
文章目录
前言—-目标检测要解决的3大问题
目标检测要解决的3大问题:
1、有没有?
图片中是否有要检测的物体?(检测物体,判定前景背景)
2、是什么?
这些物体分别是什么?(检测到的物体是什么)
3、在哪里?
这些物体在哪里?(画框,描边,变色都行)
一、YOLOv1简介
YOLOv1 (You Only Look Once) 是一种目标检测模型,它可以在单张图像中同时检测多个目标。YOLOv1 的主要特点包括:
快速:YOLOv1 可以在实时运行,其运行速度较快。
简单:YOLOv1 的网络结构简单,容易理解。
高效:YOLOv1 在检测准确率和速度之间取得了较好的平衡。
YOLOv1 使用了卷积神经网络 (CNN) 作为基础模型,并使用了一种称为“联合分类与回归”的损失函数来训练模型。在预测过程中,YOLOv1 先对输入图像进行特征提取,然后使用全连接层进行预测,得到图像中可能存在的目标的边界框。最后,YOLOv1 会将所有边界框的预测结果作为最终的目标检测预测结果。
二、YOLOv1的核心思想—-(真正的重点)
1、真实图片需表达的数据
1、问题的表达
- 物体有没有,可以用一个变量来表达有无,例如0-1模式,1代表有,0代表无
- 物体是什么,可以用一串变量来表达,变量之间是平权的,即,没有高低贵贱之分,一个变量代表一种类别。例如可以用one-hot来编码
- 物体在哪里,可以用一个矩形框,框出来(比描边变色都省事),矩形框用4角坐标、或左上角和右下角坐标、或用中心点坐标与宽高表达都可以。我们用中心点和宽高吧(
数据集一般给的是左上角和右下角坐标,可以在程序中转化成中心点与宽高的方式,这里为了表达YOLOV1的思想就这样说了)
2、关系的表达
- 123条必须同时存在:有了物体就要分辨种类就要画出框来,这三个问题是一个统一体(
注意:三个问题不统一,就出现有物体我不标框,有框我不承认这是个物体等情况,这不就胡扯了嘛)。既然统一那我们就要通过一种方式把这三个问题关联起来,这样我们全部问题从关联处出发,进而表达这三个问题。
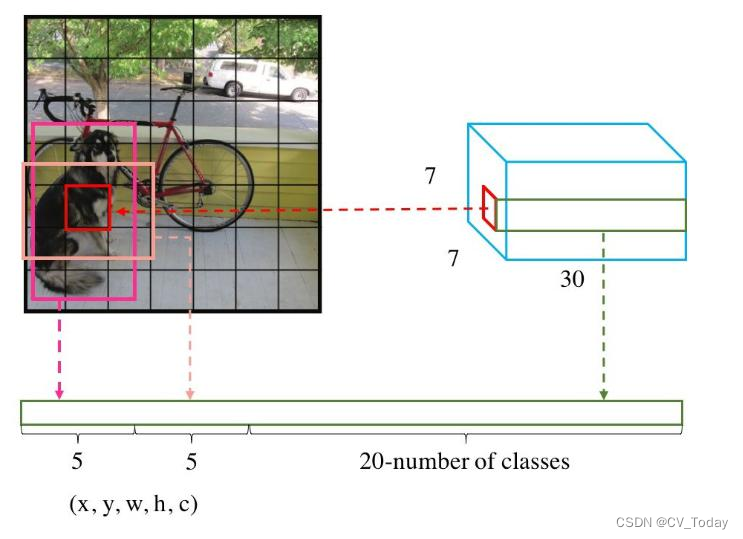
这个关联处,我们此时选择了网格(grid cell),就是把一张图片分成棋盘一样的N个网格(grid cell)。
例如,图片宽高7等分(这个随心所欲,保持奇数就行)就出现 7 * 7=49 个网格(grid cell),每个网格(grid cell)关联3个问题。换句话讲就是:表达这3个问题的数学变量要存放到网格(grid cell)之中。
- 物体有没有,要看该网格(grid cell)有没有被标记为1(该网格(grid cell)的1, 0状态)
- 物体是什么,要看该网格(grid cell)在标为1的前提下,该网格(grid cell)的那一串变量中哪一个被标为1,类别就属于那个变量代表的种类
- 物体在哪里,要看该网格(grid cell)与标注框的位置关系。具体来讲就是框有中心点,那中心点位置和我们网格(grid cell)的位置关系表达一下。在中心点与网格(grid cell)关联后,至于宽高的值就没必要跟网格(grid cell)关联了,具体的宽高跟整幅图片去关联好了(
物体的宽高和固定的网格(grid cell)大小,我们觉得产生不了关系,反而跟整幅图片关系更大,应该存在比例关系;你想想你在拍照的时候,物体尺寸比例应该是按整幅图片去构思拍摄的)。


以上实际就完成了对真实图片的数学建模。那么接下来做什么呢?
2、预测信息如何表达?
我们的目的不是看真实标注的信息,而是重点看我们预测的信息。
计算机预测信息也如我们的真实信息一般,需回答同样三个问题,那么计算机通过什么方式来回答我们呢?(猜,是的没错,计算机就是在瞎猜)
既然是在瞎猜,那我们给计算机立几条猜的规则吧!(猜不好听还是说预测吧)
1、规则一,数据总量
- 首先要明白预测是随机的(学习的过程才是有方向性的),我们直接按照真实数据的思路,去创造所需的数据个数,从网格(grid cell)角度出发,7 * 7 * (1+4+N)个数据。大方向上总计3个维度、2个含义,7 * 7是网格(grid cell),(1+4+N)是每个网格(grid cell)关联的数据。包含是否为物体
c
1
c_1
c1,框的中心坐标(x
1
x_1
x1,y
1
y_1
y1)与宽高(w
1
w_1
w1,h
1
h_1
h1),分类数N。YOLOV1预测了20种目标,所以N也就是20了。那就简单看来是7 * 7 * 25了,但yolo实际用了7 * 7 * 30个数据,**多出来的5个数据,实际是yolo把每个格子的预测从单一框,变成了多样框。这样每个网格(grid cell)多了一个框,一个框带一组数据**(是否为物体c
2
c_2
c2,框的中心坐标(x
2
x_2
x2,y
2
y_2
y2)与宽高(w
2
w_2
w2,h
2
h_2
h2)),目的是更多样的寻找目标(由于没有指定框的比例及大小,因此这里并不能将bbox认定为Anchor,而仅仅是多个随机框,并行寻找对象,谁更接近对象就留下谁),有利于模型更快收敛。综上我们需要创造7 * 7 * 30 = 1470个数据。每个网格(grid cell)需要30个数据来表达,也就是计算机每次必须预测1470个数据出来,供我们使用。(再次说明我们是要1470个,够我们用来表达信息的数量就好,具体是什么数,那是后话,我们先不用操心)
2、规则二,预测数据的量化
- 每个网格(grid cell)关联的数据数量(30个)有了,数据的内涵(是否有物体1,中心坐标2,宽高2,分类20)有了,那么接下来就要让计算机表达的数据进行量化分析了。只有量化了预测的数据,才能在数学上表达预测的准不准。
那么计算机输出什么数据呢?
1、计算机表达,有无的问题:
先看真实数据怎么表达的,如果格子内有物体,则Pr( Object )=1,否则Pr( Object )=0 。这表达了真实数据的状况(人作为教学者、先验的存在,我们的判断是百分之百,是基准,是标量)(
当然我们也可以用0-1之间的数字,来告诉计算机我们对图片目标的把握程度那是后来的发展,这里不表)
那么计算机怎么表达有无的问题呢?用Pr( Object )=1,或Pr( Object )=0 吗?不可以!它作为一个受训者、学习者,如果只告诉我们有和没有,我们无法掌握它在这个问题上的学习水平,因此它要告诉我们的是,它有多大把握认为“有”,这个就是置信度。(同样这个值他是蒙的,毫无根据,我们现在解决的是他的表达方式,而不是表达内容)
即它要输出0-1之间的数字来表达。但yolov1 输出的是从
−
∞
到
+
∞
-∞到+∞
−∞到+∞ 的任意实数,虽不影响表达,但确实收敛速度上慢了些,这个现象存在于全部输出中,以后进行了改进
2、计算机表达,是什么的问题:
同有无问题类似,在是什么的问题上,我们告诉计算机的数据是先验的绝对的,20个类互斥的。
计算机表达20个类对应的变量,先盲猜把数据填进去。我们就一个要求,计算机猜的数字,必须让我们能量化它的学习水平。
计算机表达出每一种类别对应的数据,全部类别要看成整体去统一度量。
所以对计算机猜出的20个数字我们要进行softmax处理,以方便量化。如下:
具体来说,对于网格(grid cell)
i
i
i,输出一个网格(grid cell)类别数据向量
C
i
\mathbf{C}_i
Ci,假设类别
j
j
j 有
20
20
20 个,因此,对于每个格口
i
i
i,类别数据可以表示为:
C
i
=
[
c
i
1
,
c
i
2
,
…
,
c
i
20
]
\mathbf{C}_i = \left[ c_{i1}, c_{i2}, \dots, c_{i20} \right]
Ci=[ci1,ci2,…,ci20]
其中,[
c
i
j
c_{ij}
cij] 表示网格(grid cell)
i
i
i 属于类别
j
j
j 的数据。
注意,类别数据向量
C
i
\mathbf{C}_i
Ci 是由模型随机输出的,它并不是真实的概率。
c
i
j
c_{ij}
cij是在
−
∞
到
+
∞
-∞到+∞
−∞到+∞ 间取值,因此还不能称之为概率,若要概率还需进一步操作。
即,使用 softmax 函数进行归一化就得到了概率表达:
P
(
c
l
a
s
s
j
)
=
e
c
i
j
∑
j
=
1
20
e
c
i
j
P(class_j ) = \frac{e^{c_{ij}}}{\sum_{j=1}^{20}e^{c_{ij}}}
P(classj)=∑j=120ecijecij
注意:在判断类别概率的时候我们默认了一个前提,那就是只有网格(grid cell)存在物体的前提下,我们才用这20维数据去计算概率,不存在物体的网格(grid cell)数据,我们不计算概率。于是上述公式丰富为条件概率:
P
(
c
l
a
s
s
i
∣
O
b
j
e
c
t
)
=
e
c
i
j
∑
j
=
1
20
e
c
i
j
P(class_i | Object) = \frac{e^{c_{ij}}}{\sum_{j=1}^{20}e^{c_{ij}}}
P(classi∣Object)=∑j=120ecijecij
3、计算机表达,在哪里的问题:
对于在哪里的位置问题,我们前面选用了4个变量存储,计算机随便的搞出4个数据分别填入(x, y, w, h)中。
跟真实图片的逻辑一致,计算机生成的前两个数据并不是物体中心坐标,必须通过网格位置映射之后才能解读为中心坐标。
这四个变量我们要进行解读,必须也做成可量化的度。

首先对于前两个变量,这两个坐标是属于这个网格的,因此它必须和网格发生关系,而不能直接表达为图像上的某点坐标。所以过程就变为了,每个网格与图像是绝对位置关系,x,y成为依附在网格上的值!
那么怎么去度化它呢?我们可以选择这样的方式:
x
c
=
x
∗
S
G
+
x
G
x_c = x * S_G + x_G
xc=x∗SG+xG
y
c
=
y
∗
S
G
+
y
G
y_c = y * S_G + y_G
yc=y∗SG+yG
其中,
x
x
x 是相对网格x方向偏移量,
y
y
y 是相对网格y方向偏移量,
S
G
S_G
SG 是网格(grid cell)单元的大小即单元格的尺寸(448448的图像分成77份,一份的长度就是64像素),
x
G
x_G
xG是网格(grid cell)单元左上角的
x
x
x坐标,
y
G
y_G
yG是网格(grid cell)单元左上角的
y
y
y坐标,(
x
c
x_c
xc,
y
c
y_c
yc) 这就是我们能直观理解的图像坐标了。v1并没有对预测的x,y进行限制 其取值是从
−
∞
-∞
−∞到
+
∞
+∞
+∞的,因此预测框会有超出图片的可能

对于(w, h)即width,height是相对于整幅图像的比例预测值(
注意:w,h是比例值不是最终值为何到处都是相对值,因为相对才有比较意义,模型才有收敛的根基)真实的宽与高我们通过如下计算
w
c
=
w
∗
W
b
w_{c} = w * W_b
wc=w∗Wb
h
c
=
h
∗
H
b
h_{c}=h*H_b
hc=h∗Hb
其中
w
w
w是宽度比例值,
h
h
h是高度比例值,
W
b
W_b
Wb是输入图像的宽度,
H
b
H_b
Hb是输入图像的高度,
w
c
w_{c}
wc是转化后的框宽度,
h
c
h_{c}
hc是转化后的框高度。
4、举例:
综合输出一组30维向量如下:计算机随机乱猜数据,我们只能强行定义每一个数据的意义,而无法掌握它的值,要想使预期和真实值相符,我们要对数据进行处理,同时还需要下一节的误差反馈,从而闭环整个流程。
 数据处理以物体是什么举例:
数据处理以物体是什么举例:
先对
[
2.2
,
87.4
,
−
2.6
,
1.5
,
6.2
,
3.8
,
−
2.8
,
4.8
,
−
8.9
,
4.6
,
9.6
,
7.4
,
−
5.1
,
0.4
,
0.7
,
10.3
,
8.6
,
1.8
,
1.4
,
2.8
]
[2.2, 87.4, -2.6, 1.5, 6.2, 3.8, -2.8, 4.8, -8.9, 4.6, 9.6, 7.4, -5.1, 0.4, 0.7, 10.3, 8.6, 1.8, 1.4, 2.8]
[2.2,87.4,−2.6,1.5,6.2,3.8,−2.8,4.8,−8.9,4.6,9.6,7.4,−5.1,0.4,0.7,10.3,8.6,1.8,1.4,2.8]进行softmax处理得到以下数值
[3.36787944e-04, 9.99663212e-01, 3.36787944e-04, 3.36787944e-04, 3.36787944e-04, 3.36787944e-04, 3.36787944e-04, 3.36787944e-04, 3.36787944e-04, 3.36787944e-04, 3.36787944e-04, 3.36787944e-04, 3.36787944e-04, 3.36787944e-04, 3.36787944e-04, 3.36787944e-04, 3.36787944e-04, 3.36787944e-04, 3.36787944e-04]
按概率分布进行解读,保留小数点后两位如下:
[0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0].
可以解读为,真实的苹果在类别上被预测为汽车(1.0)。
后续不断地拿误差抽打它(训练)最终让它输出成如下状态
 类别经过softmax按概率分布进行解读,保留小数点后两位如下:
类别经过softmax按概率分布进行解读,保留小数点后两位如下:
[0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0].
可以解读为,真实的苹果在类别上被预测为苹果(1.0)。
小结
到此为止,真实图片与预测图片对这三个问题的解答我们已经探讨完了。
真实的思路情况肯定不会一次就考虑的这么多,而是边思考边建模,有的问题容易表达,不容易实现,因此整个过程实际是在1-2-3之间反复横跳。这个v1的思考是初次,后续也是不断更新的,比如联结点问题,在第二代就从网格改到了框上
三、yolov1的关键信息—-差距的表达与量化
YOLOV1是这样理解那3个问题的,我已经知道我盲猜的数据有多少,每个数据的含义我也明白了,那么我猜的怎么样呢?
谁能告诉我的水平如何呢?好烦啊!!!又出来一个问题。
我们如果能告诉它做出来的结果和真实结果误差有多大,把他的误差衡量出来就解决了!
损失函数,所谓损失不就是形容误差的么!!!(SO eazy,妈妈再也不用担心我的学习了!)
这里一定要注意,训练阶段输出的数据就是瞎猜,只有经过损失的鞭打,网络才会猜的较为靠谱,但仍然是在猜(包括测试阶段)!
那么解决问题的重点就落在,如何形容误差和如何量化误差。
1.是否有要检测的物体
如何去描述误差呢?最直观的就是最小二乘,得到偏差,即
(
C
−
C
^
)
2
(C-\hat{C})^2
(C−C^)2。其中
C
C
C真实数据的值,只取0或1,
C
^
\hat{C}
C^为预测输出
[
−
∞
,
+
∞
]
[-∞,+∞]
[−∞,+∞]后归一化的值。
这里要用此公式进行误差计算,还有一个大前提,那就是必须在正确的情况下才能衡量。那什么是正确呢?
正确,即网格真实为有物体
P
r
(
O
b
j
e
c
t
)
=
1
Pr( Object )=1
Pr(Object)=1,预测为有物体
P
r
(
O
b
j
e
c
t
)
=
1
Pr( Object )=1
Pr(Object)=1。网格真实为非物体
P
r
(
O
b
j
e
c
t
)
=
0
Pr( Object )=0
Pr(Object)=0,预测为非物体
P
r
(
O
b
j
e
c
t
)
=
0
Pr( Object )=0
Pr(Object)=0。这就是正确!
一个网格是有B个bbox的即B个置信度,我们该用哪一个作为我们想要的置信度来计算误差呢?
我们分解来看,对于有物体存在的单元格,B个置信度,我们不按置信度大小算(因为他是瞎蒙的一个数)。我们用框来选择,就是哪个bbox蒙的框与真实框接近(IOU大),我们判定为正样本。(这里无需使接近程度达到某个阈值,因为训练阶段都是在瞎蒙,)我们就调教这个框所蒙的置信度,让其值逼近1,误差逼近0。其它负样本完全放弃不管。
第一个概念IOU
IOU(Intersection over Union)是衡量两个边界框重合度的一种指标。具体来说,IOU 表示两个边界框的交集(Intersection)与并集(Union)的比值。
设两个边界框分别为 A 和 B,则 IOU 的计算公式如下:
IOU = (A ∩ B) / (A ∪ B)
其中,A ∩ B 表示两个边界框的交集,A ∪ B 表示两个边界框的并集。
IOU 的取值范围在 0 到 1 之间,越接近 1 表示两个边界框的重合度越高,反之则越低。

第二个概念正样本
在实际过程中,我们常常会发现预测边界框与真实边界框的位置并不完全重合。这时候我们就需要用到交并比来确定哪些预测边界框是正样本,哪些是负样本。
换个表达方式就是:对一个bbox来说当它对应网格有物体时(1
i
j
o
b
j
=
1
\text{1}_{ij}^{obj}=1
1ijobj=1则
1
i
j
n
o
o
b
j
=
0
\text{1}_{ij}^{noobj}=0
1ijnoobj=0),我们计算预测的近1误差;当它对应网格无物体时(
1
i
j
n
o
o
b
j
=
1
\text{1}_{ij}^{noobj}=1
1ijnoobj=1则
1
i
j
o
b
j
=
0
\text{1}_{ij}^{obj}=0
1ijobj=0),我们计算预测的近0误差。
1
i
j
o
b
j
(
1
−
C
i
^
)
2
+
1
i
j
n
o
o
b
j
(
0
−
C
i
^
)
2
\text{1}_{ij}^{obj}(1 – \hat{C_i})^2+ \text{1}_{ij}^{noobj} (0 – \hat{C_i})^2
1ijobj(1−Ci^)2+1ijnoobj(0−Ci^)2
由于一个网格有B个bbox,一幅图有S*S个网格,因此对一幅图来说所预测的损失误差如下:
∑
i
=
0
S
2
∑
j
=
0
B
1
i
j
o
b
j
(
C
i
−
C
i
^
)
2
+
∑
i
=
0
S
2
∑
j
=
0
B
1
i
j
n
o
o
b
j
(
C
i
−
C
i
^
)
2
\sum_{i=0}^{S^2} \sum_{j=0}^{B} \text{1}_{ij}^{obj}(C_i – \hat{C_i})^2+\sum_{i=0}^{S^2} \sum_{j=0}^{B}\text{1}_{ij}^{noobj} (C_i – \hat{C_i})^2
i=0∑S2j=0∑B1ijobj(Ci−Ci^)2+i=0∑S2j=0∑B1ijnoobj(Ci−Ci^)2
因为1
i
j
n
o
o
b
j
=
1
\text{1}_{ij}^{noobj}=1
1ijnoobj=1网格远远多于
1
i
j
o
b
j
=
1
\text{1}_{ij}^{obj}=1
1ijobj=1的网格,相应的
∑
i
=
0
S
2
∑
j
=
0
B
1
i
j
n
o
o
b
j
(
C
i
−
C
i
^
)
2
\sum_{i=0}^{S^2} \sum_{j=0}^{B}\text{1}_{ij}^{noobj} (C_i – \hat{C_i})^2
∑i=0S2∑j=0B1ijnoobj(Ci−Ci^)2损失远大于前者,这会使得网络想更快的降低该损失,而我们要平衡这两项损失,使得网络能均衡的预测。
因此要降低后一项的置信度损失(并不是更加关注前者的置信度损失),因此在第二项上加上一个较小的权重系数λ
n
o
o
b
j
\lambda_{noobj}
λnoobj,取
0.5
o
r
0.1
0.5or0.1
0.5or0.1
于是最终该部分的损失函数为:
∑
i
=
0
S
2
∑
j
=
0
B
1
i
j
o
b
j
(
C
i
−
C
i
^
)
2
+
λ
n
o
o
b
j
∑
i
=
0
S
2
∑
j
=
0
B
1
i
j
n
o
o
b
j
(
C
i
−
C
i
^
)
2
\sum_{i=0}^{S^2} \sum_{j=0}^{B} \text{1}_{ij}^{obj}(C_i – \hat{C_i})^2+\lambda_{noobj}\sum_{i=0}^{S^2} \sum_{j=0}^{B}\text{1}_{ij}^{noobj} (C_i – \hat{C_i})^2
i=0∑S2j=0∑B1ijobj(Ci−Ci^)2+λnoobji=0∑S2j=0∑B1ijnoobj(Ci−Ci^)2
2.物体分别是什么
谬误较多,请多勘正。未完待续。。。。2022年12月26日02:07:52
有了第一个损失函数,接下来我们谈谈第二个,也就是关于分类的损失函数,这部分较为容易理解:
首先我们将类别损失,定义在具有物体的网格中,也就是必须先有物体,我们才会计算损失,
1
i
o
b
j
=
1
\text{1}_{i}^{obj}=1
1iobj=1
我们只需要将真正图像标签的分类概率与·预测图像标签分类经过softmax处理之后的概率做最小二乘,以此为基础计算损失即,
(
p
(
c
)
−
p
^
(
c
)
)
2
(\ p(c) – \hat{p}(c))^2
( p(c)−p^(c))2
该网格全部类别的损失为:
∑
c
∈
c
l
a
s
s
(
p
i
(
c
)
−
p
^
i
(
c
)
)
2
\sum_{c \in class} (\ p_i(c) – \hat{p}_i(c))^2
c∈class∑( pi(c)−p^i(c))2
图片中全部网格的损失为:
∑
i
=
0
S
2
∑
c
∈
c
l
a
s
s
(
p
i
(
c
)
−
p
^
i
(
c
)
)
2
\sum_{i=0}^{S^2}\sum_{c \in class} (\ p_i(c) – \hat{p}_i(c))^2
i=0∑S2c∈class∑( pi(c)−p^i(c))2
筛选其中有目标物体的损失作为有效损失因此最终的该部分损失为:
∑
i
=
0
S
2
1
i
o
b
j
∑
c
∈
c
l
a
s
s
(
p
i
(
c
)
−
p
^
i
(
c
)
)
2
\sum_{i=0}^{S^2}\text{1}_{i}^{obj}\sum_{c \in class} (\ p_i(c) – \hat{p}_i(c))^2
i=0∑S21iobjc∈class∑( pi(c)−p^i(c))2
3.物体在哪里
最后一项内容的损失,我们同样使用最小二乘来做损失函数的计算。我们计算的是有目标物体的网格的最优bbox的损失,即
1
i
j
o
b
j
=
1
\text{1}_{ij}^{obj}=1
1ijobj=1这里有一个与上面不同的点,就是这里强调的有物体的网格的最优bbox的损失,先确定我们计算的是哪一个bbox,方法依旧是通过计算预测框与真是框之间的IOU(这一点与第一个损失的计算方式一致,不明白的可以往上翻看)。
对于bbox的四个值也就有了如下的计算
1
i
j
o
b
j
[
(
x
i
−
x
i
^
)
2
+
(
y
i
−
y
i
^
)
2
+
(
w
i
−
w
i
^
)
2
+
(
h
i
−
h
i
^
)
2
]
\text{1}_{ij}^{obj}[(x_i – \hat{x_i})^2+(y_i – \hat{y_i})^2+(w_i – \hat{w_i})^2+(h_i – \hat{h_i})^2]
1ijobj[(xi−xi^)2+(yi−yi^)2+(wi−wi^)2+(hi−hi^)2]
有个值得注意的问题就是,在宽高的损失中有这么点差异性,就是越小的目标框我们越在乎框的偏差
 如上图所示,在AB的IOU与AC的IOU相同的情况下,对同一个物体的预测中,我们视觉上更倾向于C框比B框更加优秀。
如上图所示,在AB的IOU与AC的IOU相同的情况下,对同一个物体的预测中,我们视觉上更倾向于C框比B框更加优秀。

谬误较多,请多勘正。2022年12月28日00:01:37
同样的,在AC的IOU与DE的IOU相同的情况下,在对不同物体预测试中,我们视觉上更倾向于C框比E框更加优秀。
因此我们必须加大对更小物体和更小框的惩罚,以使预测更加符合要求。
这里的关键就是对w和h的处理,我们希望在w和h较小时,误差能较大;w和h较大时,误差能较小,有很多方式可以实现这个要求。例如按尺寸给与权重,或者在wh本身上面进行开N次方处理。这里我们采用后者,YOLOv1也是如此解决的
1
i
j
o
b
j
[
(
x
i
−
x
i
^
)
2
+
(
y
i
−
y
i
^
)
2
+
(
w
i
−
w
i
^
)
2
+
(
h
i
−
h
^
i
)
2
]
\text{1}_{ij}^{obj}[(x_i – \hat{x_i})^2+(y_i – \hat{y_i})^2+(\sqrt w_i – \sqrt{\hat{w_i}})^2+(\sqrt h_i – \sqrt{\hat{h}_i})^2]
1ijobj[(xi−xi^)2+(yi−yi^)2+(wi−wi^)2+(hi−h^i)2]
将全部的框配合
1
i
j
o
b
j
1_{ij}^{obj}
1ijobj筛选之后的总损失如下:
∑
i
=
0
S
2
∑
j
=
0
B
1
i
j
o
b
j
[
(
x
i
−
x
i
^
)
2
+
(
y
i
−
y
i
^
)
2
+
(
w
i
−
w
i
^
)
2
+
(
h
i
−
h
^
i
)
2
]
\sum_{i=0}^{S^2} \sum_{j=0}^{B} 1_{ij}^{obj}[(x_i – \hat{x_i})^2+(y_i – \hat{y_i})^2+(\sqrt w_i – \sqrt{\hat{w_i}})^2+(\sqrt h_i – \sqrt{\hat{h}_i})^2]
i=0∑S2j=0∑B1ijobj[(xi−xi^)2+(yi−yi^)2+(wi−wi^)2+(hi−h^i)2]
拆开看就是
∑
i
=
0
S
2
∑
j
=
0
B
1
i
j
o
b
j
[
(
x
i
−
x
i
^
)
2
+
(
y
i
−
y
i
^
)
2
]
\sum_{i=0}^{S^2} \sum_{j=0}^{B} \text{1}_{ij}^{obj} \large[(x_i – \hat{x_i})^2+(y_i – \hat{y_i})^2]
i=0∑S2j=0∑B1ijobj[(xi−xi^)2+(yi−yi^)2]中心点损失
+
∑
i
=
0
S
2
∑
j
=
0
B
1
i
j
o
b
j
[
(
w
i
−
w
i
^
)
2
+
(
h
i
−
h
^
i
)
2
]
+\sum_{i=0}^{S^2} \sum_{j=0}^{B} \text{1}_{ij}^{obj}[(\sqrt w_i – \sqrt{\hat{w_i}})^2+(\sqrt h_i – \sqrt{\hat{h}_i})^2]
+i=0∑S2j=0∑B1ijobj[(wi−wi^)2+(hi−h^i)2]宽高损失
综合三大损失之后,我们又要注意到,在是否有目标,目标是什么,目标在哪里(物体改为目标更书面一点)这三个问题我们更加在意的目标在哪里的框是否更加精准,因此我们要加大对目标在哪里的损失的权重,因此总损失如下:
L
l
o
o
s
=
\large{L_{loos}} =
Lloos=中心点损失+宽高损失+置信度损失+分类损失
λ
c
o
o
r
d
∑
i
=
0
S
2
∑
j
=
0
B
1
i
j
o
b
j
[
(
x
i
−
x
i
^
)
2
+
(
y
i
−
y
i
^
)
2
]
\lambda_{coord}\sum_{i=0}^{S^2} \sum_{j=0}^{B} \text{1}_{ij}^{obj}[(x_i – \hat{x_i})^2+(y_i – \hat{y_i})^2]
λcoordi=0∑S2j=0∑B1ijobj[(xi−xi^)2+(yi−yi^)2]
+
λ
c
o
o
r
d
∑
i
=
0
S
2
∑
j
=
0
B
1
i
j
o
b
j
[
(
w
i
−
w
i
^
)
2
+
(
h
i
−
h
^
i
)
2
]
+\lambda_{coord}\sum_{i=0}^{S^2} \sum_{j=0}^{B} \text{1}_{ij}^{obj}[(\sqrt w_i – \sqrt{\hat{w_i}})^2+(\sqrt h_i – \sqrt{\hat{h}_i})^2]
+λcoordi=0∑S2j=0∑B1ijobj[(wi−wi^)2+(hi−h^i)2]
+
∑
i
=
0
S
2
∑
j
=
0
B
1
i
j
o
b
j
(
C
i
−
C
i
^
)
2
+\sum_{i=0}^{S^2} \sum_{j=0}^{B} \text{1}_{ij}^{obj}(C_i – \hat{C_i})^2
+i=0∑S2j=0∑B1ijobj(Ci−Ci^)2
+
λ
n
o
o
b
j
∑
i
=
0
S
2
∑
j
=
0
B
1
i
j
n
o
o
b
j
(
C
i
−
C
i
^
)
2
+\lambda_{noobj}\sum_{i=0}^{S^2} \sum_{j=0}^{B}\text{1}_{ij}^{noobj} (C_i – \hat{C_i})^2
+λnoobji=0∑S2j=0∑B1ijnoobj(Ci−Ci^)2
+
∑
i
=
0
S
2
1
i
o
b
j
∑
c
∈
c
l
a
s
s
(
p
i
(
c
)
−
p
^
i
(
c
)
)
2
+\sum_{i=0}^{S^2}\text{1}_{i}^{obj}\sum_{c \in class} (\ p_i(c) – \hat{p}_i(c))^2
+i=0∑S21iobjc∈class∑( pi(c)−p^i(c))2
总结
YOLOv1(You Only Look Once)是一种实时对象检测算法,可以在卷积神经网络的单个前向传递中检测图像中的所有对象。 它使用边界框来表示对象的位置,并使用回归模型来预测边界框的位置。
YOLOv1 背后的主要思想是将图像划分为单元格网格,并为每个单元格预测多个边界框。 对于每个边界框,YOLOv1 预测预测概率、类别概率和位置信息。 预测概率表示边界框是否包含对象,类概率表示边界框包含的对象的类别,位置信息表示边界框所在的位置。
YOLOv1 使用多个损失函数来训练模型,包括对象损失、类别损失和位置损失。 对象损失衡量边界框的预测概率与真实标签之间的差异,类别损失衡量边界框的类别概率与真实标签之间的差异,位置损失衡量边界框的位置与真实标签之间的差异。
总的来说,YOLOv1 是一种聪明有效的目标检测算法,能够实时检测目标。 然而,它有一些局限性,例如与其他物体检测算法相比精度较低,并且倾向于对单个物体进行多次检测。
谬误较多,请多勘正。2022年12月28日22:35:41
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/73207.html

