
comment—models—letter.py
sendID = db.Column(db.String(64), comment='发送者名字')
sendID作为外键关联字段,为什么没有加外键关联关系relationship?
因为用户表中有很多字段,通过关联查询,会查询到很多字段,影响数据库的查询效率
什么时候用关联关系字段relationship?
关联关系不复杂(关联的模型类中字段很少)的情况下使用
一、模型类
from comment.models import db
from sqlalchemy import ForeignKey
from datetime import datetime
class Letter(db.Model):
'''
收发消息的模型类
'''
__tablename__ = 't_letter'
id = db.Column(db.BIGINT, primary_key=True, autoincrement=True)
#todo 外键,关联关系,如果用户有很多字段,会查到很多数据,会影响数据库的查询效率的
# 有2种方式,加关联关系字段和不加关联关系字段
# 什么时候用关联关系relationship?关联关系不复杂(关联的模型类中字段少)的情况下使用
sendID = db.Column(db.String(64), comment='发送者名字')
recID = db.Column(db.BIGINT, comment='接受者ID')
detail_id = db.Column(db.BIGINT, ForeignKey('t_letter_detail.id'), comment='消息详情主键')
#todo userList=False:表示是一对一关联关系
letter_detail = db.relationship('Letter_detail', backref=db.backref('letter', lazy=True))
state = db.Column(db.Integer, comment='持否已读(0未读;1已读)')
class Letter_detail(db.Model):
'''
站内信详情的模型类,和收发消息的模型类是一对多的关联关系
'''
__tablename__ = 't_letter_detail'
id = db.Column(db.BIGINT, primary_key=True, autoincrement=True)
title = db.Column(db.String(64), comment='消息标题')
detail = db.Column(db.String(256), comment='消息内容')
pDate = db.Column(db.DateTime, default=datetime.now(), comment='发送时间')
二、创建站内消息资源类
from flask_restful import Resource,reqparse
from flask import g,current_app
from comment.utils.decorators import login_required
from comment.models.user import User
from comment.models.letter import Letter,Letter_detail
from comment.models import db
from financial.resource.letter.serializer import LetterPaginateSerializer
class Letter_Res(Resource):
'''
发送消息的资源类
'''
#需要用户登录后才能操作
method_decorators = [login_required]
def post(self):
'''
发送消息
:return:
'''
rp=reqparse.RequestParser()
rp.add_argument('title',required=True)
rp.add_argument('group') #群发消息的时候,用户组,可以为空
rp.add_argument('rec_id') #单个用户发送信息的时候,接收用户id,可以为空
rp.add_argument('content',required=True)
args=rp.parse_args()
title=args.title
group=args.group
rec_id=args.rec_id
content=args.content
#todo 发送消息的用户id,当前用户 发送者
uid=g.user_id
user=User.query.filter(User.id==uid).first()
#todo 第一种:群发消息,group有3个值:2:代表全体用户,0:代表普通用户组,1:代表管理员
if group=='0' or group=='1': #根据用户角色查询所有的接收用户
rec_list=User.query.filter(User.role==int(group)).all()
if group=='2':#群发消息给所有用户
rec_list=User.query.all()
#todo 第二种:单个用户发送消息
if rec_id:
rec_user=User.query.filter(User.id==rec_id).first()
if rec_user:
rec_list=[rec_user]
#todo 把消息详对象插入到数据库中
new_letter_detail=Letter_detail(title=title,detail=content)
db.session.add(new_letter_detail)
db.session.flush() #todo commit:表示提交到数据库中,flush表示刷新到数据库的缓冲区(表中没有数据,但是有自增的id),为什么不用commit呢,做一次性提交
for rec_user in rec_list:
#todo 给每个用户发送消息
letter=Letter(sendID=user.username,recID=rec_user.id,detail_id=new_letter_detail.id,state=0)
db.session.add(letter)
db.session.commit()
return {'msg':'ok'}
def get(self):
'''
查询当前用户收到的信息列表(分页)
:return:
'''
uid = g.user_id #当前登录的用户id
user = User.query.filter(User.id == uid).first()
rp = RequestParser()
rp.add_argument('curPage', required=True) #todo 访问的页号,必填
rp.add_argument('perPage', required=True) # 每一页显示数据的条数 必填
args = rp.parse_args()
curPage = int(args.get('curPage'))
perPage = int(args.get('perPage'))
#todo letter_list:是Pagination类型。包含分页的数据,同时在items属性中包含消息列表数据
letter_list=Letter.query.filter(Letter.recID==uid).paginate(curPage,perPage,error_out=False)
#py对象先转化成字典
dict_data=LetterPaginateSerializer(letter_list).to_dict()
return {'msg':'ok','data':dict_data}
三、加载资源
from financial.resource.letter.letter_resource import *
#加载资源
letter_api.add_resource(Letter_Res,'/message',endpoint='message')
四、为了显示某页中的记录,要把all()换成Flask-SQLALchemy提供的paginate()方法
例如
rec_list=User.query.all()
将all()变为paginate(),rec_list会返回分页对象Pagination
rec_list=User.query.paginate()
参数定义:
page:查询的页数
per_page:每页的条数
max_per_page:每页最大条数,有值时,per_page受它影响
error_out=True/False:当值为True时,下列情况会报错,一般设置为False
1、当page为1时,找不到人户数据
2、page小于1,或者per_page为负数
3、page或per_page不是整数
该方法返回一个分页对象Pagination
Pagination对象有下列属性:
has_next:如果下一页存在,返回True
has_prev:如果上一页存在,返回True
items:当前页的数据列表
next_num:下一页的页码
page:当前页面
pages:总页数
per_page:每页的条数
prev_num:上一页的页码
query:用于创建此分页对象的无限查询对象
total:总条数
iter_pages(left_edge=2,left_current=2,right_current=5,right_edge=2),迭代分页中的页码,四个参数,分别控制了省略号左右俩侧各显示多少页码,在模板中可以这样渲染
由于letter_list:是Pagination类型。包含分页的数据,同时在items属性中包含消息列表数据
letter_list=Letter.query.filter(Letter.recID==uid).paginate(curPage,perPage,error_out=False)
首先需要将py对象先转化成字典类型的数据
我定义的serializers/py文件就是将分页数据进行序列化操作,得到字典格式的数据
comment——utils——serializers.py文件
class BasePaginateSerializer(object):
"""分页数据序列化基类"""
def __init__(self, paginate): #简化代码,可以满足对象的拷贝
self.pg = paginate
if not self.pg:
return paginate
self.has_next = self.pg.has_next # 是否还有下一页
self.has_prev = self.pg.has_prev # 是否还有前一页
self.next_num = self.pg.next_num # 下一页的页码
self.page = self.pg.page # 当前页的页码
self.pages = self.pg.pages # 匹配的元素在当前配置一共有多少页
self.total = self.pg.total # 匹配的元素总数
self.page_size = self.pg.per_size #一页最多显示多少条数据
def get_object(self, obj):
"""对象的内容,系列化的个性操作,子类重写"""
return {}
def paginateInfo(self):
"""分页信息,是否有上下页,页数,总页数等"""
return {
'has_next': self.has_next,
'has_prev': self.has_prev,
'next_num': self.next_num,
'page': self.page,
'pages': self.pages,
'total': self.total,
'page_size': self.page_size
}
def to_dict(self):
"""序列化分页数据"""
pg_info = self.paginateInfo()
paginate_data = []
for obj in self.pg.items:
paginate_data.append(self.get_object(obj))
return {
'paginateInfo': pg_info, #分页对象本身
'totalElements': pg_info['total'], #总记录数
'content': paginate_data #当前一页所需要展示的数据列表
}
class BaseSerializer(object):
'''
把python对象转化为字典
'''
def __init__(self, data):
self.data = data
def to_dict(self):
# 个性化的函数需要子类重写
return {}
class BaseListSerializer(object):
"""对象组序列化基类"""
def __init__(self, data):
self.data_list = data
# self.select_type_serializer()
def select_type_serializer(self):
if not self.data_list:
return None
if isinstance(self.data_list, list): # 列表解析
if len(self.data_list) == 0:
return None
else:
self.data_list = [dict(zip(result.keys(), result)) for result in self.data_list]
def to_dict(self):
"""个性化的系列化,子类重写 """
return {}
由于在items属性中包含消息列表数据
也需要将其数据类型转换为字典格式的数据,需要我们重写父类的方法
financial——resource——letter——serializer.py文件
from comment.utils.serializers import BasePaginateSerializer
class LetterPaginateSerializer(BasePaginateSerializer):
'''
继承父类,同时子类需要把消息列表数据进行序列化
'''
def get_object(self,obj):
return {
'id':obj.id,
'sendName':obj.sendID, #发送者
'detail_id':obj.detail_id, #信件详情id
'title':obj.letter_detail.title, #信件标题
'detail':obj.letter_detail.detail, #信件详细内容
'state':obj.state, #信件已读状态
'sendTime':obj.letter_detail.pDate.strftime("%Y-%m-%d,%H:%M:%S") #发送时间
五、测试
发送站内消息
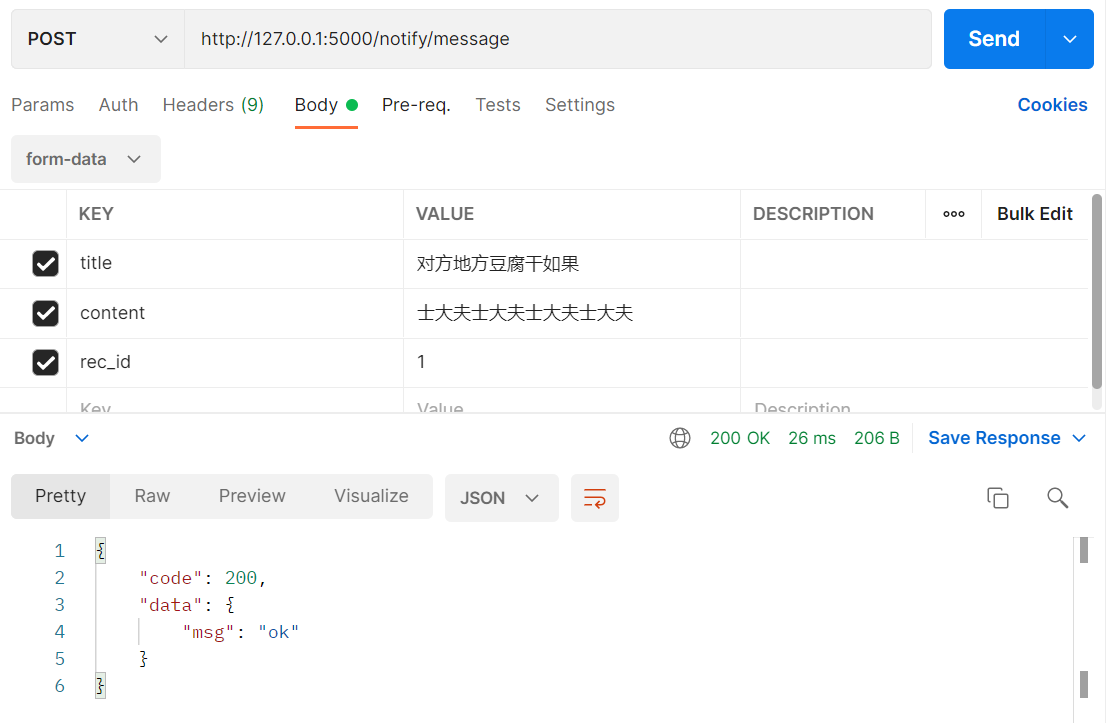
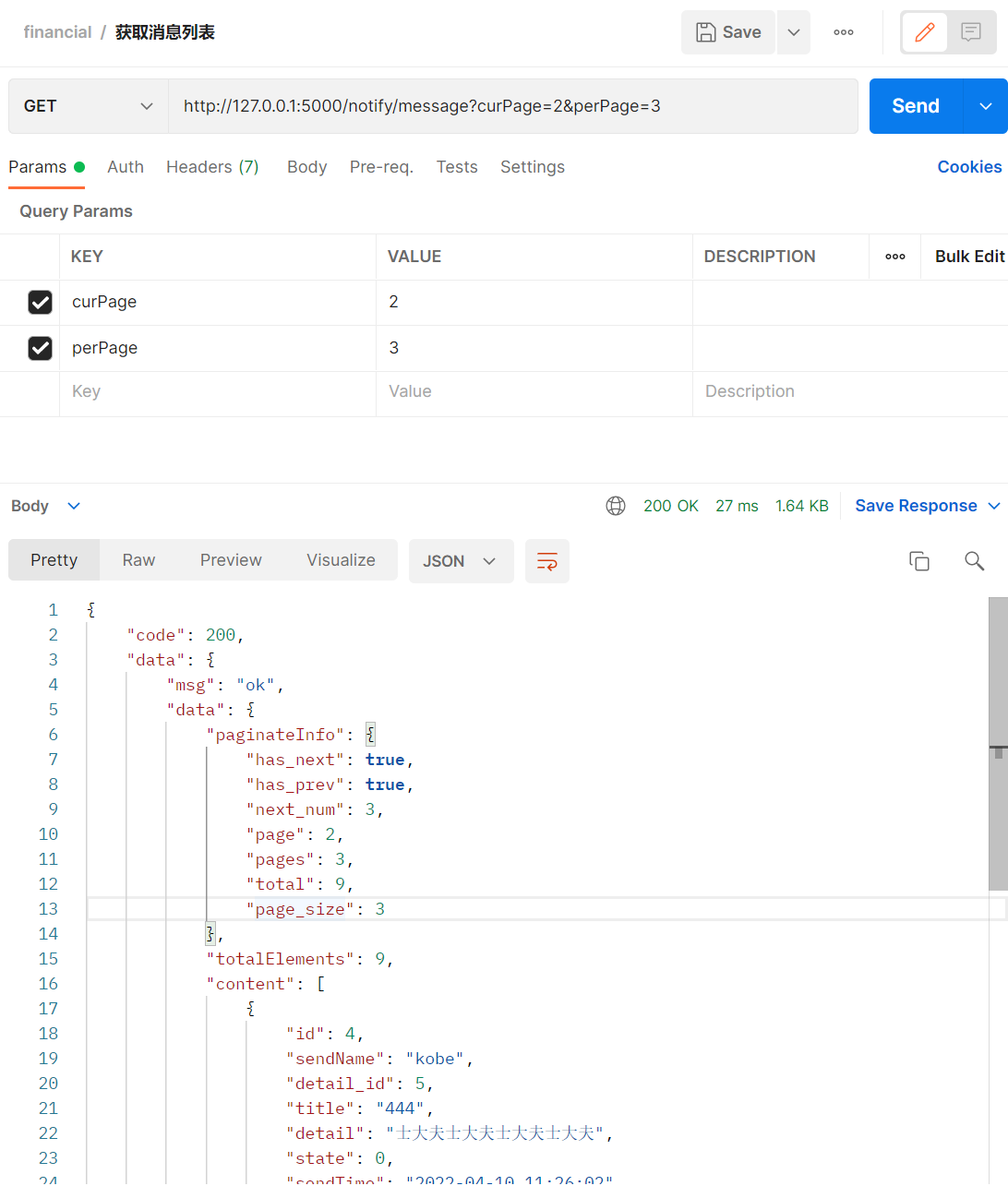
获取消息列表数据
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/74108.html

