
K-means聚类python实现的一个案例
K-means介绍
参考:周志华. 机器学习[M]. 北京: 清华大学出版社, 2021: 197-204.
待处理数据
数据来源:周志华. 机器学习[M]. 北京: 清华大学出版社, 2021: p202.表9.1
K-means聚类python实现
代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] # 用黑体显示中文
plt.rcParams['axes.unicode_minus']=False # 正常显示负号
file = r"./watermelon_dataset.xlsx"
df = pd.read_excel(file, sheet_name=0,engine="openpyxl") # 如果不加参数:engine="openpyxl",则会出现:XLRDError: Excel xlsx file; not supported错误
dataset = df.values[:,1:3] # 样本集数据
cluster_num = 3 # 簇数
# 从样本集中随机选取簇数个样本,作为初始均值向量
mean_vectors = np.zeros([2,3])
np.random.seed(10)
random_num = np.random.randint(0,29,(3,1))
for i in range(3):
mean_vectors[:,i] = dataset[random_num[i]]
iter = 0
while True:
# 依次计算样本数据中的所有数据与每一个均指向量的Minkowski距离
cluster_label = np.zeros(len(dataset))
for i in range(len(dataset)): # 虚幻遍历样本数据集
min_label = 0;
min_dis = np.inf
for j in range(cluster_num): # 遍历均值向量
d = np.linalg.norm(x=dataset[i] - mean_vectors[:,j], ord=2)**0.5 # 计算样本数据与均指向量的距离
if min_dis > d:
min_label = j
min_dis = d
cluster_label[i] = min_label
# 根据最新聚类簇计算每一个簇新的均值向量
new_mean_vectors = mean_vectors.copy()
stop = True
for i in range(cluster_num):
new_mean_vectors[:,i] = (np.sum(dataset[cluster_label==i], axis=0)/len(dataset[cluster_label==i])).T
if (new_mean_vectors[:, i] != mean_vectors[:, i]).any():
mean_vectors[:, i] = new_mean_vectors[:, i]
stop = False
#print(mean_vectors)
iter += 1
if stop:
break
figure, ax = plt.subplots(nrows=1, ncols=1, dpi=100)
ax.set(frame_on=True, xlim=[0, 1], ylim=[0, 0.5], xlabel="密度", ylabel="含糖率")
ax.grid(True)
ax.set_aspect(True)
markers = ["p", "*", "o"]
for i in range(cluster_num):
cluster_i = dataset[cluster_label == i]
ax.scatter(x=cluster_i[:,0], y=cluster_i[:,1], marker=markers[i])
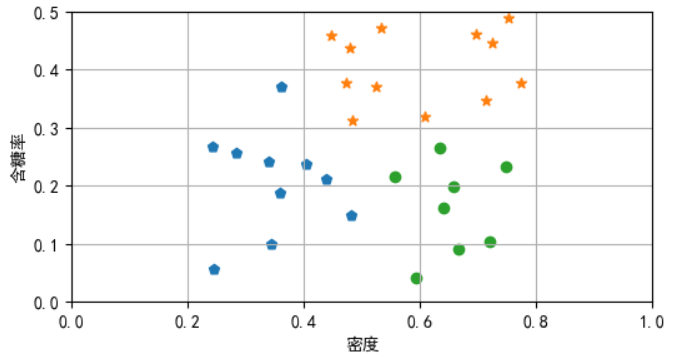
结果
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/74513.html

