
MyISAM
MyISAM用的是非聚集索引方式,即数据和索引落在不同的两个文件上(MYD是数据文件 , MYI是索引文件)。
MyISAM在建表时以主键作为KEY来建立主索引B+树,树的叶子节点存的是对应数据的物理地址。我们拿到这个物理地址后,就可以到MyISAM数据文件中直接定位到具体的数据记录了。
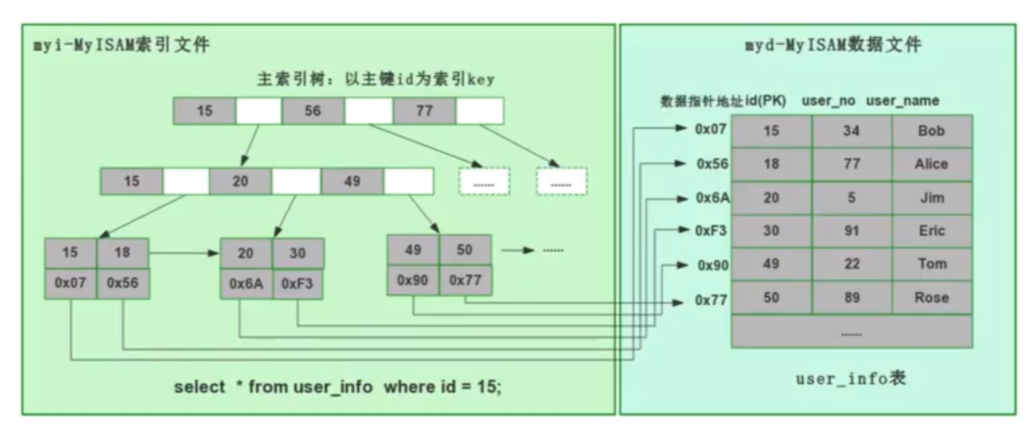
当我们为某个字段添加索引时,我们同样会生成对应字段的索引树,该字段的索引树的叶子节点同样是记录了对应数据的物理地址,然后也是拿着这个物理地址去数据文件里定位到具体的数据记录。
InnoDB
InnoDB使用的索引的数据结构是B+树,数据库表定义中的每一个索引对应一颗B+树,默认的聚簇索引也是一颗B+树,B+树有以下特征:
所有节点关键字是按递增次序排列,并遵循左小右大原则;
- 非叶节点的子节点数在1到M之间(下图中M为3),空树除外;
- 非叶节点的索引数目大于等于ceil(M/2)个且小于等于M个;
- 所有叶子节点均在同一层,叶子节点之间有从左到右的指针;
- 数据存储在叶子节点,非叶子节点只存储索引;

如果没有使用select * 的话,字段已经添加索引,可以直接在辅助索引树查找到,所以走覆盖索引查询效率更高。
B+树索引数据结构有以下列出的几种优势:
- 查询性能稳定,查询一条数据需要的IO次数往往是树的高度次;
- 范围查询效率高,安装索引范围查询时,可以先查找的第一个满足要求的数据,然后向后遍历,直到第一个不满足条件的数据为止,中间的数据都符合要求;
- 查询效率高,往往一次数据查询只需要2~3次磁盘IO;
- 叶子节点存储所有数据,不需要去B+树之外找数据;
InnoDB采用B+树的原因
在InnoDB引擎中,我们为数据库创建的索引都是以B+树的形式存在,为什么InnoDB不采用哈希索引或者B树索引呢?主要是基于以下原因:
数据库查询经常会出现非等值查询,哈希索引在这种情况下无法工作;
相比于B树,B+树索引非叶子节点不存放数据,从而磁盘一次IO可以读取更多的索引数据,有效减少磁盘IO次数;
数据库查询经常会出现范围查询,B+树底层的叶子节点之间按照顺序排列,可以更有效的实现范围查询;
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/75487.html

