
目录
分块传输
我们可以发现,运输层在传输数据的时候,并不是把整个数据包加个首部直接发送过去,而是会拆分成多个报文分开发送;那他这样做原因是什么?
有读者可能会想到:数据链路层限制了数据长度只能有1460。那数据链路层为什么要这么限制?他的本质原因就是:网络是不稳定的。如果报文太长,那么极有可能在传输一般的时候突然中断了,这个时候就要整个数据重传,效率就降低了。把数据拆分成多个数据报,那么当某个数据报丢失,只需要重传该数据报即可。
那是不是拆分得越细越好?报文中数据字段长度太低,会使得首部的占比太大,这样首部就会成为网络传输最大的负担了。例如1000字节,每个报文首部是40字节,如果拆分成10个报文,那么只需要传输400字节的首部;而如果拆分成1000个,那么需要传输40000字节的首部,效率就极大地降低了。
路由转换
先看下图:
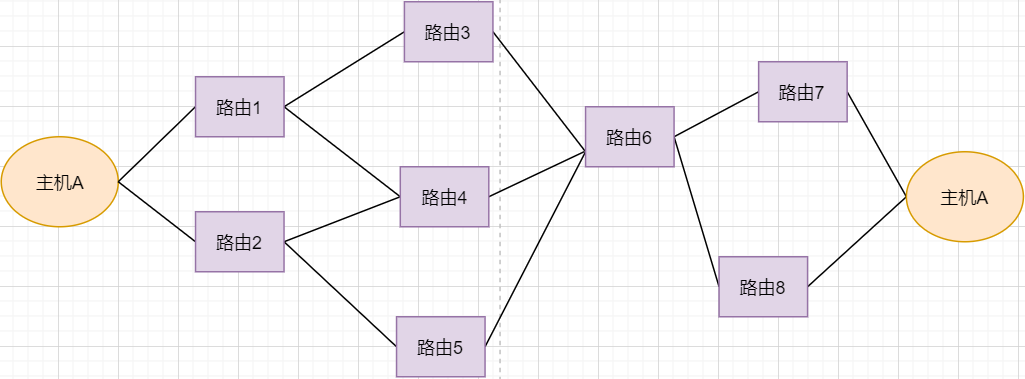
-
正常情况下,主机A的数据包可以又 1-3-6-7路径进行传送
-
如果路由3坏掉了,那么可以从 1-4-6-7进行传送
-
如果4也坏掉了,那么只能从2-5-6-7传送
-
如果5坏掉了,那么就中断线路了
可以看出来,使用路由转发的好处是:提高网络的容错率,本质原因依旧是网络是不稳定的 。即使坏掉几个路由器,网络依旧畅通。但是如果坏掉路由器6那就直接导致主机A和主机B无法通信,所以要避免这种核心路由器的存在。
使用路由的好处还有:分流。如果一条线路太拥堵,可以从别的路线进行传输,提高效率。
粘包与拆包
在面向字节流那一小节讲过,TCP不懂这些数据流的意义,他只知道从应用层拿到数据流,切割成一份份报文,然后发送给目标对象。而如果应用层传输下来的是两个数据包,那么极有可能出现这种情况:
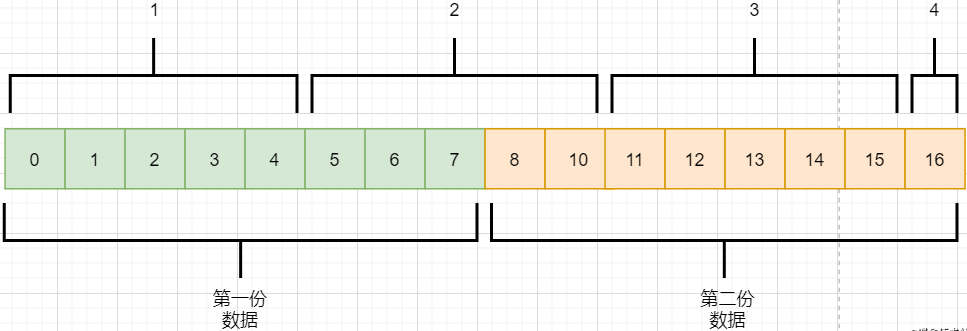
-
应用层需要向目标进程发送两份数据,一份音频,一份文本
-
TCP只知道接收到一个流,并把流拆分成4段进行发送
-
中间第二个报文的数据就出现两个文件的数据混在一起,这就是粘包
-
目标进程应用层在接收到数据之后,需要把这些数据拆分成正确的两个文件,就是拆包
粘包与拆包都是应用层需要解决的问题,可以在每个文件的最后附加上一些特殊的字节,如换行符;或者控制每个报文只包含一个文件的数据,不足的用0补充等等。
恶意攻击
TCP的面向连接特点可能会被恶意的人利用,对服务器进行攻击。
当我们向一个主机发送syn包请求创建连接时,服务器会为我们创建缓冲区等,然后向我们返回syn+ack报文;如果我们伪造IP和端口,向一个服务器进行海量的请求,会使得服务器创建了大量的创建一半的TCP连接,使得其无法正常响应用户的请求,导致服务器瘫痪。
解决的方法可以有限制IP的创建连接数、让创建一半的tcp连接在更短的时间内自行关闭、延缓接收缓冲区内存的分配等等。
长连接
我们向服务器的每一次请求都需要创建一个TCP连接,服务器返回数据之后就会关闭连接;如果在短时间内有大量的请求,那么频繁创建TCP连接关闭TCP连接是一个很浪费资源的行为。所以我们可以让TCP连接不要关闭,在这个期间进行请求,提高效率。
需要注意长连接维持时间、创建条件等,避免被恶意利用创建大量的长连接,消耗殆尽服务器的资源。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/74656.html

