,但是是固定的
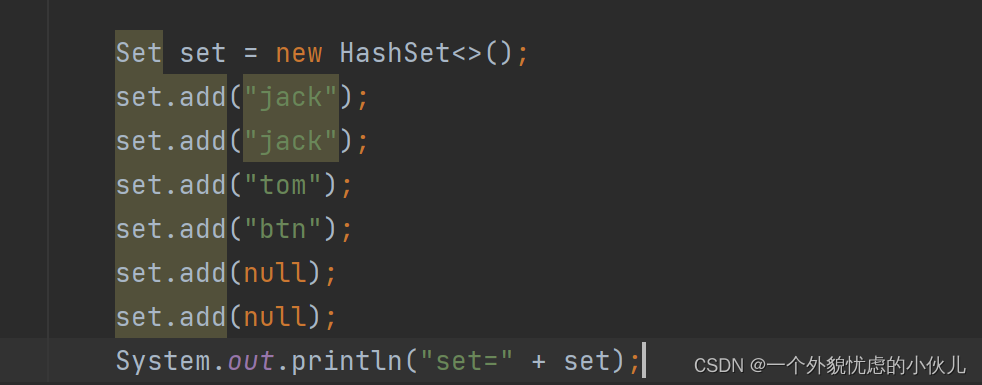

4.Set接口实现类-HashSet
4.1HashSet基本特点
1.HashSet实现了Set接口
2.HashSet实际上是HashMap
// HashSet构造方法实际创建了一个HashMap对象:
public HashSet(){
map = new HashMap<>();
}
3.可以存放null值,但是只能有一个null
4.HashSet不保证元素是有序的,取决于hash后,再确定索引的结果
5.不能有重复元素或对象
4.2HashSet底层机制说明
1.分析HashSet底层是HashMap,HashMap底层是(数组+链表+红黑树)
2.分析HashSet的添加元素底层是如何实现的(hash() + equals())
3.HashSet底层是HashMap
4.添加一个元素时,先得到hash值-会转成->索引值
5.找到存储数据表table,看这个索引位置是否已经存放的有元素如果没有,直接加入如果有,调用equals比较,如果相同,就放弃添加,如果不相同,则添加到最后
6.在Java8中,如果一条链表的元素个数到达TREEIFY_THRESHOLD(默认是8),并且table的大小>=MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树)
<< num (相当于 乘 2^num)
5.Set接口实现类-LinkedHashSet
5.1LinkedHashSet基本特点
1.LinkedHashSet是HashSet的子类
2.LinkedHashSet底层是一个LinkedHashMap,底层维护了一个组数+双向链表
3.LinkedHashSet根据元素的hashCode值来决定元素的储存位置,同时使用链表维护元素的次序,这使得元素看起来是以插4.入顺序保存的
5.LinkedHashSet不允许添加重复元素
5.2LinkedHashSet底层机制
1.在LinkedHashSet中维护了一个hash表和双向链表(LinkedHashSet有head和tail)
2.每一个节点有pre和next属性,这样可以形成双向链表
3.在添加一个元素时,先求hash值,在求索引,确定该元素在hashtable的位置,然后将添加的元素加入到双向链表(如果已经存在,不添加【原则和HashSet一样】)
4.这样的话,我们遍历LinkedHashSet也能确保插入顺序和遍历顺序一致
6.Set接口实现类-TreeSet
6.1LinkedHashSet基本特点
1.使用默认构造器,创建TreeSet是无序的
2.提供了一个可以传入Comparator接口内部类
TreeSet<Object> treeSet = new TreeSet<>(new Comparator<Object>() {
@Override
public int compare(Object o1, Object o2) {
return ((String) o2).compareTo((String) o1);
}
});
四、Map接口和常用方法
1.Map接口实现类的特点
注:这里的是JDK8的Map接口特点
1.Map与Collection并列存在。用于保存具有映射关系的数据:Key-Value
2.Map中的key和value可以是任何引用类型的数据,会封装到HashMap$Node对象中
3.Map的Key不允许重复,原因和HashSet一样
4.Map中的value可以重复
5.Map的key可以为null,value也可以为null,注意key为null,只能有一个,value为null,可以多个
6.常用String类作为Map的key
7.key和value之间存在单向一对一关系,即通过指定的key总能找到对应的value
8.Map存放数据的key-value示意图,一对k-v是存放在一个Node中的,又因为Node实现了Entry接口,有些书上也说一对k-v就是一个Entry
2.Map接口的常用方法
put:添加
remove:根据键删除映射关系
get:根据键获取值
size:获取元素个数
isEmpty:判断元素个数是否为0
clear:清除
containsKey:查找键是否存在
3.Map六大遍历方式
Map hashMap = new HashMap<>();
hashMap.put("N1", "小黄");
hashMap.put("N2", "小黑");
hashMap.put("N3", "小吴");
System.out.println("hashMap=" + hashMap);
// 第一组,先取出所有的key,再通过key取出对应的value
System.out.println("----第一组------");
Set keySet = hashMap.keySet();
// (1) 增强for
for (Object key : keySet){
System.out.println(key + "--" + hashMap.get(key));
}
// (2) 迭代器
Iterator iterator = keySet.iterator();
while (iterator.hasNext()) {
Object key = iterator.next();
System.out.println(key + "--" + hashMap.get(key));
}
// 第二组 把所有的values取出来
System.out.println("----第二组------");
Collection values = hashMap.values();
// (1) 增强for
for (Object value : values){
System.out.println(value);
}
// (2) 迭代器
Iterator iterator1 = values.iterator();
while (iterator1.hasNext()) {
Object value = iterator1.next();
System.out.println(value);
}
// 第三组 entrySet
System.out.println("----第三组------");
Set entrySet = hashMap.entrySet();
// (1) 增强for
for (Object entry : entrySet){
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "--" + m.getValue());
}
// (2) 迭代器
Iterator iterator2 = entrySet.iterator();
while (iterator2.hasNext()) {
Object entry = iterator2.next();
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "--" + m.getValue());
}
4.HashMap小结
1.Map接口的常用实现类:HashMap、Hashtable、Properties
2.HashMap是Map接口使用频率最高的实现类
3.HashMap是以key-val对的方式来存储数据(HashMap$Node类型)
4.key不能重复,但是值可以重复,允许使用nul键和null值
5.如果添加相同的key,则会覆盖原来的key-val,等同于修改(key不会替换,val会替换)
6.与HashSet一样,不保证映射的顺序,因为底层是以hash表的方式来存储的(jdk8的hashMap底层 数组+链表+红黑树)
7.HashMap没有实现同步,因此是线程不安全的,方法没有做同步互斥的操作,没有synchronized
5.HashMap底层机制及源码剖析
1.HashMap底层维护了Node类型的数组table,默认为null
2.当创建对象时,将加载因子(loadfactor)初始化为0.75.
3.当添加key-val时,通过key的哈希值得到在table的索引。然后判断该索引处是否有元素,如果没有元素则直接添加。如果不相等需要判断是树结构还是链表结构,做出相应处理。如果添加时发现容量不够,则需要扩容。
4.第一次添加,则需要扩容table容量为16,临界值(threshold)为12(16*0.75)
5.以后再扩容,则需要扩容table容量为原来的2倍(32),临界值为原来的2倍,依次类推。
6.在Java8中,如果一条链表的元素个数超过TREEIFY_THRESHOLD(默认是8),并且table的大小>=MIN_TREEIFY_CAPACITY(默认64),就会树化(红黑树)。
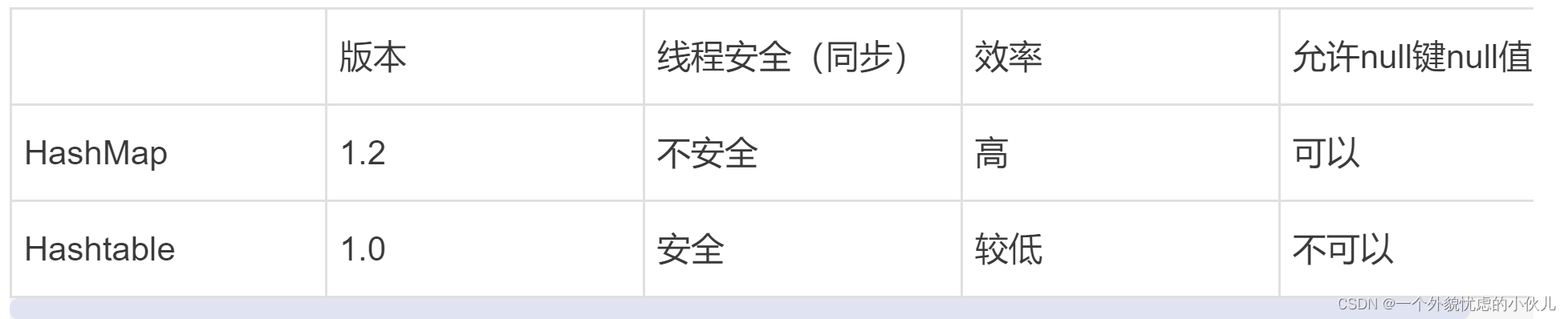
6.HashTable的基本介绍
1.存放的元素是键值对:即K-V
2.hashtable的键和值都不能为null
3.hashTable使用方法基本上和HashMap一样
4.hashTable是线程安全的,hashMap是线程不安全的
7.Hashtable 和 HashMap对比
8.Properties基本介绍
1.Properties类继承自Hashtable类并且实现了Map接口,也是使用一种键值对的形式来保存数据
2.他的使用特点和Hashtable类似
3.Properties还可以用于从xxx.properties文件中,加载数据到4.Properties类对象,并进行读取和修改
说明:工作后xxx.properties文件通常作为配置文件,这个知识点在IO流
9.Map接口实现类-TreeMap
9.1TreeMap基本特点
1.使用默认的构造器创建TreeMap,是无序的
2.提供了一个可以传入Comparator接口内部类
TreeMap treeMap = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String) o1).compareTo((String) o2);
}
});
五、总结-开发中如何选择集合实现类
1.先判断存储的类型
2.一组对象【单列】:Collection接口
2.1 允许重复:List
1.增删多:ListedList【底层维护了一个双向链表】
2.改查多:ArrayList【底层维护Object类型的可变数组】
2.2 不允许重复:Set
1.无序:HashSet【底层是HashMap,维护了一个哈希表 即(数组+链表+红黑树)】
2.排序:TreeSet
3.插入和取出顺序一致:LinkedHashSet,维护数组+双向链表
3.一组键值对【双列】:Map
1.键无序:HashMap【底层是:哈希表 jdk7:数组+链表,jdk8:数组+链表+红黑树】
2.键排序:TreeMap
3.键插入和取出顺序一致:LinkedHashMap
4.读取文件 Properties
总结
本篇主要介绍了Java集合章节主要的类与接口的特点和简单使用方法,以及从源码层面剖析了各种接口方法的元素存、取特性,以至于实际开发中我们可以快速判断出具体的业务场景该使用何种集合类/接口以满足性能和功能上的需求,另外该章节仍有未完善的地方,后期会继续补充。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/71710.html

