
欢迎关注博主 python老鸟 或 前往 『Python自学网』, 从基础入门免费课程开始,逐步深入学习python全栈体系课程,适合新手入门到精通全栈开发。
免费专栏传送门:《Python基础教程》
文本文件存储的内容是基于字符编码的文件,常见的编码有ASCII、UNICODE等
- Python2.x默认使用ASCII编码
- Python3.x默认使用UTF-8编码
一、ASCII编码和UNICODE编码
1.1》ASCII编码
ASCII编码可以说是最古老的编码了,是因为计算机最早是美国人发明的,美国人为了在计算机中使用自己的英语就制定了ASCII编码。
- 计算机中只有256个ASCII字符
- 一个ASCII在内存中占用一个字节的空间
- 8个0/1的排列组合方式一共有256种,也就是2**8
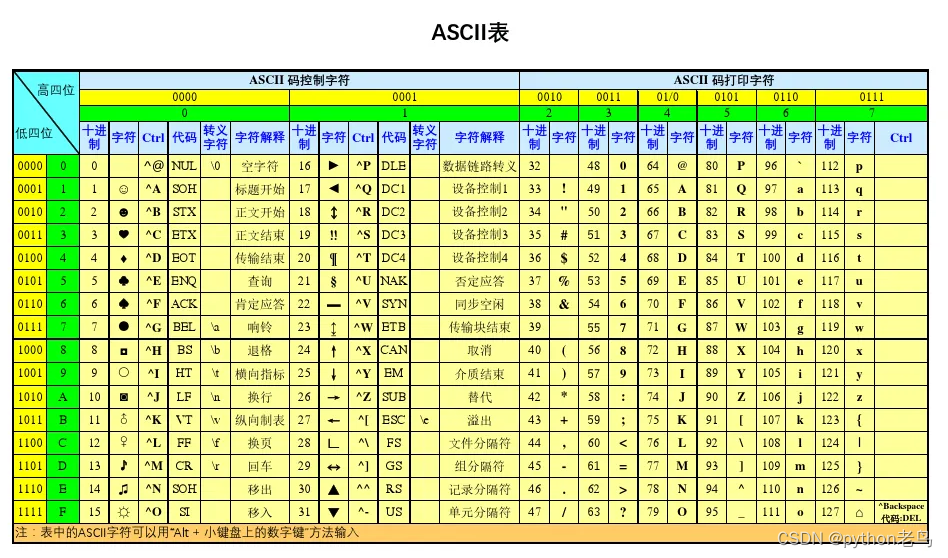
ASCCI编码只有256个字符,虽然可以涵盖26个英文,但是汉子有数以万计的字符,ASCII编码并不能满足我们,因此UNICODE编码诞生。
1.2》UNICODE编码
UTF-8编码格式:
- UTF-8是UNICODE编码的一种编码格式
- 计算机中使用1~6个字节表示一个UTF-8字符,涵盖了地球上几乎所有地区的文字
- 大多数汉子会使用3个字节表示
二、在Python2.x中如何使用中文
1、在python2.x文件的第一行增加以下代码,解释器会以UTF-8编码来处理Python文件
# *-* coding:utf8 *-*提示:这种方式是官方推荐使用过的。
2、也可这样,=号两边不要空格
# coding=utf8问题:
在python2.x中,即使指定了文件使用UTF-8的编码格式,但是在遍历字符串时,仍然会以字节为单位遍历字符串
答:
要能够正确的遍历字符串,在定义字符串时,需要在字符串的引导前增加一个小写字母u,告诉解释器这事一个unicode字符串(是使用UTF-8编码更是的字符串)
代码:这段代码在python2.x中汉子会出现很多符号
str = u"Python自学网"
for a in str:
print(a)代码优化:加u
# 引号前面的u告诉解释器这事一个utf-8编码格式的字符串
str = u"Python自学网"
for a in str:
print(a)三、万一Python3.x中不能读取文件里面的中文怎么办?
Python3.X 源码文件默认使用utf-8编码,所以可以正常解析中文,无需指定 UTF-8 编码。
python3查看默认编码:
模块:python3 sys.getdefaultencoding().py
作用:获取系统默认编码方式
代码:
import sys
print(sys.getdefaultencoding())结果:utf-8
万一Python3.x中不能读取文件里面的中文怎么办?
解决:编写encoding=”UTF-8”
例如:
file = open("HELLO", encoding="UTF-8")版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/73304.html

