
文章目录
一、ELK+Filebeat+kafka+zookeeper架构
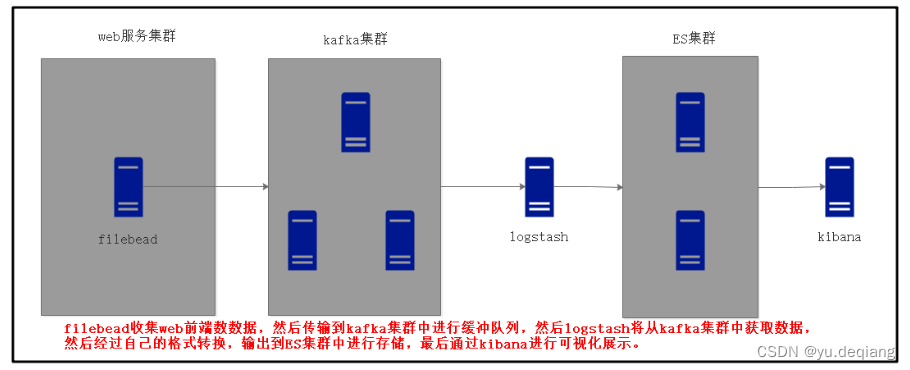
架构图分别演示
第一层:数据采集层
- 数据采集层位于最左边的业务服务集群上,在每个业务服务器上面安装了filebead做日志收集,然后把采集到的原始日志发送到kafka+zookeeper集群上。
第二层:消息队列层
- 原始日志发送到kafka+zookeeper集群上后,会进行集中存储,此时filebead是消息的生产者,存储的消息可以随时被消费。
第三层:数据分析层
- logstash作为消费者,回去kafka+zookeeper集群节点时实拉去原始日志,然后将获取到的原始日志根据规则进行分析、格式化处理,最后将格式化的日志转发至Elasticsearch集群中。
第四层:数据持久化存储
- Elasticsearch集群接收到logstash发送过来的数据后,执行写入磁盘,建立索引等操作,最后将结构化数据存储到Elasticsearch集群上。
第五层:数据查询,展示层
- kibana是一个可视化的数据展示平台,当有数据检索请求时,它从Elasticsearch集群上读取数据,然后进行可视化出图和多维度分析.
二、搭建ELFK+zookeeper+kafka
| 主机名 | ip地址 | 所属集群 | 安装软件包 |
|---|---|---|---|
| filebead | 20.0.0.55 | 数据层级层 | filebead+apache |
| kafka1 | 20.0.0.56 | kafka+zookeeper集群 | kafka+zookeeper |
| kafka2 | 20.0.0.57 | kafka+zookeeper集群 | kafka+zookeeper |
| kafka3 | 20.0.0.58 | kafka+zookeeper集群 | kafka+zookeeper |
| logstash | 20.0.0.59 | 数据处理层 | logstash |
| node1 | 20.0.0.60 | ES集群 | Eslasticsearch+node+phantomis+head |
| node2 | 20.0.0.61 | ES集群+kibana展示 | Elasticsearch+node+phantomis+head+kibana |
1、安装kafka+zookeeper集群(20.0.0.55、20.0.0.56、20.0.0.57)
2、安装zookeeper服务
关闭防火墙,核心防护,修改主机名

安装环境,解压软件
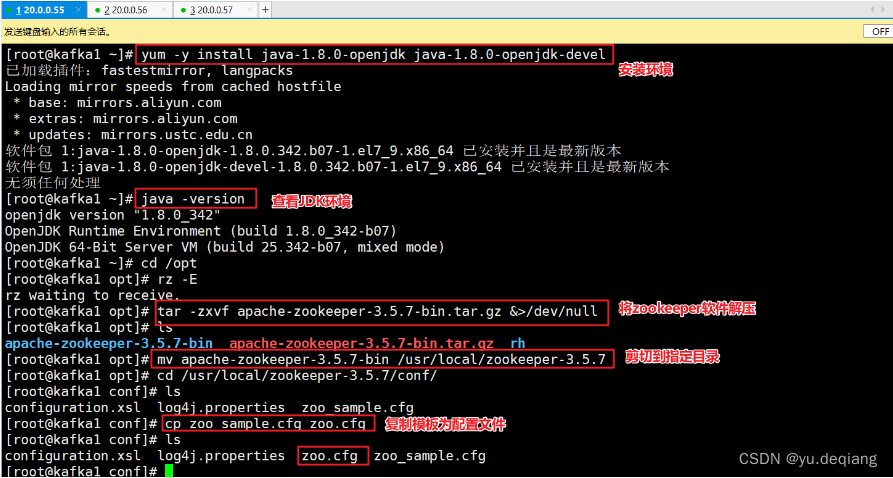
修改配置文件
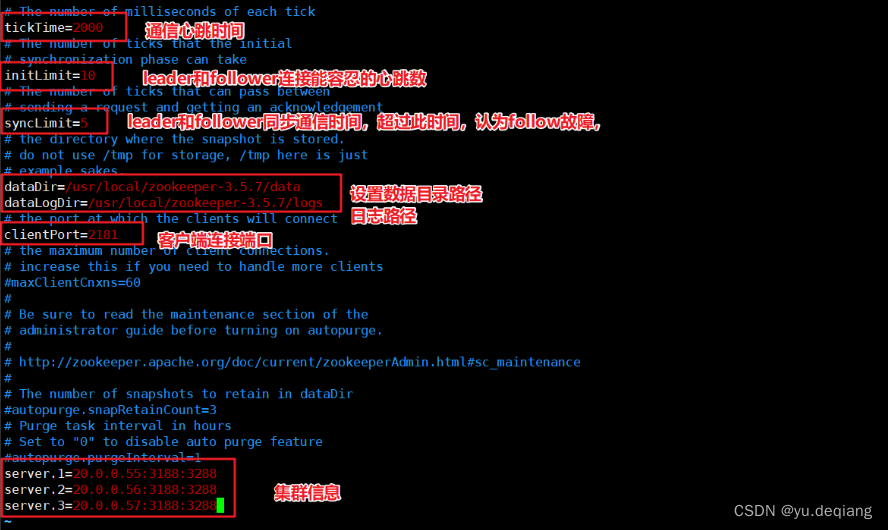
创建数据目录、日志目录

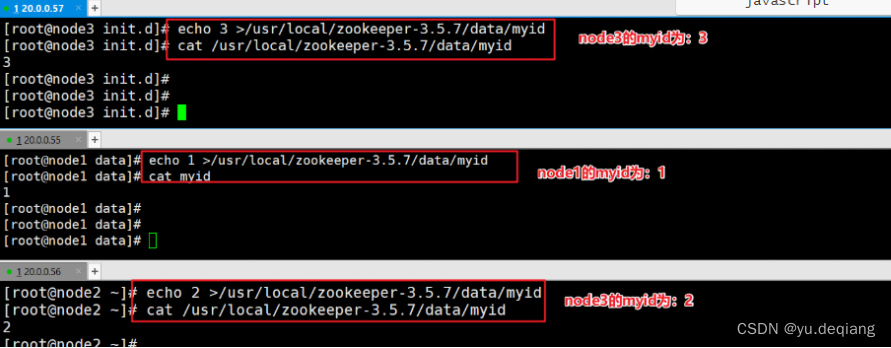
设置三台机器的myid
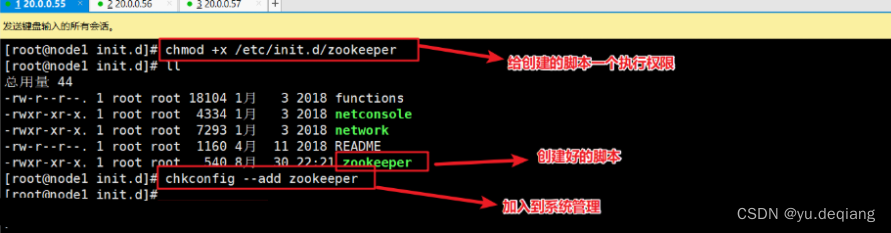
设置三台机器的执行脚本
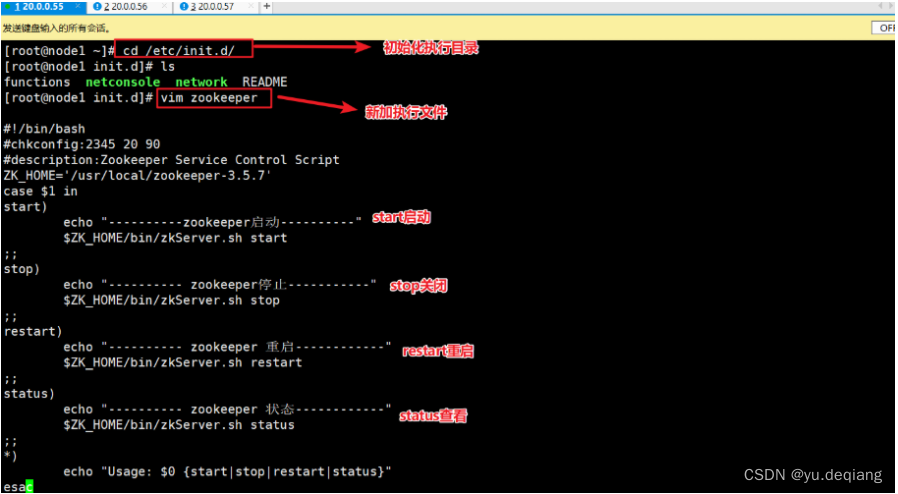
将三台机器的启动脚本放入到系统管理中
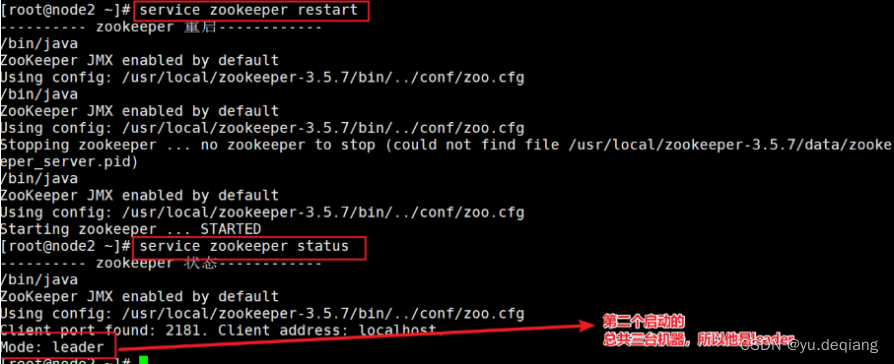
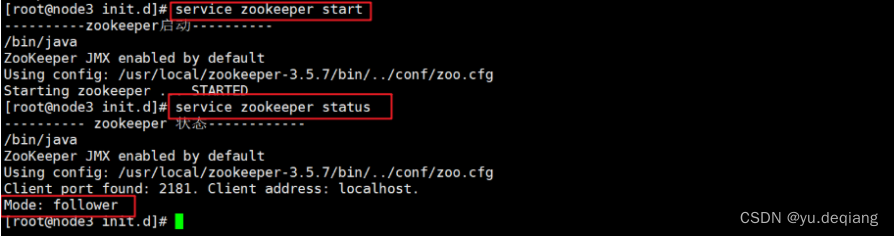
分别启动三台启动的zookeeper

3、安装kafka服务
将三台机器都上传安装包,并解压到指定目录

备份配置文件
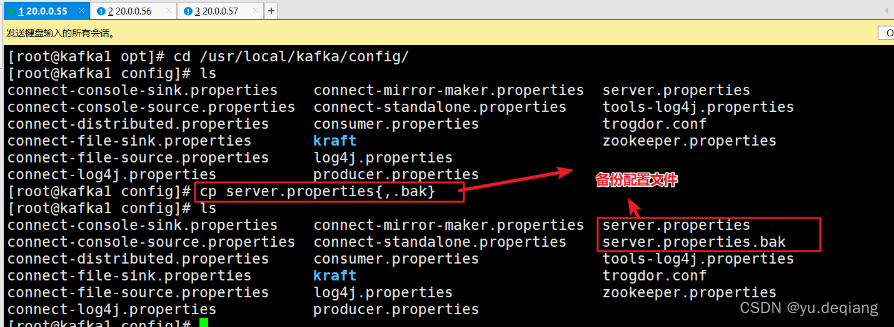
修改配置文件
- 20.0.0.55主机的配置文件

-
20.0.0.56的配置文件
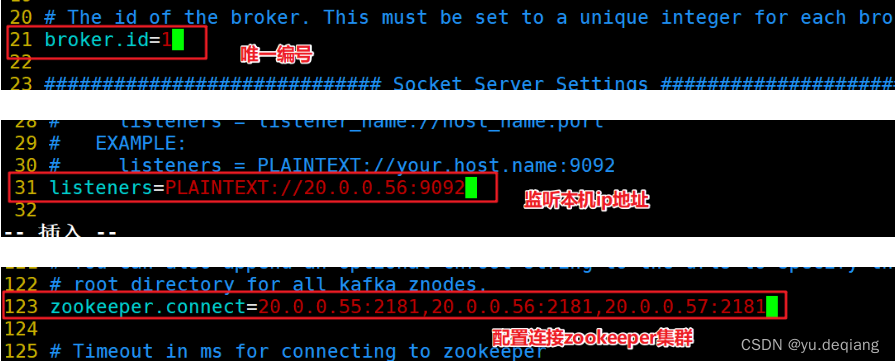

-
20.0.0.57配置文件
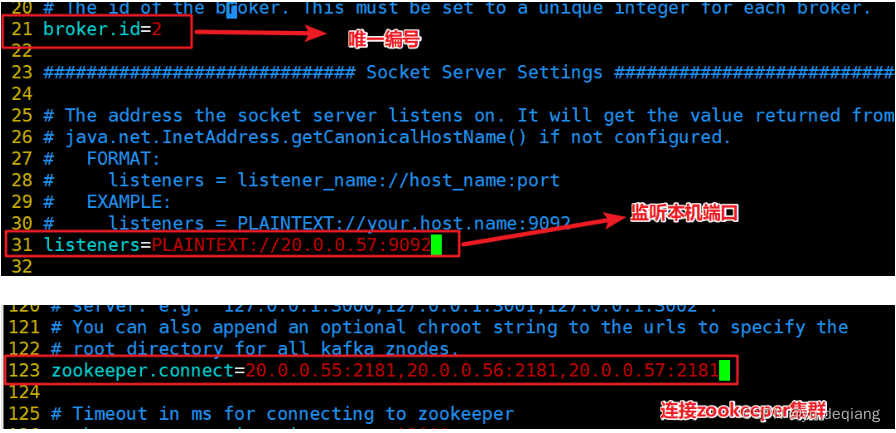
将kafka添加到环境变量中
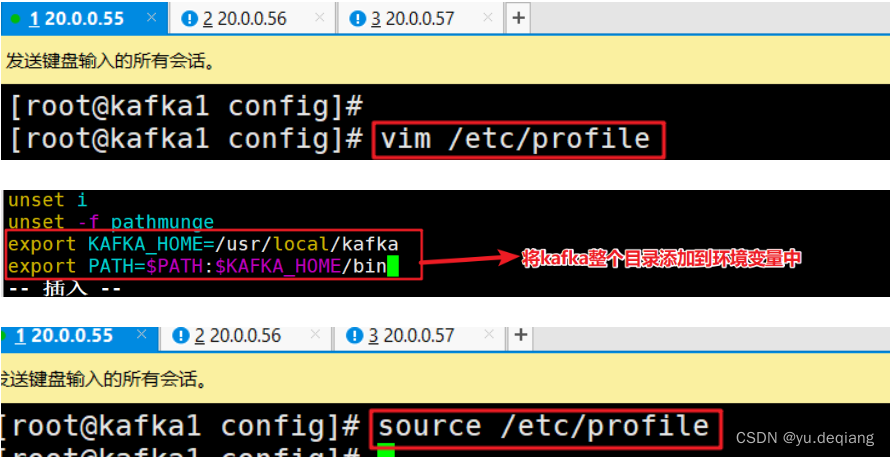
配置kafka 的启动脚本
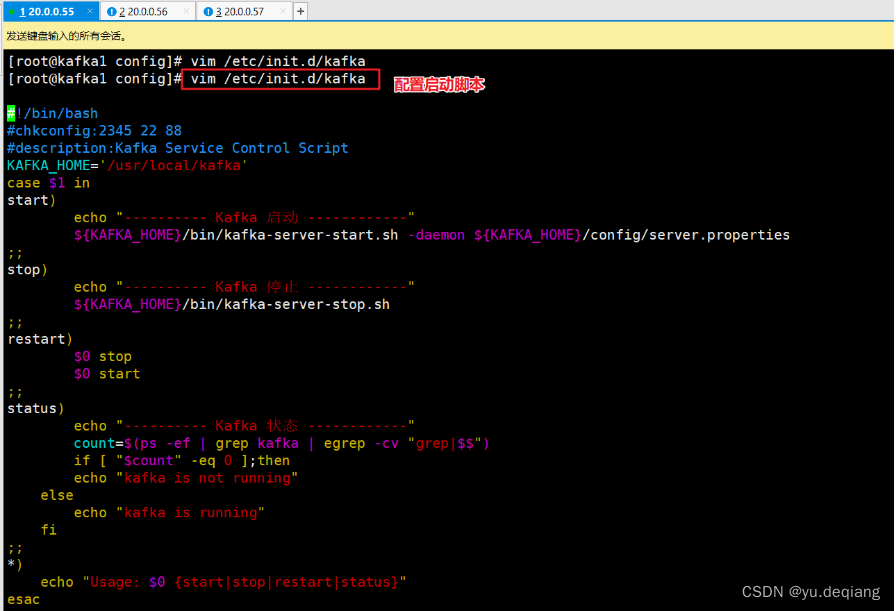
设置开机自动

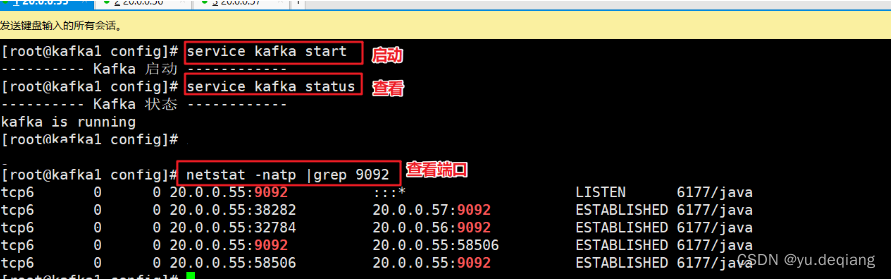
分别启动kafka
3.1 kafka命令行操作
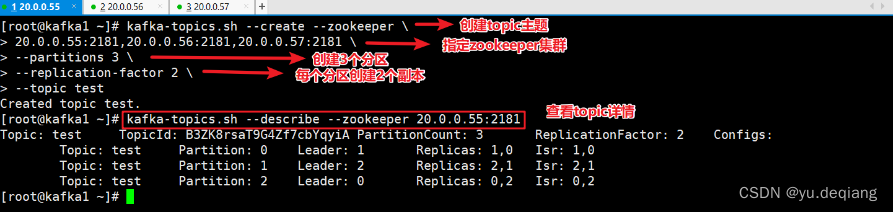
创建topic
kafka-topics.sh --create --zookeeper 20.0.0.55:2181,20.0.0.56:2181,20.0.0.57:2181 --replication-factor 2 --partitions 3 --topic test
#--zookeeper:定义zookeeper集群服务器地址,如果有多个ip以逗号分隔。
#--replication-factor:定义分区副本,1代表但副本,建议为2
#--partitions: 定义分区数
#--topic :定义topic名称
查看当前服务器中的所有topic
kafka-topics.sh --list --zookeeper 20.0.0.55:2181,20.0.0.56:2181,20.0.0.57:2181
查看某个topic的详情
kafka-topics.sh --describe --zookeeper 20.0.0.55:2181,20.0.0.56:2181,20.0.0.57:2181
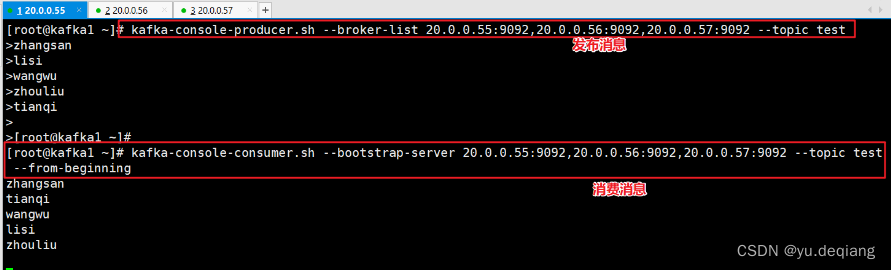
发布消息
kafka-console-producer.sh --broker-list 20.0.0.55:9092,20.0.0.56:9092,20.0.0.57:9092 --topic test
消费消息
kafka-console-consumer.sh --bootstrap-server 20.0.0.55:9092,20.0.0.56:9092,20.0.0.57:9092 --topic test --from-beginning
#--from-beginning:会把主题中以往所有的数据都读取出来
修改分区数
kafka-topics.sh --zookeeper 20.0.0.55:2181,20.0.0.56:2181,20.0.0.57:2181 --alter --topic test --partitions 6
删除topic
kafka-topics.sh --delete --zookeeper 20.0.0.55:2181,20.0.0.56:2181,20.0.0.57:2181 --topic test
3.2 创建topic进行测试(任意主机上均可操作)
创建topic
发布消息、消费消息
3、配置数据采集层filebead(20.0.0.58)
关闭防火墙、修改主机名
安装httpd服务,并启动
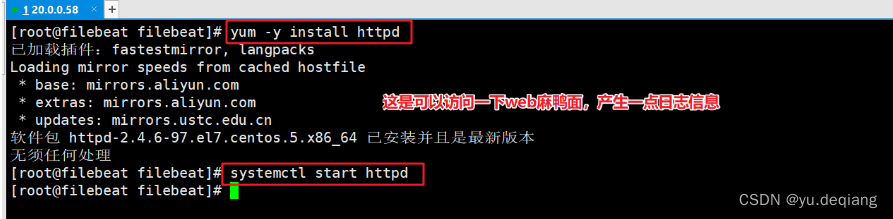
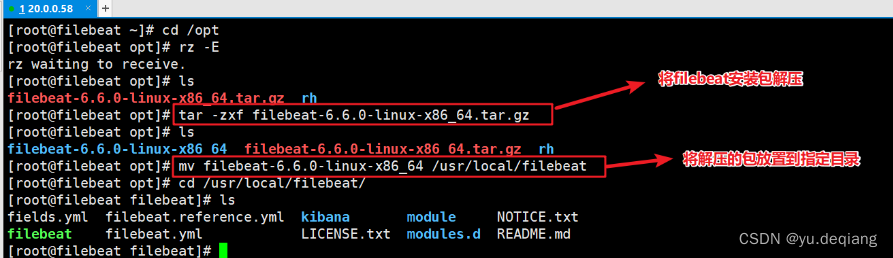
安装filebead,并剪切到指定目录
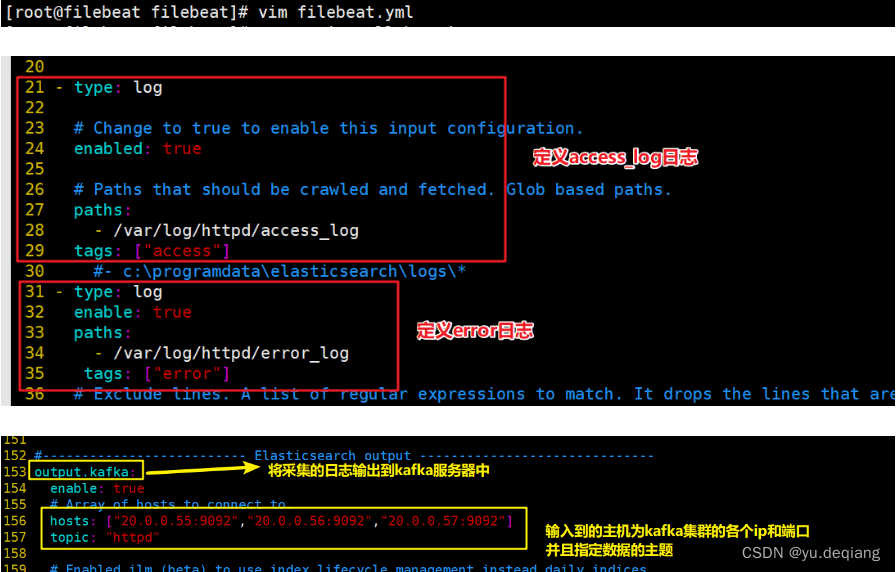
修改配置文件
启动filebeat服务

4、部署ES服务(20.0.0.60、20.0.0.61)
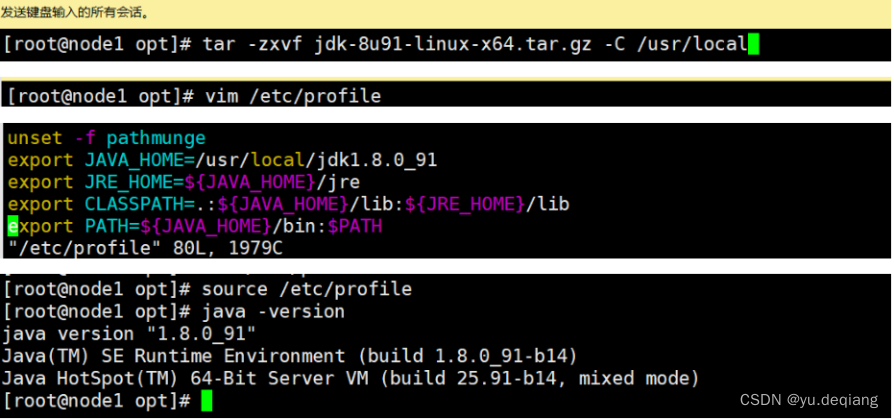
安装JDK
4.1 安装ES服务
配置本地解析,上传安装包安装并启动
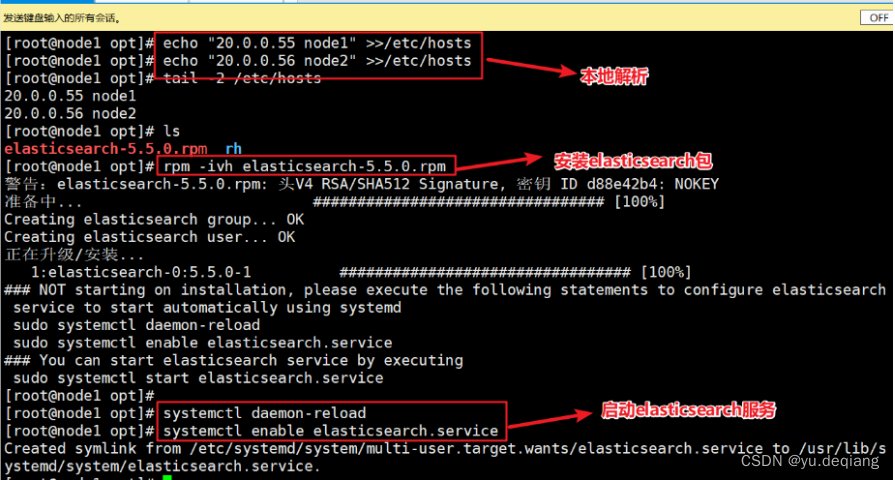
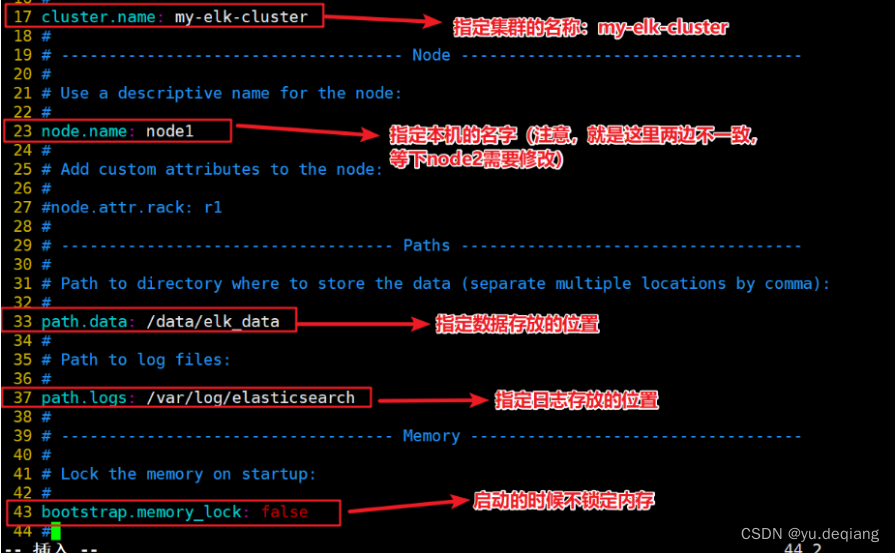
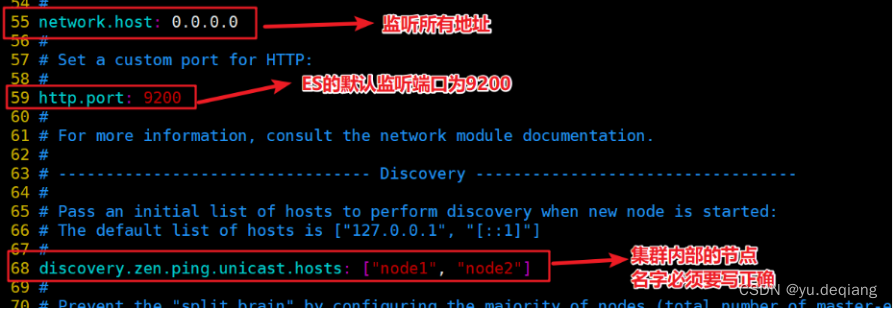
修改配置文件

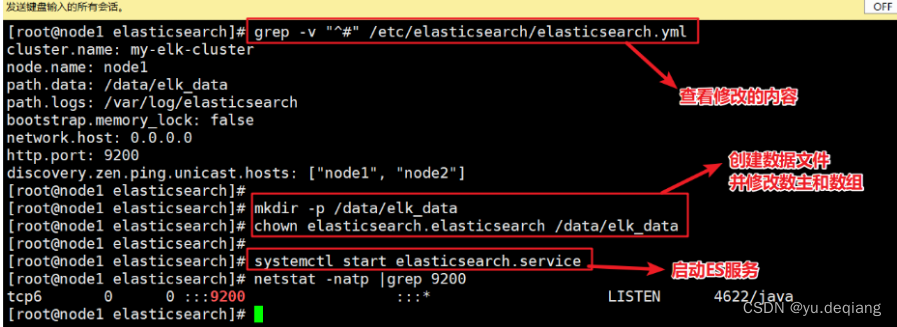
查看配置文件,创建数据目录
4.2 安装node插件
安装运行环境
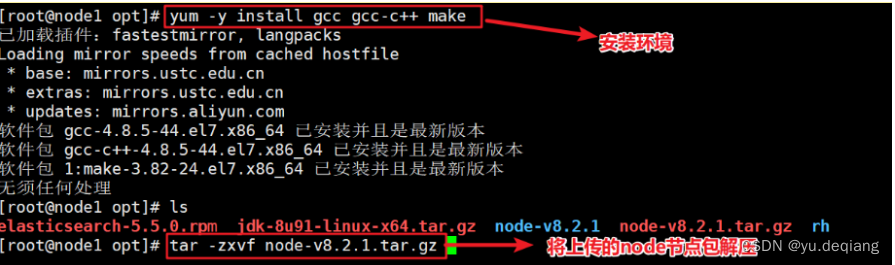
编译

安装

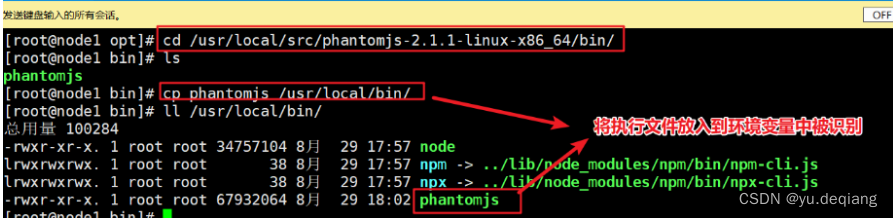
4.3 安装phantomjs插件
上传压缩包解压

将执行文件加入到环境变量
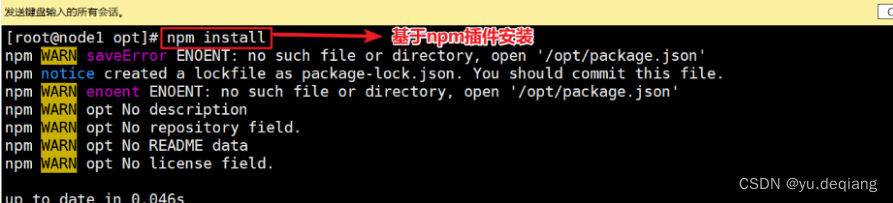
4.4 安装ES-head
上传压缩包,解压

安装
4.5 修改ES配置文件

4.6 启动ES服务

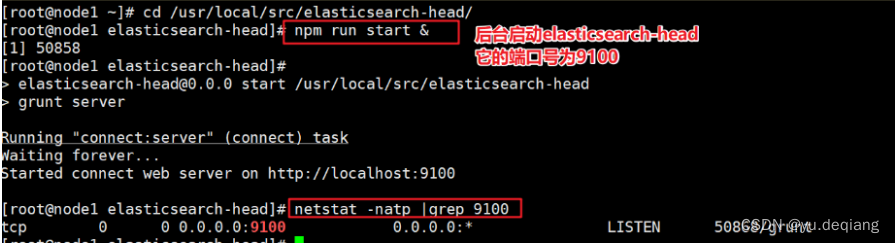
4.7 启动ES-head服务
5、部署logstash(20.0.0.59)
安装java环境

安装logstash
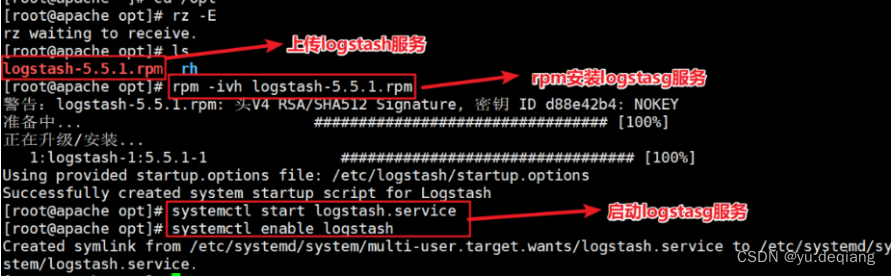
创建软链接

创建执行对接文件
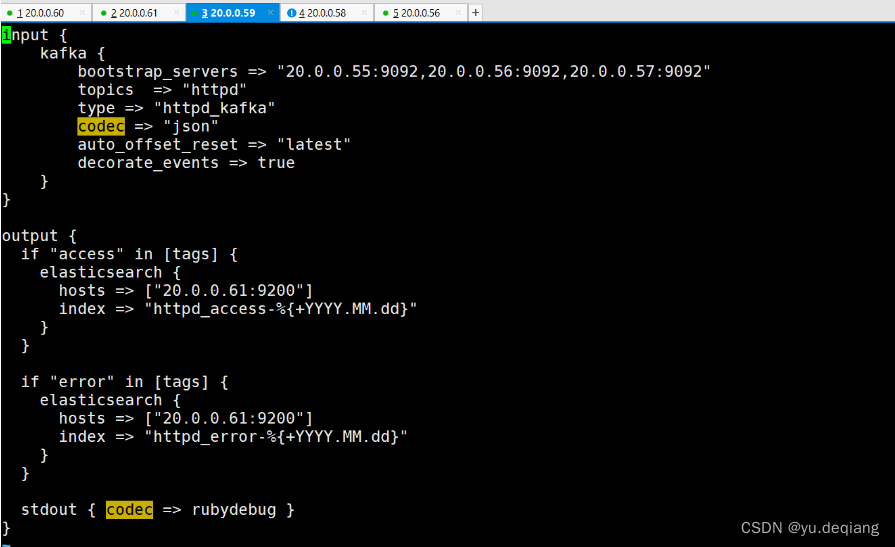
启动服务

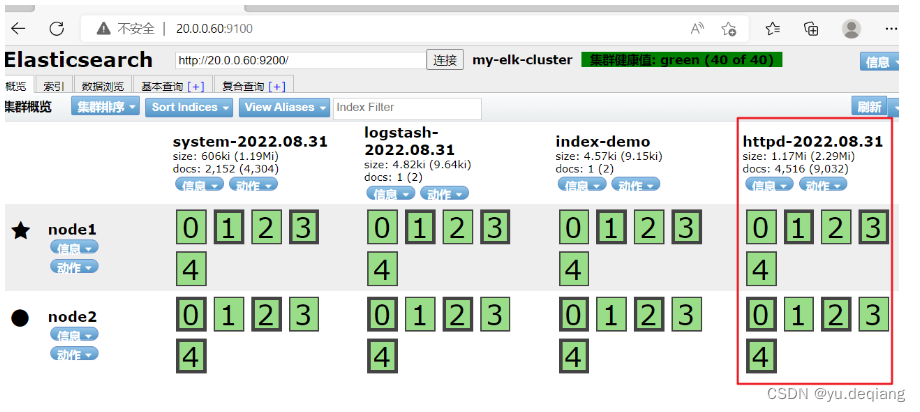
6、使用ES-head接口访问
7、安装kibana指向可视化
这边不演示了,参考前面的博客
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/75009.html

