
一、什么是集合
概念:
对象的容器,实现了对对象常用的操作
和数组的关系:
1、数组长度固定,集合长度不固定;
2、数组可以存储基本数据类型和引用数据类型。集合只能存储引用数据类型。
二、Collection体系


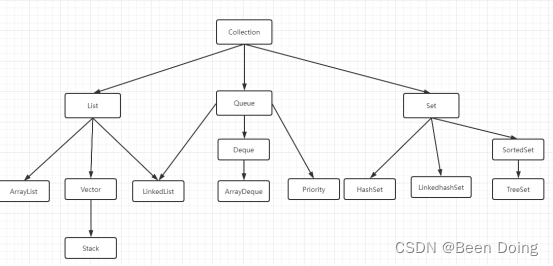
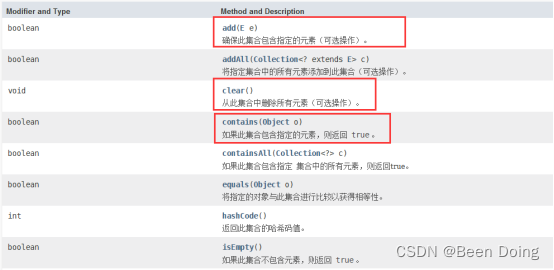
Collection 里还定义了很多方法,主要是用于数据的[增删改查],也叫 CRUD:
三、List(特点:有序,可重复)
特点:有序、有下标、元素可重复
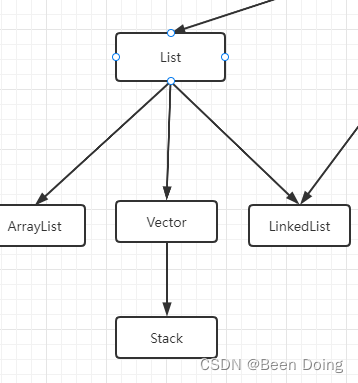
List 的实现方式有 LinkedList 和 ArrayList 两种,那面试时最常问的就是这两个数据结构如何选择。
对于这类选择问题:
一是考虑数据结构是否能完成需要的功能;
如果都能完成,二是考虑哪种更高效。
那具体来看这两个 classes 的 API 和它们的时间复杂度:

那造成时间复杂度的区别的原因是什么呢?
答:
- 因为 ArrayList 是用数组来实现的。LinkedList是基于链表实现的。
- 而数组和链表的最大区别就是数组是可以随机访问的(random access)。
下面我们来看看各自的数据结构的特点:
1、数组结构: 存储区间连续、内存占用严重、空间复杂度大
优点:随机读取和修改效率高,原因是数组是连续的(随机访问性强,查找速度快)
缺点:插入和删除数据效率低,因插入数据,这个位置后面的数据在内存中都要往后移动,且大小固定不易动态扩展。
2、链表结构:存储区间离散、占用内存宽松、空间复杂度小
优点:插入删除速度快,内存利用率高,没有固定大小,扩展灵活
缺点:不能随机查找,每次都是从第一个开始遍历(查询效率低)
3、哈希表结构:结合数组结构和链表结构的优点,从而实现了查询和修改效率高,插入和删除效率也高的一种数据结构
ArrayList:源码分析;
/**
* Default initial capacity. 默认初始容量
*/
private static final int DEFAULT_CAPACITY = 10;
transient Object[] elementData; //存放元素的元数据
/**
* The size of the ArrayList (the number of elements it contains).
* ArrayList 的大小(它包含的元素数量)。
* @serial
*/
private int size;
Add方法;


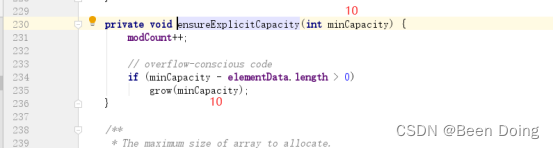
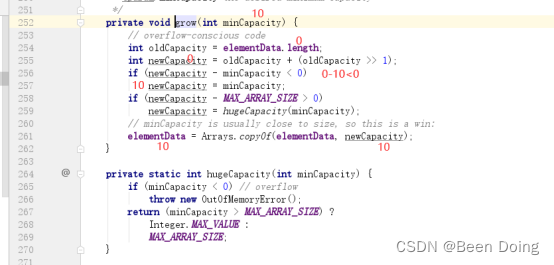
小结:
1、如果没有向容器中添加任何的元素,容器为0;添加元素之后,容量为初始容量为10;
2、ArrayList底层数组每次扩容的大小都是1.5倍
LinkedList:源码分析;
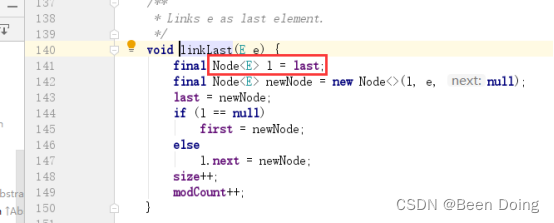
进入LinkedList的方法,查找add方法;

要想添加数据,就要搞明白linkLast 方法;
进入Node 方法;你会发现这就是LinkedList的底层结构;
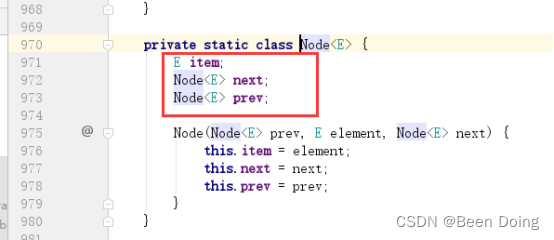
arraylist和linkedlist的区别
1、数据结构不同
ArrayList是Array(动态数组)的数据结构,LinkedList是Link(链表)的数据结构。
2、效率不同
ArrayList:必须开辟连续空间,查询快,增删慢。
LinkedList:无需开辟连续空间,查询慢,增删快。
3、自由性不同
ArrayList自由性较低,因为它需要手动的设置固定大小的容量,但是它的使用比较方便,只需要创建,然后添加数据,通过调用下标进行使用;
LinkedList自由性较高,能够动态的随数据量的变化而变化,但是它不便于使用。
4、主要控件开销不同
ArrayList主要控件开销在于需要在List列表预留一定空间;
LinkList主要控件开销在于需要存储结点信息以及结点指针信息。
拓展:
- LinkedList是基于双向循环链表实现的,除了可以当做链表来操作外,它还可以当做栈、队列和双端队列来使用。
- LinkedList同样是非线程安全的,只在单线程下适合使用。
- LinkedList实现了Serializable接口,因此它支持序列化,能够通过序列化传输,实现了Cloneable接口,能被克隆。
什么是链表
链表是由一系列非连续的节点组成的存储结构,简单分下类的话,链表又分为单向链表和双向链表,而单向/双向链表又可以分为循环链表和非循环链表,下面简单就这四种链表进行图解说明。
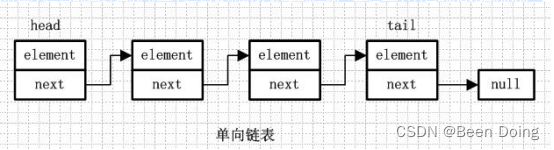
1、单向链表
2、单向链表就是通过每个结点的指针指向下一个结点从而链接起来的结构,最后一个节点的next指向null。
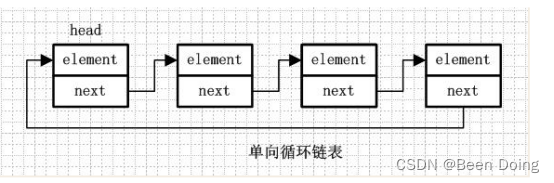
3、单向循环链表
4、单向循环链表和单向列表的不同是,最后一个节点的next不是指向null,而是指向head节点,形成一个“环”。
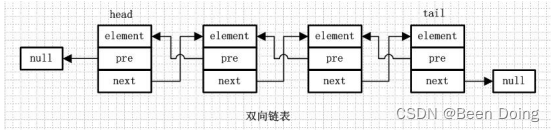
5、双向链表
6、从名字就可以看出,双向链表是包含两个指针的,pre指向前一个节点,next指向后一个节点,但是第一个节点head的pre指向null,最后一个节点的tail指向null。
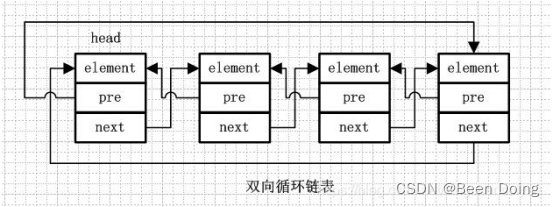
7、双向循环链表
8、双向循环链表和双向链表的不同在于,第一个节点的pre指向最后一个节点,最后一个节点的next指向第一个节点,也形成一个“环”。而LinkedList就是基于双向循环链表设计的。
什么是红黑树
https://blog.csdn.net/jiang_wang01/article/details/113715033
四、Set(无序,不可重复)
特点:无序、无下标、元素不可重复

Set 的常用实现类有三个:
HashSet:
采用 HashMap 的 key 来储存元素,主要特点是无序的,基本操作都是 O(1) 的时间复杂度,很快。
存储结构:哈希表(数组+链表+红黑树)
存储过程(重复依据)
- 1.根据hashCode计算保存的位置,如果位置为空,直接保存,若不为空,进行第二步
- 2.再执行equals方法,如果equals为true,则认为是重复,否则形成链表
特点
- 基于HashCode计算元素存放位置
- 利用31这个质数,减少散列冲突
- 31提高执行效率 31 * i = (i << 5) – i 转为移位操作
- 当存入元素的哈希码相同时,会调用equals进行确认,如果结果为true,则拒绝后者存入
LinkedHashSet:
这个是一个 HashSet + LinkedList 的结构,特点就是既拥有了 O(1) 的时间复杂度,又能够保留插入的顺序。
TreeSet:
采用红黑树结构,特点是可以有序,可以用自然排序或者自定义比较器来排序;缺点就是查询速度没有 HashSet 快。
特点
- 基于排列顺序实现元素不重复
- 实现SortedSet接口,对集合元素自动排序
- 元素对象的类型必须实现Comparable接口,指定排序规则
- 通过CompareTo方法确定是否为重复元素
那每个 Set 的底层实现其实就是对应的 Map:
数值放在 map 中的 key 上,value 上放了个 PRESENT,是一个静态的 Object,相当于 place holder,每个 key 都指向这个 object
五、Map

map接口的特点:
1、用于存储任意的键值对(Key—Value)
2、键:无序,无下标,不允许重复(唯一)
3、值:无序,无下标,允许重复。
方法:
1.V put(K key, V value) 将对象存到集合中,关联键值
2.Object get(Object key) 根据键获得对应的值
3.Set 返回所有的Key ( keySet() 方法)
4.Collection values() 返回包含所有值的Collection集合
5.Set<Map.Entry<K, V>> 键值匹配的Set集合( entrySet(方法) )


HashMap【重点】
存储结构:哈希表(数组+链表+红黑树)
使用key可使hashcode和equals作为重复
原码分析总结:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 初始容量
static final int MAXIMUM_CAPACITY = 1 << 30;//HashMap的数组最大容量
static final float DEFAULT_LOAD_FACTOR = 0.75f; //默认的加载因子
static final int TREEIFY_THRESHOLD = 8; //当链表长度大于8时,转换为红黑树
static final int UNTREEIFY_THRESHOLD = 6;//当链表长度小于6时,转换为链表
static final int MIN_TREEIFY_CAPACITY = 64;//当链表长度大于8时,并且链表长度大于64时,调整为红黑树。
transient Node<K,V>[] table;//哈希表中的数组;
transient int size;//元素个数;
1、HashMap刚创建时,table是null,节省空间,当添加第一个元素时,table容量调整为 16
2、当元素个数大于阈值(16*0.75 = 12)时,会进行扩容,扩容后的大小为原来的两倍,目 的是减少调整元素的个数
3、jdk1.8 当每个链表长度 >8 ,并且数组元素个数 ≥64时,会调整成红黑树,目的是提高 效率
4、jdk1.8 当链表长度 <6 时 调整成链表
5、jdk1.8 以前,链表时头插入,之后为尾插入
Hash Map的put()和get()的实现原理:
1、map.put(k,v)实现原
(1)首先将k,v封装到Node对象当中(节点)。
(2)然后它的底层会调用K的hashCode()方法得出hash值。
(3)通过哈希表函数/哈希算法,将hash值转换成数组的下标,下标位置上如果没有任何元素,就把Node添加到这个位置上。如果说下标对应的位置上有链表。此时,就会拿着k和链表上每个节点的k进行equal。如果所有的equals方法返回都是false,那么这个新的节点将被添加到链表的末尾。如其中有一个equals返回了true,那么这个节点的value将会被覆盖。
2、map.get(k)实现原理
(1)先调用k的hashCode()方法得出哈希值,并通过哈希算法转换成数组的下标。
(2)通过上一步哈希算法转换成数组的下标之后,在通过数组下标快速定位到某个位置上。如果这个位置上什么都没有,则返回null。如果这个位置上有单向链表,那么它就会拿着K和单向链表上的每一个节点的K进行equals,如果所有equals方法都返回false,则get方法返回null。如果其中一个节点的K和参数K进行equals返回true,那么此时该节点的value就是我们要找的value了,get方法最终返回这个要找的value。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/71827.html

