
学习目标
-
Zookeeper分布式锁原理分析
-
Zookeeper用作Leader选举的原理分析
第1章 分布式锁简介
1.1 理解分布式锁
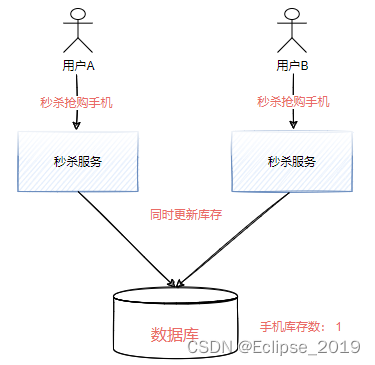
我们先来看一个问题,如下图所示,两个用户同时去抢购秒杀商品,当秒杀服务同时收到秒杀请求时,都去进行库存扣减,此时在没有做任何处理的情况下,就会导致库存数量变成负数从而导致超卖现象。
这种情况下我们一般会选择加锁的方式来避免并发的问题。但是在分布式场景中,采用传统的锁并不能解决跨进程并发的问题,所以需要引入一个分布式锁,来解决多个节点之间的访问控制。
1.2 如何解决分布式锁
我们可以基于Zookeeper的两种特性来实现分布式锁:
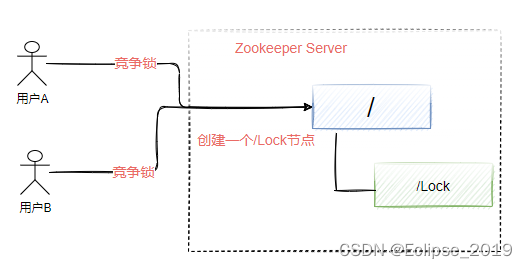
1、使用唯一节点特性实现分布式锁
就是基于唯一节点特性,如下图所示。多个应用程序去抢占锁资源时,只需要在指定节点上创建一个 /Lock 节点,由于Zookeeper中节点的唯一性特性,使得只会有一个用户成功创建 /Lock 节点,剩下没有创建成功的用户表示竞争锁失败。
这种方法能达到目的,但是会有一个问题,如下图所示,假设有非常多的节点需要等待获得锁,那么等待的方式自然是使用Watcher机制来监听/lock节点的删除事件,一旦发现该节点被删除说明之前获得锁的节点已经释放了锁,此时剩下的B、C、D。节点同时会收到删除事件从而去竞争锁,这个过程会产生惊群效应。
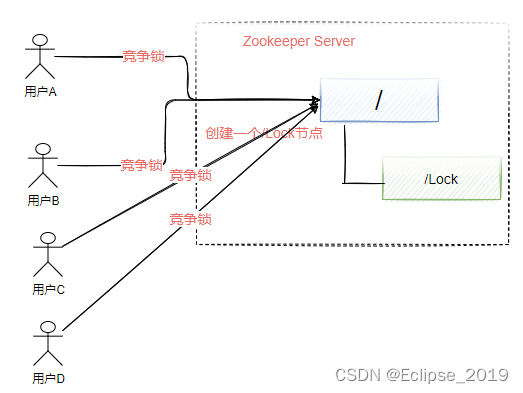
“惊群效应”,简单来说就是如果存在许多的客户端在等待获取锁,当成功获取到锁的进程释放该节点后,所有处于等待状态的客户端都会被唤醒,这个时候zookeeper在短时间内发送大量子节点变更事件给所有待获取锁的客户端,然后实际情况是只会有一个客户端获得锁。如果在集群规模比较大的情况下,会对zookeeper服务器的性能产生比较大的影响。
2、使用有序节点实现分布式锁
因此为了解决这个问题,我们可以采用Zookeeper的有序节点特性来实现分布式锁。
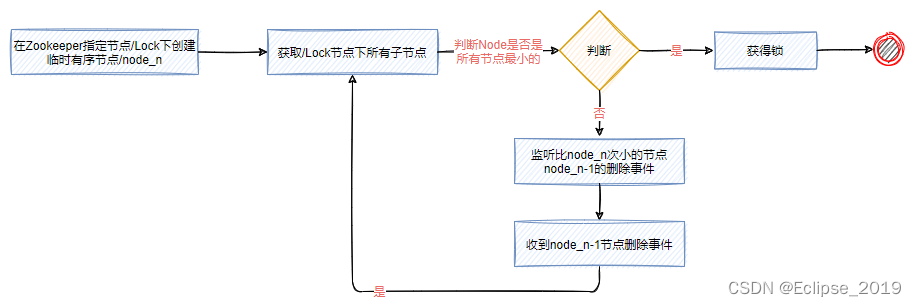
如下图所示,每个客户端都往指定的节点下注册一个临时有序节点,越早创建的节点,节点的顺序编号就越小,那么我们可以判断子节点中最小的节点设置为获得锁。如果自己的节点不是所有子节点中最小的,意味着还没有获得锁。这个的实现和前面单节点实现的差异性在于,每个节点只需要监听比自己小的节点,当比自己小的节点删除以后,客户端会收到watcher事件,此时再次判断自己的节点是不是所有子节点中最小的,如果是则获得锁,否则就不断重复这个过程,这样就不会导致羊群效应,因为每个客户端只需要监控一个节点。
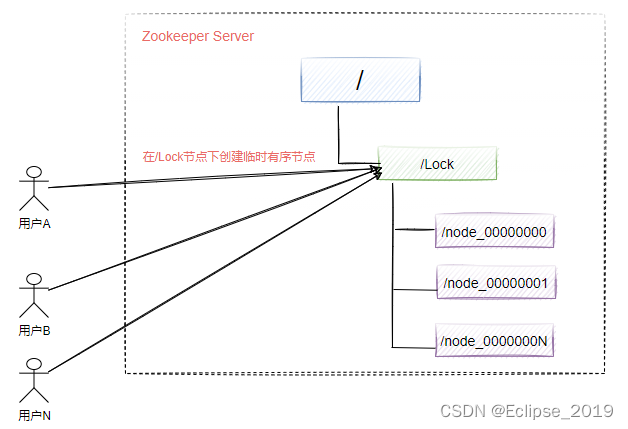
如下图所示,表示有序节点实现分布式锁的流程。
第2章 分布式锁实现
在本文中我们使用Curator来实现分布式锁。为了实现分布式锁,我们先演示一个存在并发异常的场景。
2.1 场景模拟
项目见zk-demo中的scene包下面
1、sql脚本
DROP TABLE IF EXISTS `goods_stock`;
CREATE TABLE `goods_stock` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`goods_no` int NOT NULL COMMENT '商品编号',
`stock` int DEFAULT NULL COMMENT '库存',
`isActive` smallint DEFAULT NULL COMMENT '是否上架(1上,0不是)',
PRIMARY KEY (`id`)
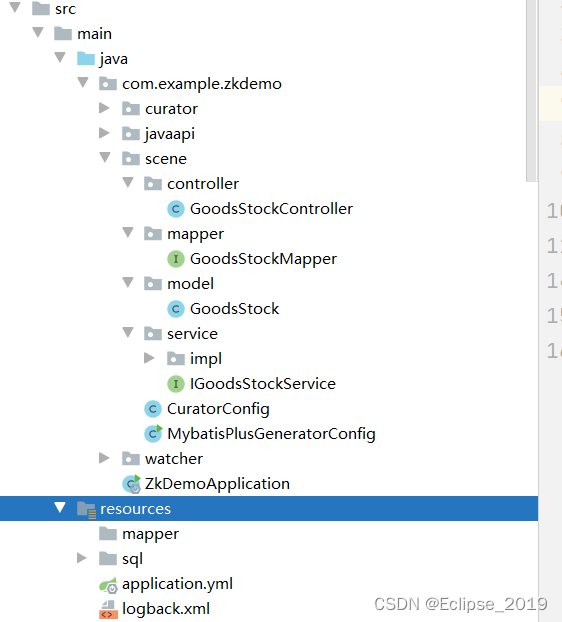
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;2、采用mybatis-plus搭建项目,项目结构如图所示
3、POM文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>zk-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>zk-demo</name>
<description>zookeeper应用</description>
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spring-boot.version>2.3.2.RELEASE</spring-boot.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.13</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.0.1</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.0.1</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.2</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.4.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.9</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<dependency>
<groupId>org.freemarker</groupId>
<artifactId>freemarker</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
</project>4、配置文件
server:
port: 8080
servlet:
context-path: /
spring:
application:
name: zk-demo
datasource:
druid:
url: jdbc:mysql://192.168.8.74:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password: jingtian
driver-class-name: com.mysql.cj.jdbc.Driver
initial-size: 30
max-active: 100
min-idle: 10
max-wait: 60000
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
validation-query: SELECT 1 FROM DUAL
test-while-idle: true
test-on-borrow: false
test-on-return: false
filters: stat,wall
mybatis-plus:
configuration:
map-underscore-to-camel-case: true
auto-mapping-behavior: full
mapper-locations: classpath*:mapper/**/*Mapper.xml5、Controller代码
@Scope(scopeName = "prototype")
@RestController
@RequestMapping("/goods-stock")
public class GoodsStockController {
@Autowired
IGoodsStockService goodsStockService;
@GetMapping("{goodsNo}")
public String purchase(@PathVariable("goodsNo") Integer goodsNo) throws InterruptedException {
QueryWrapper<GoodsStock> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("goods_no",goodsNo);
GoodsStock goodsStock = goodsStockService.getOne(queryWrapper);
Thread.sleep(new Random().nextInt(1000));//增加问题出现的频率
if(goodsStock==null){
return "指定商品不存在";
}
if(goodsStock.getStock().intValue()<1){
return "库存不够";
}
goodsStock.setStock(goodsStock.getStock()-1);
boolean res = goodsStockService.updateById(goodsStock);
if(res){
return "抢购书籍:"+goodsNo+"成功";
}
return "抢购失败";
}
}
上述代码使用jmeter进行压测,用1500个线程,库存数量设置成100,监视数据库中库存的变化发现,整个库存变化过程是非常混乱的。1500个线程去调抢购方法有可能都成功抢到了,但是库存可能只减了很少的一部分。
2.2 引入分布式锁
curator对于锁这块做了一些封装,curator提供了InterProcessMutex 这样一个api。除了分布式锁之外,还提供了leader选举、分布式队列等常用的功能。
-
InterProcessMutex:分布式可重入排它锁
-
InterProcessSemaphoreMutex:分布式排它锁
-
InterProcessReadWriteLock:分布式读写锁
1、修改GoodsController,增加锁机制:
@Scope(scopeName = "prototype")
@RestController
@RequestMapping("/goods-stock")
public class GoodsStockController {
@Autowired
IGoodsStockService goodsStockService;
@Autowired
CuratorFramework curatorFramework;
@GetMapping("{goodsNo}")
public String purchase(@PathVariable("goodsNo")Integer goodsNo) throws Exception {
QueryWrapper<GoodsStock> queryWrapper=new QueryWrapper<>();
queryWrapper.eq("goods_no",goodsNo);
//基于临时有序节点来实现的分布式锁.
InterProcessMutex lock=new InterProcessMutex(curatorFramework,"/Locks");
try {
lock.acquire(); //抢占分布式锁资源(阻塞的)
GoodsStock goodsStock = goodsStockService.getOne(queryWrapper);
Thread.sleep(new Random().nextInt(1000));
if (goodsStock == null) {
return "指定商品不存在";
}
if (goodsStock.getStock().intValue() < 1) {
return "库存不够";
}
goodsStock.setStock(goodsStock.getStock() - 1);
boolean res = goodsStockService.updateById(goodsStock);
if (res) {
return "抢购书籍:" + goodsNo + "成功";
}
}finally {
lock.release(); //释放锁
}
return "抢购失败";
}
}2、CuratorConfig
@Configuration
public class CuratorConfig {
@Bean
public CuratorFramework curatorFramework(){
CuratorFramework curatorFramework= CuratorFrameworkFactory
.builder()
.connectString("127.0.0.1:2181")
.sessionTimeoutMs(25000)
.connectionTimeoutMs(20000)
.retryPolicy(new ExponentialBackoffRetry(1000,10))
.build();
curatorFramework.start();
return curatorFramework;
}
}继续通过jmeter压测,可以看到就不存在库存超卖问题了。
第3章 分布式锁原理
前面我们已经理解的Zookeeper实现分布式锁的原理,以及基于Curator完成了分布式锁的使用,那么我们继续来分析Curator是如何基于代码实现这一过程。

3.1 抢占锁原理
3.1.1 Curator构造函数
InterProcessMutex(CuratorFramework client, String path, String lockName, int maxLeases, LockInternalsDriver driver) {
this.threadData = Maps.newConcurrentMap();
// maxLeases=1,表示可以获得分布式锁的线程数量(跨JVM)为1,即为互斥锁
// 锁节点的名称前缀,lock-0000001, 后面部分是有序递增的序列号
this.basePath = PathUtils.validatePath(path);
// internals的类型为LockInternals,InterProcessMutex将分布式锁的申请和释放操作委托给internals执行
this.internals = new LockInternals(client, driver, path, lockName, maxLeases);
}3.1.2 acquire
调用acquire方法,该方法有两个重载方法,另外一个是带超时时间,当等待超时没有获得锁则放弃锁的占用。
public void acquire() throws Exception {//无限期等待
if (!this.internalLock(-1L, (TimeUnit)null)) {
throw new IOException("Lost connection while trying to acquire lock: " + this.basePath);
}
}3.1.3 internalLock
private boolean internalLock(long time, TimeUnit unit) throws Exception {
//得到当前线程
Thread currentThread = Thread.currentThread();
//使用threadData存储线程重入的情况
InterProcessMutex.LockData lockData = (InterProcessMutex.LockData)this.threadData.get(currentThread);
if (lockData != null) {
//同一线程再次acquire,首先判断当前的映射表内(threadData)是否有该线程的锁信息,如果有则原子+1,然后返回
lockData.lockCount.incrementAndGet();
return true;
} else {
// 映射表内没有对应的锁信息,尝试通过LockInternals获取锁
String lockPath = this.internals.attemptLock(time, unit, this.getLockNodeBytes());
if (lockPath != null) {
// 成功获取锁,记录信息到映射表
InterProcessMutex.LockData newLockData = new InterProcessMutex.LockData(currentThread, lockPath);
this.threadData.put(currentThread, newLockData);
return true;
} else {
return false;
}
}
}// 映射表
// 记录线程与锁信息的映射关系
private final ConcurrentMap<Thread, LockData> threadData = Maps.newConcurrentMap();
// 锁信息
// Zookeeper中一个临时顺序节点对应一个“锁”,但让锁生效激活需要排队(公平锁),下面会继续分析
private static class LockData
{
final Thread owningThread;
final String lockPath;
final AtomicInteger lockCount = new AtomicInteger(1);// 分布式锁重入次数
private LockData(Thread owningThread, String lockPath)
{
this.owningThread = owningThread;
this.lockPath = lockPath;
}
}3.1.4 attemptLock
尝试获得锁,实际上是向zookeeper注册一个临时有序节点,并且判断当前创建的节点的顺序是否是最小节点。如果是则表示获得锁成功
// 尝试获取锁,并返回锁对应的Zookeeper临时顺序节点的路径
String attemptLock(long time, TimeUnit unit, byte[] lockNodeBytes) throws Exception
{
final long startMillis = System.currentTimeMillis();
// 无限等待时,millisToWait为null
final Long millisToWait = (unit != null) ? unit.toMillis(time) : null;
// 创建ZNode节点时的数据内容,无关紧要,这里为null
final byte[] localLockNodeBytes = (revocable.get() != null) ? new byte[0] : lockNodeBytes;
// 当前已经重试次数,与CuratorFramework的重试策略有关
int retryCount = 0;
// 在Zookeeper中创建的临时顺序节点的路径,相当于一把待激活的分布式锁
// 激活条件:同级目录子节点,名称排序最小(排队,公平锁),后续继续分析
String ourPath = null;
boolean hasTheLock = false;
// 是否已经完成尝试获取分布式锁的操作
boolean isDone = false;
while ( !isDone )
{
isDone = true;
try
{
// 从InterProcessMutex的构造函数可知实际driver为StandardLockInternalsDriver的实例
// 在Zookeeper中创建临时顺序节点
ourPath = driver.createsTheLock(client, path, localLockNodeBytes);
// 循环等待来激活分布式锁,实现锁的公平性,后续继续分析
hasTheLock = internalLockLoop(startMillis, millisToWait, ourPath);
}
catch ( KeeperException.NoNodeException e )
{
// 容错处理,不影响主逻辑的理解,可跳过
// 因为会话过期等原因,StandardLockInternalsDriver因为无法找到创建的临时顺序节点而抛出NoNodeException异常
if ( client.getZookeeperClient().getRetryPolicy().allowRetry(retryCount++, System.currentTimeMillis() - startMillis, RetryLoop.getDefaultRetrySleeper()) )
{
isDone = false;
}
else
{
// 不满足重试策略则继续抛出NoNodeException
throw e;
}
}
}
// 成功获得分布式锁,返回临时顺序节点的路径,上层将其封装成锁信息记录在映射表,方便锁重入
if ( hasTheLock )
{
return ourPath;
}
return null;
}3.1.5 createsTheLock
public String createsTheLock(CuratorFramework client, String path, byte[] lockNodeBytes) throws Exception
{
String ourPath;
// lockNodeBytes不为null则作为数据节点内容,否则采用默认内容(IP地址)
if ( lockNodeBytes != null )
{
// creatingParentContainersIfNeeded:用于创建容器节点
// withProtection:临时子节点会添加GUID前缀
ourPath = client.create().creatingParentContainersIfNeeded().withProtection().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(path, lockNodeBytes);
}
else
{
// CreateMode.EPHEMERAL_SEQUENTIAL:临时顺序节点,Zookeeper能保证在节点产生的顺序性
// 依据顺序来激活分布式锁,从而也实现了分布式锁的公平性,后续继续分析
ourPath = client.create().creatingParentContainersIfNeeded().withProtection().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(path);
}
return ourPath;
}3.1.6 internalLockLoop
// 循环等待来激活分布式锁,实现锁的公平性
private boolean internalLockLoop(long startMillis, Long millisToWait, String ourPath) throws Exception
{
boolean haveTheLock = false;// 是否已经持有分布式锁
boolean doDelete = false;// 是否需要删除子节点
try
{
if ( revocable.get() != null )
{
client.getData().usingWatcher(revocableWatcher).forPath(ourPath);
}
//在没有获得锁的情况下持续循环
while ( (client.getState() == CuratorFrameworkState.STARTED) && !haveTheLock )
{
List<String> children = getSortedChildren();// 获取排序后的子节点列表
// 获取前面自己创建的临时顺序子节点的名称
String sequenceNodeName = ourPath.substring(basePath.length() + 1); // +1 to include the slash
// 实现锁的公平性的核心逻辑,看下面的分析
PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases);
if ( predicateResults.getsTheLock() ) // 获得了锁,中断循环,继续返回上层
{
haveTheLock = true;
}
else// 没有获得到锁,监听上一临时顺序节点
{
String previousSequencePath = basePath + "/" + predicateResults.getPathToWatch();
synchronized(this)
{
try
{
// exists()会导致资源泄漏,因此exists()可以监听不存在的ZNode,因此采用getData()
// 上一临时顺序节点如果被删除,会唤醒当前线程继续竞争锁,正常情况下能直接获得锁,因为锁是公平的
client.getData().usingWatcher(watcher).forPath(previousSequencePath);
if ( millisToWait != null )//是否有超时机制
{
millisToWait -= (System.currentTimeMillis() - startMillis);
startMillis = System.currentTimeMillis();
if ( millisToWait <= 0 )
{
doDelete = true; // 获取锁超时,标记删除之前创建的临时顺序节点
break;
}
wait(millisToWait);//限时等待被唤醒
}
else
{
wait();//不限时等待
}
}
catch ( KeeperException.NoNodeException e )
{
// 容错处理,逻辑稍微有点绕,可跳过,不影响主逻辑的理解
// client.getData()可能调用时抛出NoNodeException,原因可能是锁被释放或会话过期(连接丢失)等
// 这里并没有做任何处理,因为外层是while循环,
//再次执行driver.getsTheLock时会调用validateOurIndex
// 此时会抛出NoNodeException,从而进入下面的catch和finally逻辑,
//重新抛出上层尝试重试获取锁并删除临时顺序节
}
}
}
}
}
catch ( Exception e )
{
ThreadUtils.checkInterrupted(e);
doDelete = true;// 标记删除,在finally删除之前创建的临时顺序节点(后台不断尝试)
throw e;// 重新抛出,尝试重新获取锁
}
finally
{
if ( doDelete )
{
deleteOurPath(ourPath);//删除当前节点
}
}
return haveTheLock;
}3.1.7 driver.getsTheLock
StandardLockInternalsDriver
public PredicateResults getsTheLock(CuratorFramework client, List<String> children, String sequenceNodeName, int maxLeases) throws Exception
{
// 之前创建的临时顺序节点在排序后的子节点列表中的索引
int ourIndex = children.indexOf(sequenceNodeName);
// 校验之前创建的临时顺序节点是否有效
validateOurIndex(sequenceNodeName, ourIndex);
// 锁公平性的核心逻辑
// 由InterProcessMutex的构造函数可知,maxLeases为1,
//即只有ourIndex为0时,线程才能持有锁,或者说该线程创建的临时顺序节点激活了锁
// Zookeeper的临时顺序节点特性能保证跨多个JVM的线程并发创建节点时的顺序性,
//越早创建临时顺序节点成功的线程会更早地激活锁或获得锁
boolean getsTheLock = ourIndex < maxLeases;
// 如果已经获得了锁,则无需监听任何节点,否则需要监听上一顺序节点(ourIndex-1)
// 因为锁是公平的,因此无需监听除了(ourIndex-1)以外的所有节点,这是为了减少羊群效应,非常巧妙的设计!!
String pathToWatch = getsTheLock ? null : children.get(ourIndex - maxLeases);
// 返回获取锁的结果,交由上层继续处理(添加监听等操作)
return new PredicateResults(pathToWatch, getsTheLock);
}static void validateOurIndex(String sequenceNodeName, int ourIndex) throws KeeperException
{
if ( ourIndex < 0 )
{
// 容错处理,可跳过
// 由于会话过期或连接丢失等原因,该线程创建的临时顺序节点被Zookeeper服务端删除,往外抛出NoNodeException
// 如果在重试策略允许范围内,则进行重新尝试获取锁,这会重新重新生成临时顺序节点
// 佩服Curator的作者将边界条件考虑得如此周到!
throw new KeeperException.NoNodeException("Sequential path not found: " + sequenceNodeName);
}
}3.2 释放锁原理
3.2.1 release
public void release() throws Exception
{
Thread currentThread = Thread.currentThread();
LockData lockData = threadData.get(currentThread);
if ( lockData == null )
{
// 无法从映射表中获取锁信息,表示当前没有持有锁
throw new IllegalMonitorStateException("You do not own the lock: " + basePath);
}
// 锁是可重入的,初始值为1,原子-1到0,锁才释放
int newLockCount = lockData.lockCount.decrementAndGet();
if ( newLockCount > 0 )
{
return;
}
if ( newLockCount < 0 )
{
throw new IllegalMonitorStateException("Lock count has gone negative for lock: " + basePath);
}
try
{ // lockData != null && newLockCount == 0,释放锁资源
internals.releaseLock(lockData.lockPath);
}
finally
{
// 最后从映射表中移除当前线程的锁信息
threadData.remove(currentThread);
}
}3.2.2 releaseLock
final void releaseLock(String lockPath) throws Exception
{
//移除订阅事件
client.removeWatchers();
revocable.set(null);
// 删除临时顺序节点,只会触发后一顺序节点去获取锁,理论上不存在竞争,只排队,非抢占,公平锁,先到先得
deleteOurPath(lockPath);
}private void deleteOurPath(String ourPath) throws Exception{
try{
// 后台不断尝试删除
client.delete().guaranteed().forPath(ourPath);
}
catch ( KeeperException.NoNodeException e ){
// ignore - already deleted (possibly expired session, etc.)
}
}分布式锁的抢占和释放总体流程总结如下:
1、zk客户端往同一路径下创建临时有序节点,节点创建好之后会尝试激活
2、如果该客户端创建的节点的编号小于1,则表示拿到锁,如果不是则便是有多个线程在抢锁,此时将当前节点添加一个对前一个节点的监听器,如果前一个节点发生变化时,则唤醒当前节点的所有阻塞线程。
3、释放锁的时候则是删除客户端创建的临时有序节点,此时就会触发后一节点的watcher机制,然后触发notifyall
3.3 锁撤销
InterProcessMutex支持一种协商撤销互斥锁的机制, 可以用于死锁的情况想要撤销一个互斥锁可以调用下面这个方法:
public void makeRevocable(RevocationListener<T> listener)这个方法可以让锁持有者来处理撤销动作。 当其他进程/线程想要你释放锁时,就会回调参数中的监听器方法。 但是,此方法不是强制撤销的,是一种协商机制。
当想要去撤销/释放一个锁时,可以通过 Revoker 中的静态方法来发出请求,Revoker.attemptRevoke();
public static void attemptRevoke(CuratorFramework client,String path) throws Exceptionpath :加锁的zk节点path,通常可以通过 InterProcessMutex.getParticipantNodes() 获得
这个方法会发出撤销某个锁的请求。如果锁的持有者注册了上述的 RevocationListener 监听器,那么就会调用监听器方法协商撤销锁。
第4章 实现Leader选举
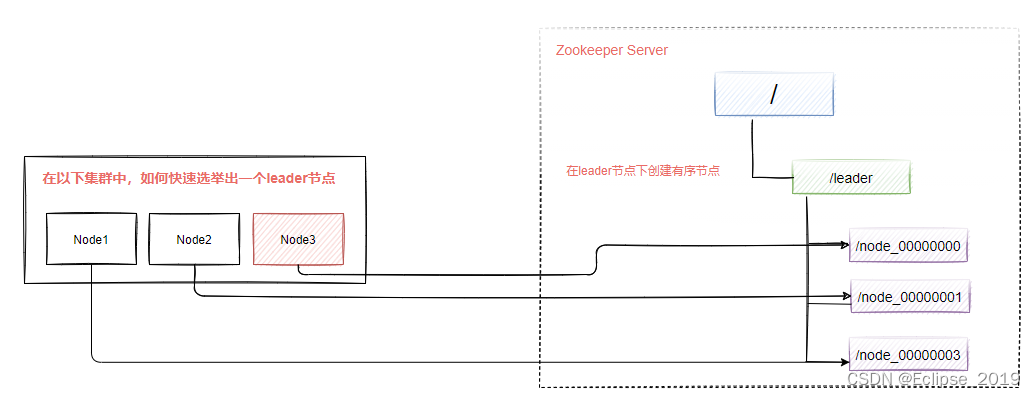
在分布式计算中,leader election是很重要的一个功能,这个选举过程是这样子的:指派一个进程作为组织者,将任务分发给各节点。在任务开始前,哪个节点都不知道谁是leader或者coordinator。当选举算法开始执行后,每个节点最终会得到一个唯一的节点作为任务leader。除此之外,选举还经常会发生在leader意外宕机的情况下,新的leader要被选举出来,如下图所示,这个就是所谓的leader选 举,而zookeeper作为leader选举的功能,在很多中间件中都有使用,比如kafka基于zookeeper实现leader选举,Hadoop、Spark等。
选主算法要满足的几个特征:
1)各个节点均衡的获得成为主节点的权利,一旦主节点被选出,其他的节点可以感知到谁是主节点,被服从分配。
2)主节点是唯一存在的
3)一旦主节点失效,宕机或者断开连接,其他的节点能够感知,并且重新进行选主算法。
作为zookeeper的高级api封装库curator选主算法主要有以下两个:LeaderLatch和LeaderSelector
这两种算法的应用在第一篇文章中已经讲过了,这里不在赘述。接下来按照上面说的三个特征,来分析一下这两种算法的核心流程。
4.1 LeaderLatch
先来了解一下该类给我们提供的几个比较重要的方法
//start方法,开始抢leader
void start();
//close方法释放leader权限
void close();
//await方法阻塞线程,尝试获取leader权限,但不一定成功,超时失败
boolean await(long,TimeUnit);
//判断是否拥有leader权限
boolean hasLeadership();
//LeaderLatchListener是LeaderLatch客户端节点成为Leader后的回调方法,有isLeader(),notLeader()两个方法
//抢主成功时触发
void isLeader();
//抢主失败时触发
void notLeader(); 再来看看LeaderLatch的构造方法
public LeaderLatch(CuratorFramework client, String latchPath, String id, CloseMode closeMode)
{
//zk客户端实例
this.client = Preconditions.checkNotNull(client, "client cannot be null").newWatcherRemoveCuratorFramework();
//Leader选举根节点路径
this.latchPath = PathUtils.validatePath(latchPath);
//客户端id,用来标记客户端,即客户端编号、名称
this.id = Preconditions.checkNotNull(id, "id cannot be null");
//Latch关闭策略,SILENT:关闭时不触发监听器回调,NOTIFY_LEADER:关闭时触发监听器回调,默认是不触发的
this.closeMode = Preconditions.checkNotNull(closeMode, "closeMode cannot be null");
}OK,一些重要的方法分析明白了,接下来我们从入口start开始
4.1.1 start
public void start() throws Exception
{
//通过AtomicReference原子操作判断是否已经启动过
Preconditions.checkState(state.compareAndSet(State.LATENT, State.STARTED), "Cannot be started more than once");
startTask.set(AfterConnectionEstablished.execute(client, new Runnable()
{
@Override
public void run()
{
try
{
//初始化
internalStart();
}
finally
{
startTask.set(null);
}
}
}));
}4.1.2 internalStart
//该方法加了锁
private synchronized void internalStart()
{
if ( state.get() == State.STARTED )
{
//为zk添加连接监听器,该监听器触发时也会调用reset方法
client.getConnectionStateListenable().addListener(listener);
try
{
//初始化
reset();
}
catch ( Exception e )
{
ThreadUtils.checkInterrupted(e);
log.error("An error occurred checking resetting leadership.", e);
}
}
}4.1.3 reset
void reset() throws Exception
{
//设置当前没有成为Leader
setLeadership(false);
setNode(null);
BackgroundCallback callback = new BackgroundCallback()
{
@Override
public void processResult(CuratorFramework client, CuratorEvent event) throws Exception
{
if ( debugResetWaitLatch != null )
{
debugResetWaitLatch.await();
debugResetWaitLatch = null;
}
if ( event.getResultCode() == KeeperException.Code.OK.intValue() )
{
setNode(event.getName());
if ( state.get() == State.CLOSED )
{
setNode(null);
}
else
{
//为latchPath下每个children设置监听事件
getChildren();
}
}
else
{
log.error("getChildren() failed. rc = " + event.getResultCode());
}
}
};
//在latchPath下创建临时有序节点,节点内容为serverId,并设置异步回调
client.create().creatingParentContainersIfNeeded().withProtection().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).inBackground(callback).forPath(ZKPaths.makePath(latchPath, LOCK_NAME), LeaderSelector.getIdBytes(id));
}创建完临时有序节点后,会触发到回调BackgroundCallback里的getChildren()方法,代码如下:
private void getChildren() throws Exception
{
BackgroundCallback callback = new BackgroundCallback()
{
@Override
public void processResult(CuratorFramework client, CuratorEvent event) throws Exception
{
if ( event.getResultCode() == KeeperException.Code.OK.intValue() )
{
//这个方法是核心
checkLeadership(event.getChildren());
}
}
};
//获取latchPath下子节点信息,获取成功后触发异步回调callback
client.getChildren().inBackground(callback).forPath(ZKPaths.makePath(latchPath, null));
}4.1.4 checkLeadership
private void checkLeadership(List<String> children) throws Exception
{
final String localOurPath = ourPath.get();
//按节点编号排序
List<String> sortedChildren = LockInternals.getSortedChildren(LOCK_NAME, sorter, children);
int ourIndex = (localOurPath != null) ? sortedChildren.indexOf(ZKPaths.getNodeFromPath(localOurPath)) : -1;
if ( ourIndex < 0 )
{
log.error("Can't find our node. Resetting. Index: " + ourIndex);
reset();
}
else if ( ourIndex == 0 )
{
//如果当前节点编号最小,设置当前节点为Leader
setLeadership(true);
}
else
{
//抢主失败,监听前面一个节点
String watchPath = sortedChildren.get(ourIndex - 1);
Watcher watcher = new Watcher()
{
@Override
public void process(WatchedEvent event)
{
//监听前一个节点的删除事件,重新进入getChildren方法判断是否抢主成功
if ( (state.get() == State.STARTED) && (event.getType() == Event.EventType.NodeDeleted) && (localOurPath != null) )
{
try
{
getChildren();
}
catch ( Exception ex )
{
ThreadUtils.checkInterrupted(ex);
log.error("An error occurred checking the leadership.", ex);
}
}
}
};
BackgroundCallback callback = new BackgroundCallback()
{
@Override
public void processResult(CuratorFramework client, CuratorEvent event) throws Exception
{
if ( event.getResultCode() == KeeperException.Code.NONODE.intValue() )
{
// previous node is gone - reset
reset();
}
}
};
//设置对前一个节点删除事件的监听器,并在异步回调里重新进行抢主
client.getData().usingWatcher(watcher).inBackground(callback).forPath(ZKPaths.makePath(latchPath, watchPath));
}
}核心流程就是:
1、zk客户端往同一路径下创建临时节点,创建后回调callBack
2、在回调事件中判断自身节点是否是节点编号最小的一个
3、如果是,则抢主成功,如果不是,设置对前一个节点的删除事件的监听器,删除事件出发后重新进行抢主
4.2 LeaderSelector
一样的,也先来了解一下该类给我们提供的几个比较重要的方法
//开始抢主
void start();
//在抢到leader权限并释放后,自动加入抢主队列,重新抢主
void autoRequeue();
//LeaderSelectorListener是LeaderSelector客户端节点成为Leader后回调的一个监听器,在takeLeadership()回调方法中编写获得Leader权利后的业务处理逻辑
//抢注成功后回调
void takeLeadership();
//LeaderSelectorListenerAdapter是实现了LeaderSelectorListener接口的一个抽象类,封装了客户端与zk服务器连接挂起或者断开时的处理逻辑(抛出抢主失败CancelLeadershipException),一般监听器推荐实现该类
再来看看LeaderSelector的构造方法
public LeaderSelector(CuratorFramework client, String leaderPath, CloseableExecutorService executorService, LeaderSelectorListener listener)
{
...
}-
client:zk客户端实例
-
leaderPath:Leader选举根节点路径
-
executorService:master选举使用的线程池
-
listener:节点成为Leader后的回调监听器
接下来我们同样从入口start开始分析一下源码,在start里面调用了requeue,requeue又调用了internalRequeue
4.2.1 internalRequeue
private synchronized boolean internalRequeue()
{
//没有进入抢主并且已经调用过start方法
if ( !isQueued && (state.get() == State.STARTED) )
{
isQueued = true;
Future<Void> task = executorService.submit(new Callable<Void>()
{
@Override
public Void call() throws Exception
{
try
{
//开始抢主
doWorkLoop();
}
finally
{
clearIsQueued();
//如果设置了释放权限自动抢主,则重新开始抢主
if ( autoRequeue.get() )
{
internalRequeue();
}
}
return null;
}
});
ourTask.set(task);
return true;
}
return false;
}流程进入到doWorkLoop中的doWork方法
4.2.2 doWork
void doWork() throws Exception
{
hasLeadership = false;
try
{
//利用InterProcessMutex抢占锁
mutex.acquire();
hasLeadership = true;
try
{
//抢锁成功,触发监听器takeLeadership方法
listener.takeLeadership(client);
}
}
finally
{
//触发完监听器方法后,释放Leader权限,释放分布式锁
if ( hasLeadership )
{
hasLeadership = false;
try
{
mutex.release();
}
}
}
}实际上流程也比较简单,主要利用了Curator内置的InterProcessMutex分布式锁来实现Leader选举,InterProcessMutex的原理实际上和LeaderLatch非常相似。
4.3 对比
LeaderSelector相对LeaderLatch更加灵活,在执行完takeLeadership中的逻辑后会自动释放Leader权限,也能调用autoReQueue自动重新抢锁
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/76684.html

