
前言
我们做数据分析的时候经常会遇到去重问题,下面总结 sql 去重的几种方式,后续如果还有再补充,大数据分析层面包括 hive、clickhouse 也可参考。
准备
本文以 mysql 作为作为例子进行 sql 去重的实现。首先准备一张表:
创建表
t_score
create table t_score(
ts datetime,
id varchar(10),
name varchar(255),
score int(3)
)
datetime: 入库时间
id :学号
name:姓名
soce :分数
测试数据
insert into t_score value(now(), '101','zhangsan', 90);
insert into t_score value(now(), '101','zhangsan', 92);
insert into t_score value(now(), '101','zhangsan', 96);
insert into t_score value(now(), '102','lisi', 90);
insert into t_score value(now(), '102','lisi', 92);
insert into t_score value(now(), '103','wangwu', 96);
目标
最终目标是根据时间去重,将入库时间最新的数据留下,id 重复的认为是重复数据。
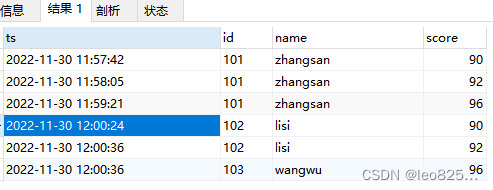

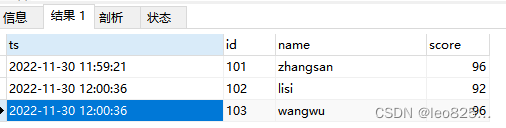
最终期望得到的结果为:
探索
distinct 去重
首先想到的就是 distinct 关键字去重,先要了解一下这个关键字的含义和用法。
含义:distinct用来查询不重复记录的条数,即distinct来返回不重复字段的条数(count(distinct id)),其原因是distinct只能返回他的目标字段,而无法返回其他字段。
用法注意:
1.distinct【查询字段】,必须放在要查询字段的开头,即放在第一个参数;
2.只能在SELECT 语句中使用,不能在 INSERT, DELETE, UPDATE 中使用;
3.DISTINCT 表示对后面的所有参数的拼接取不重复的记录,即查出的参数拼接每行记录都是唯一的
4.不能与all同时使用,默认情况下,查询时返回的就是所有的结果。
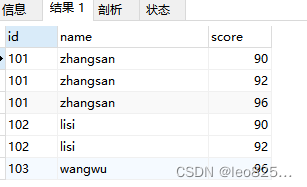
使用 distinct 不能满足我们的去重需求:
SELECT DISTINCT
( id ),
NAME,
score
FROM
t_score
group by 去重
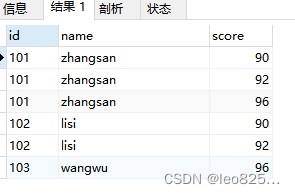
group by 是分组去重,但是仅仅使用group by 也达不到去重求最新的目的
SELECT
id,
name,
score
FROM
t_score
GROUP BY
id,
name,
score
实现方案
方案一
首先,取出来每行数据的最大时间(即最新时间),然后让原表数据和最大时间做右连接,得到的就是最新的数据。
SELECT
a0.*
FROM
t_score a0
RIGHT JOIN (
SELECT
max(ts) tsMax,
id
FROM
t_score
GROUP BY
id
) b0 ON a0.ts = b0.tsMax
AND a0.id = b0.id
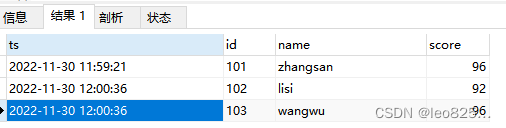
方案二
方案二为方案一的变种,使用了exists 关键字来获取时间上最新的数据
SELECT
a0.*
FROM
t_score a0
WHERE
EXISTS (
SELECT
*
FROM
(
SELECT
max(ts) tsMax,
id
FROM
t_score
GROUP BY
id
) b0
WHERE
b0.tsMax = a0.ts
AND b0.id = a0.id
)
方案三
使用 row_number() over (parttion by 分组列 order by 排序列) 方式
SELECT
*
FROM
( SELECT *, row_number() over ( PARTITION BY id ORDER BY ts DESC ) num FROM t_score ) a0
WHERE
a0.num = 1
需要注意的是:MySQL从8.0开始支持窗口函数
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/72589.html

