
布隆过滤器介绍
布隆过滤器(Bloom Filter)由 Burton Howard Bloom 在 1970 年提出,是一种空间效率高的概率型数据结构。它专门用来检测集合中是否存在特定的元素。
布隆过滤器带有以下特点:
- 一个很长的二进制向量(位数组)
- 一系列随机函数(哈希)
- 空间效率和查询效率高
- 有一定的误判率(哈希表是精确匹配)
布隆过滤器原理
布隆过滤器(Bloom Filter)的核心是实现一个超大的位数组和几个哈希函数。
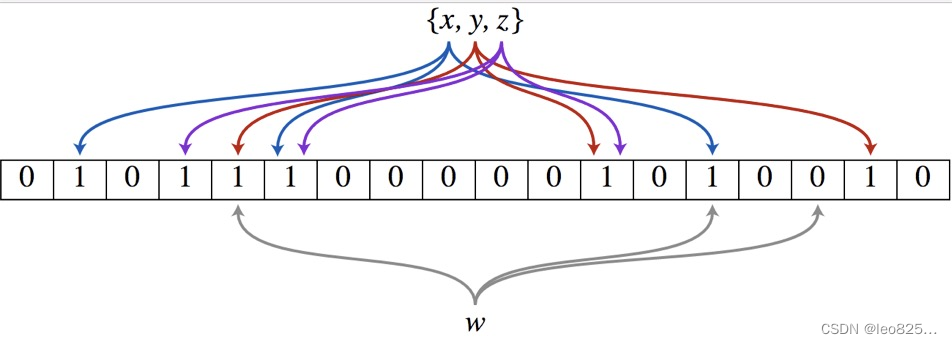
假设位数组的长度为m,哈希函数的个数为k,以上图为例。
具体操作流程如下:
- 假设集合里面有3个元素 {x,y,z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置为0。
- 对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为1。
- 查询 W 元素是否存在集合中的时候,同样的方法将 W 通过哈希映射到位数组上的3个点。
- 如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。 反之,如果3个点都为1,则该元素可能存在集合中。
- 注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。
- 可以从图中可以看到:假设某个元素通过映射对应下标为4、5、6这3个点。虽然这3个点都为1,但是很明显这3个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在稽核中,也可能对应的都是1,这是误判率存在的原因。
布隆过滤器添加元素
- 将要添加的元素给k个哈希函数
- 得到对应于位数组上的k个位置
- 将这k个位置设为1
布隆过滤器查询元素
- 将要查询的元素给k个哈希函数
- 得到对应于位数组上的k个位置
- 如果k个位置有一个为0,则肯定不在集合中
- 如果k个位置全部为1,则可能在集合中
布隆过滤器的优缺点与用途
优点
- 不需要存储数据本身,只用比特表示,因此空间占用相对于传统方式有巨大的优势,并且能够保密数据;
- 时间效率也较高,插入和查询的时间复杂度均为O(k);
- 哈希函数之间相互独立,可以在硬件指令层面并行计算。
缺点
- 存在假阳性的概率,不适用于任何要求 100% 准确率的场景;
- 只能插入和查询元素,不能删除元素,这与产生假阳性的原因是相同的。我们可以简单地想到通过计数(即将一个比特扩展为计数值)来记录元素数,但仍然无法保证删除的元素一定在集合中。
所以,Bloom Filter 在对查准度要求没有那么苛刻,而对时间、空间效率要求较高的场合非常合适,本文第一句话提到的用途即属于此类。另外,由于它不存在 假阴性 问题,所以用作“不存在”逻辑的处理时有奇效,比如可以用来作为 缓存系统(如Redis)的缓冲,防止缓存穿透。
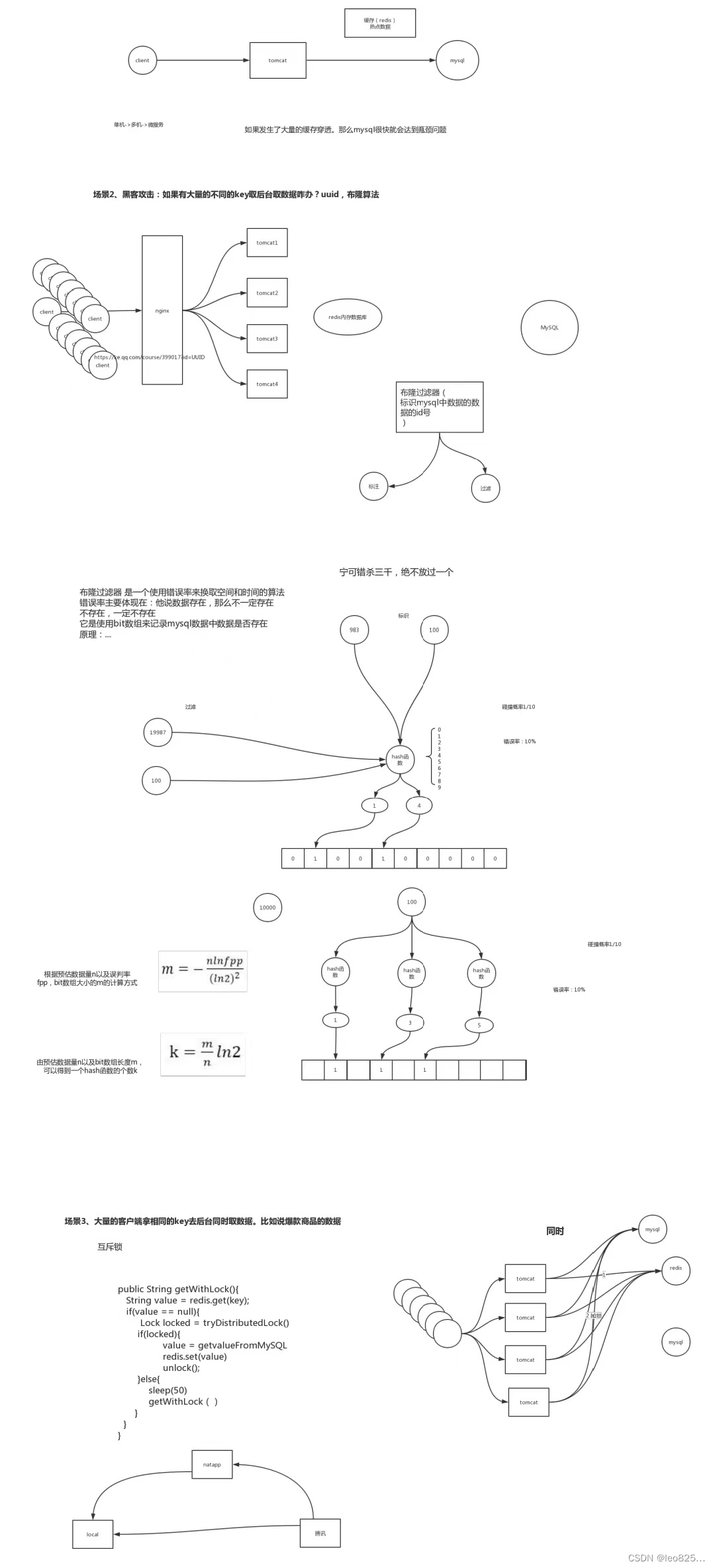
布隆过滤器使用场景
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/72606.html

