
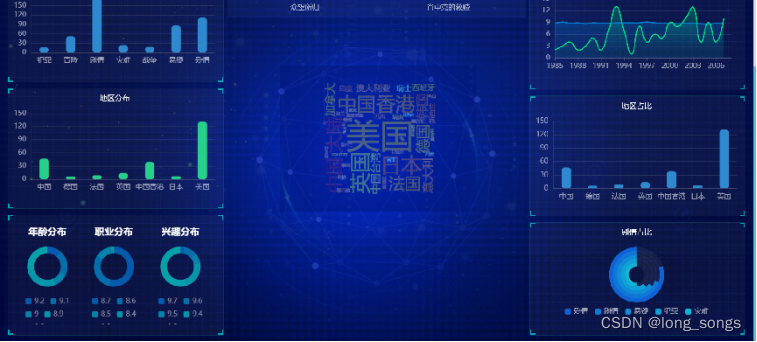
先看成品图
代码有点多放在我的github上
 https://github.com/longsongline/douban-bigdata-show
https://github.com/longsongline/douban-bigdata-show使用具体流程
1.先运行dashuju3.py
这个是用于爬取的豆瓣top250的代码,会生成一个csv文件
1.import requests
2.import bs4
3.import csv
4.
5.from lxml import etree
6.import requests
7.import time
8.import os
9.
10.import datetime
11.import time
12.#创建或者写入csv
13.csv_file=open('dashuju250.csv', 'w', newline='',encoding='utf-8')
14.writer = csv.writer(csv_file)
15.#列名添加
16.writer.writerow(['No', 'name', 'score', 'recommendation', 'yanyuan','daoyan','year','country','classes'])
17.#请求头越猛越好,反正这个豆瓣就是让你爬的,不用那么多也行
18.headers = {
19. 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36',
20. 'Cookie': 'lang=zh-cn; theme=default; ajax_lastNext=on; selfClose=1; bugModule=0; bugBranch=0; treeBranch=0; moduleBrowseParam=0; openApp=qa; windowWidth=659; windowHeight=706',
21. }
22.#因为有十个页面,所以目前采用分别爬取
23.for x in range(10):
24. #每一个的连接
25. url = 'https://movie.douban.com/top250?start=' + str(x*25) + '&filter='
26. res = requests.get(url, headers=headers)
27. #靓汤出马
28. bs = bs4.BeautifulSoup(res.text, 'html.parser')
29. bs = bs.find('ol', class_="grid_view")
30. #就打开f12找需要的东西的<li>在哪
31. for titles in bs.find_all('li'):
32. print(titles)
33. num = titles.find('em',class_="").text
34. title = titles.find('span', class_="title").text
35. comment = titles.find('span',class_="rating_num").text
36. others=titles.find('div',class_='bd').find('p').text.strip('').split('\n')
37.
38. if '\xa0\xa0\xa0' in others[1]:
39. actors_director=others[1].strip('').split('\xa0\xa0\xa0')
40. director=actors_director[0].strip(' ')
41. actors=actors_director[1]
42. else:
43. actors_director=others[1].strip('').split('\xa0\xa0\xa0')
44. director=actors_director[0].strip(' ')
45. actors=''
46.
47. year_country_type=others[2].strip('').split('\xa0/\xa0')
48. year=year_country_type[0].strip(' ')
49. country=year_country_type[1]
50. movie_type=year_country_type[2]
51. #对于可能存在的空数据,可以用if/else语句分情况讨论,这样就不会无法运行或者碰到数据不完整的情况了
52. if titles.find('span',class_="inq") != None:
53. tes = titles.find('span',class_="inq").text
54. writer.writerow([num , title , comment , tes , actors,director, year, country, movie_type])
55. else:
56. writer.writerow([num , title , comment , '', actors,director, year, country, movie_type])
57.#关上罪恶的文件
58.csv_file.close() 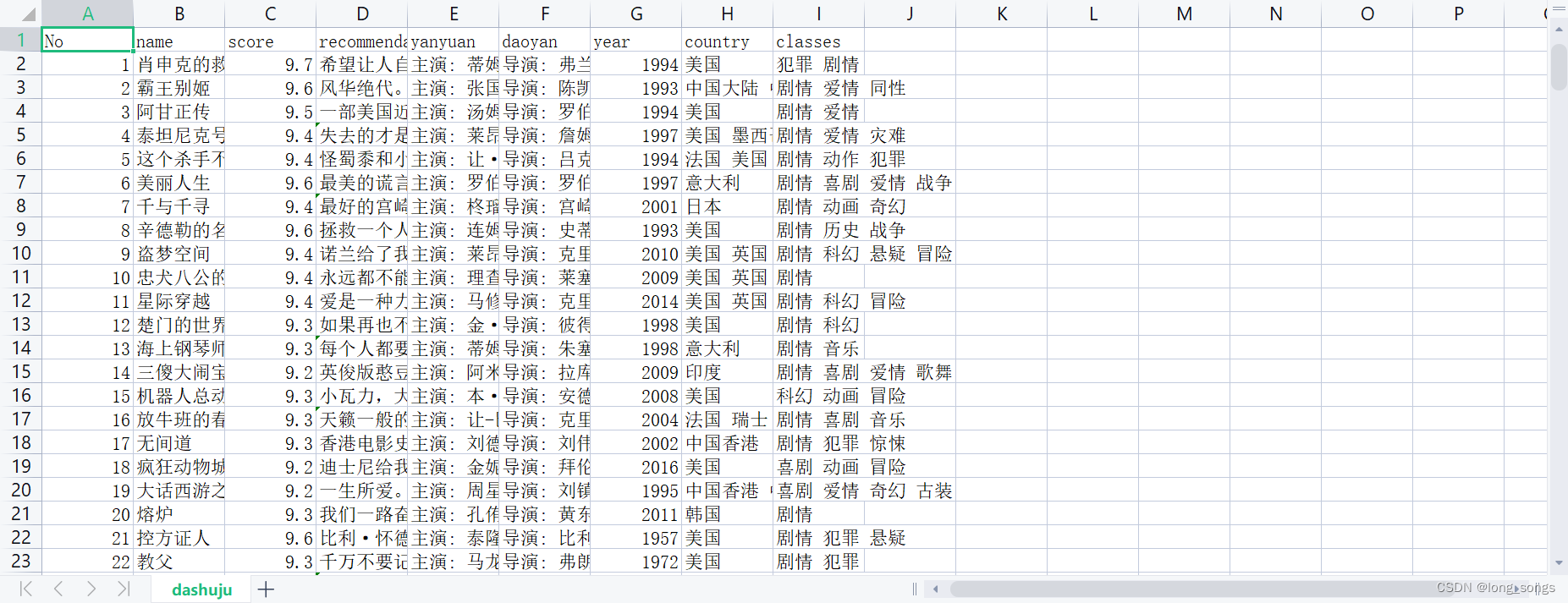
这个文件想直接获取的话就下载就行了
这样就可以省去这一步
2.运行ciyun.py
制作词云
这一步,如果也不想做,直接把图片偷走就好了

然后再换底运行
3.huandi.py
换成蓝色的底部,因为我的可视化的色调是蓝色的

4.布置准备好,替换好路径后,运行app.py 的flask,打开网址即可显示出你的高档可视化成果啦!

有什么问题可以留言或者私信我
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/73526.html

