
学习目标
-
Dubbo的集群容错有哪几种及各自的特点
-
Dubbo的集群容错原理
第1章 集群容错原理分析
废话不多说,先贴流程图
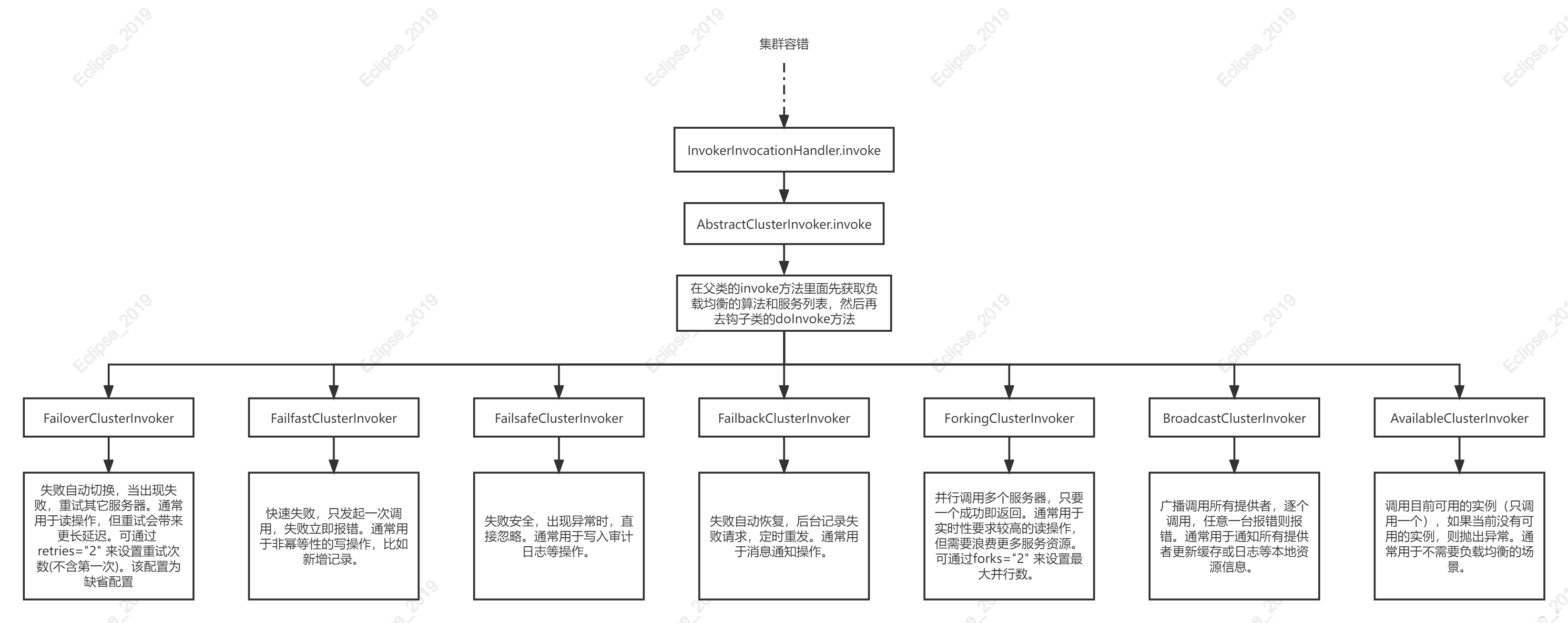
1.1 功能描述
集群调用失败时,Dubbo 提供的容错方案
在集群调用失败时,Dubbo 提供了多种容错方案,缺省为 failover 重试。
我们来分析一下各种集群容错策略的不同
1.2 FailoverClusterInvoker
1.2.1 使用场景
失败自动切换,当出现失败,重试其它服务器。通常用于读操作,但重试会带来更长延迟。可通过 retries=”2″ 来设置重试次数(不含第一次)。该配置为缺省配置
1.2.2 源码分析
当调用invoke方法进行调用流转时,如果走到了集群容错的逻辑,那么先会走到他们的父类中,父类里面定义了如何获取服务列表和获取负载均衡算法的逻辑,从父类的方法中就可以获取到这两种东西,然后有一个doInvoke方法是一个抽象的方法,该方法是一个钩子方法,采用了模板设计模式,这样的话就会勾到子类的逻辑当中去,是哪个子类的实例就会勾到哪个实例的中去,不同的实例是通过配置参数来决定的:
配置如下:
cluster = “failover”
@DubboReference(check = false/*,url = "dubbo://localhost:20880"*/,retries = 3,timeout = 6000,cluster = "failover",loadbalance = "random")@Override
public Result invoke(final Invocation invocation) throws RpcException {
//判断是否销毁
checkWhetherDestroyed();
// binding attachments into invocation.
// Map<String, Object> contextAttachments =
RpcContext.getClientAttachment().getObjectAttachments();
// if (contextAttachments != null && contextAttachments.size() != 0) {
// ((RpcInvocation)
invocation).addObjectAttachmentsIfAbsent(contextAttachments);
// }
//获取服务列表
List<Invoker<T>> invokers = list(invocation);
//spi 获取负载均衡类实例
LoadBalance loadbalance = initLoadBalance(invokers, invocation);
RpcUtils.attachInvocationIdIfAsync(getUrl(), invocation);
return doInvoke(invocation, invokers, loadbalance);
}以上是父类的流程逻辑,获取到了服务列表,spi的方式获取到了负载均衡算法。
public Result doInvoke(Invocation invocation, final List<Invoker<T>> invokers, LoadBalance
loadbalance) throws RpcException {
List<Invoker<T>> copyInvokers = invokers;
//invokers校验
checkInvokers(copyInvokers, invocation);
String methodName = RpcUtils.getMethodName(invocation);
//计算调用次数
int len = calculateInvokeTimes(methodName);
// retry loop.
RpcException le = null; // last exception.
//记录已经调用过了的服务列表
List<Invoker<T>> invoked = new ArrayList<Invoker<T>>(copyInvokers.size()); // invoked invokers.
Set<String> providers = new HashSet<String>(len);
for (int i = 0; i < len; i++) {
//Reselect before retry to avoid a change of candidate `invokers`.
//NOTE: if `invokers` changed, then `invoked` also lose accuracy.
//如果掉完一次后,服务列表更新了,再次获取服务列表
if (i > 0) {
checkWhetherDestroyed();
copyInvokers = list(invocation);
// check again
checkInvokers(copyInvokers, invocation);
}
//根据负载均衡算法,选择一个服务调用
Invoker<T> invoker = select(loadbalance, invocation, copyInvokers, invoked);
//记录已经调用过的invoker
invoked.add(invoker);
RpcContext.getServiceContext().setInvokers((List) invoked);
try {
//具体的服务调用逻辑
Result result = invokeWithContext(invoker, invocation);
if (le != null && logger.isWarnEnabled()) {
logger.warn("Although retry the method " + methodName
+ " in the service " + getInterface().getName()
+ " was successful by the provider " + invoker.getUrl().getAddress()
+ ", but there have been failed providers " + providers
+ " (" + providers.size() + "/" + copyInvokers.size()
+ ") from the registry " + directory.getUrl().getAddress()
+ " on the consumer " + NetUtils.getLocalHost()
+ " using the dubbo version " + Version.getVersion() + ". Last error is: "
+ le.getMessage(), le);
}
return result;
} catch (RpcException e) {
if (e.isBiz()) { // biz exception.
throw e;
}
le = e;
} catch (Throwable e) {
le = new RpcException(e.getMessage(), e);
} finally {
providers.add(invoker.getUrl().getAddress());
}
}
throw new RpcException(le.getCode(), "Failed to invoke the method "
+ methodName + " in the service " + getInterface().getName()
+ ". Tried " + len + " times of the providers " + providers
+ " (" + providers.size() + "/" + copyInvokers.size()
+ ") from the registry " + directory.getUrl().getAddress()
+ " on the consumer " + NetUtils.getLocalHost() + " using the dubbo version "
+ Version.getVersion() + ". Last error is: "
+ le.getMessage(), le.getCause() != null ? le.getCause() : le);
}以上就是FailoverClusterInvoker的doinvoke的核心逻辑,可以看到它是通过一个for循环的方式来重试调用的,重试的次数是通过retries属性来配置的。如果重试N次后还是调用失败,那么注解就throw了一个RpcException了。
1.3 FailfastClusterInvoker
1.3.1 使用场景
快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
1.3.2 源码分析
@Override
public Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance
loadbalance) throws RpcException {
checkInvokers(invokers, invocation);
//负载均衡选择一个invoker
Invoker<T> invoker = select(loadbalance, invocation, invokers, null);
try {
//掉后端接口
return invokeWithContext(invoker, invocation);
} catch (Throwable e) {
if (e instanceof RpcException && ((RpcException) e).isBiz()) { // biz exception.
throw (RpcException) e;
}
//如果调用出现异常,直接把异常包装成RpcException往上抛了
throw new RpcException(e instanceof RpcException ? ((RpcException) e).getCode() :
0,
"Failfast invoke providers " + invoker.getUrl() + " " +
loadbalance.getClass().getSimpleName()
+ " for service " + getInterface().getName()
+ " method " + invocation.getMethodName() + " on consumer " +
NetUtils.getLocalHost()
+ " use dubbo version " + Version.getVersion()
+ ", but no luck to perform the invocation. Last error is: " +
e.getMessage(),
e.getCause() != null ? e.getCause() : e);
}
}可以看到这种集群容错就是如果出现异常不会重试直接往上抛异常了。
1.4 FailsafeClusterInvoker
1.4.1 使用场景
失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
1.4.2 源码分析
@Override
public Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance
loadbalance) throws RpcException {
try {
checkInvokers(invokers, invocation);
Invoker<T> invoker = select(loadbalance, invocation, invokers, null);
return invokeWithContext(invoker, invocation);
} catch (Throwable e) {
//可以看到这里,如果调用有异常了,这里是直接打印日志然后返回结果,相当于忽略了异常
logger.error("Failsafe ignore exception: " + e.getMessage(), e);
return AsyncRpcResult.newDefaultAsyncResult(null, null, invocation); // ignore
}
}可以看到这里,如果调用有异常了,这里是直接打印日志然后返回结果,相当于忽略了异常
1.5 FailbackClusterInvoker
1.5.1 使用场景
失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
1.5.2 源码分析
@Override
protected Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance
loadbalance) throws RpcException {
Invoker<T> invoker = null;
try {
checkInvokers(invokers, invocation);
invoker = select(loadbalance, invocation, invokers, null);
return invokeWithContext(invoker, invocation);
} catch (Throwable e) {
logger.error("Failback to invoke method " + invocation.getMethodName() + ", wait for retry in background. Ignored exception: " + e.getMessage() + ", ", e);
//可以看这里把失败调用记录了下来,用于定时器重发
addFailed(loadbalance, invocation, invokers, invoker);
return AsyncRpcResult.newDefaultAsyncResult(null, null, invocation); // ignore
}
}private void addFailed(LoadBalance loadbalance, Invocation invocation, List<Invoker<T>>
invokers, Invoker<T> lastInvoker) {
if (failTimer == null) {
synchronized (this) {
if (failTimer == null) {
failTimer = new HashedWheelTimer(
new NamedThreadFactory("failback-cluster-timer", true),
1,
TimeUnit.SECONDS, 32, failbackTasks);
}
}
}
RetryTimerTask retryTimerTask = new RetryTimerTask(loadbalance, invocation, invokers,
lastInvoker, retries, RETRY_FAILED_PERIOD);
try {
failTimer.newTimeout(retryTimerTask, RETRY_FAILED_PERIOD, TimeUnit.SECONDS);
} catch (Throwable e) {
logger.error("Failback background works error,invocation->" + invocation + ",exception: " + e.getMessage());
}
}这里是采用时间轮的方式来定时重发的,时间轮在后面的文章中会讲,这里不做过多的解释。
1.6 ForkingClusterInvoker
1.6.1 使用场景
并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过forks=”2″ 来设置最大并行数。
1.6.2 源码分析
public Result doInvoke(final Invocation invocation, List<Invoker<T>> invokers, LoadBalance
loadbalance) throws RpcException {
try {
checkInvokers(invokers, invocation);
final List<Invoker<T>> selected;
final int forks = getUrl().getParameter(FORKS_KEY, DEFAULT_FORKS);
final int timeout = getUrl().getParameter(TIMEOUT_KEY, DEFAULT_TIMEOUT);
if (forks <= 0 || forks >= invokers.size()) {
selected = invokers;
} else {
selected = new ArrayList<>(forks);
while (selected.size() < forks) {
Invoker<T> invoker = select(loadbalance, invocation, invokers, selected);
if (!selected.contains(invoker)) {
//Avoid add the same invoker several times.
selected.add(invoker);
}
}
}
RpcContext.getServiceContext().setInvokers((List) selected);
final AtomicInteger count = new AtomicInteger();
final BlockingQueue<Object> ref = new LinkedBlockingQueue<>();
//selected中是根据forks的配置从服务列表里面根据负载均衡算法选择出来的invoker对象
for (final Invoker<T> invoker : selected) {
//异步调用每一个invoker对象
executor.execute(() -> {
try {
Result result = invokeWithContext(invoker, invocation);
//把调用的返回结果存入队列
ref.offer(result);
} catch (Throwable e) {
int value = count.incrementAndGet();
if (value >= selected.size()) {
ref.offer(e);
}
}
});
}
try {
//等待获取返回结果,如果等待超时直接返回null,这里会拿到第一个先返回的结果直接返回
Object ret = ref.poll(timeout, TimeUnit.MILLISECONDS);
if (ret instanceof Throwable) {
Throwable e = (Throwable) ret;
throw new RpcException(e instanceof RpcException ? ((RpcException)
e).getCode() : 0, "Failed to forking invoke provider " + selected + ", but no luck to perform the invocation. Last error is: " + e.getMessage(), e.getCause() != null ?
e.getCause() : e);
}
return (Result) ret;
} catch (InterruptedException e) {
throw new RpcException("Failed to forking invoke provider " + selected + ", but no luck to perform the invocation. Last error is: " + e.getMessage(), e);
}
} finally {
// clear attachments which is binding to current thread.
RpcContext.getClientAttachment().clearAttachments();
}
}等待获取返回结果,如果等待超时直接返回null,这里会拿到第一个先返回的结果直接返回
1.7 BroadcastClusterInvoker
1.7.1 使用场景
广播调用所有提供者,逐个调用,任意一台报错则报错。通常用于通知所有提供者更新缓存或日志等本地资源信息。
1.7.2 源码分析
public Result doInvoke(final Invocation invocation, List<Invoker<T>> invokers, LoadBalance
loadbalance) throws RpcException {
checkInvokers(invokers, invocation);
RpcContext.getServiceContext().setInvokers((List) invokers);
RpcException exception = null;
Result result = null;
URL url = getUrl();
// The value range of broadcast.fail.threshold must be 0~100.
// 100 means that an exception will be thrown last, and 0 means that as long as an exception occurs, it will be thrown.
// see https://github.com/apache/dubbo/pull/7174
int broadcastFailPercent = url.getParameter(BROADCAST_FAIL_PERCENT_KEY,
MAX_BROADCAST_FAIL_PERCENT);
if (broadcastFailPercent < MIN_BROADCAST_FAIL_PERCENT || broadcastFailPercent >
MAX_BROADCAST_FAIL_PERCENT) {
logger.info(String.format("The value corresponding to the broadcast.fail.percent parameter must be between 0 and 100. " + "The current setting is %s, which is reset to 100.",broadcastFailPercent));
broadcastFailPercent = MAX_BROADCAST_FAIL_PERCENT;
}
int failThresholdIndex = invokers.size() * broadcastFailPercent /
MAX_BROADCAST_FAIL_PERCENT;
int failIndex = 0;
//从这for循环可以看出,就是循环所有的invokers对象,然后一一调用
for (Invoker<T> invoker : invokers) {
try {
result = invokeWithContext(invoker, invocation);
if (null != result && result.hasException()) {
Throwable resultException = result.getException();
if (null != resultException) {
exception = getRpcException(result.getException());
logger.warn(exception.getMessage(), exception);
if (failIndex == failThresholdIndex) {
break;
} else {
failIndex++;
}
}
}
} catch (Throwable e) {
exception = getRpcException(e);
logger.warn(exception.getMessage(), exception);
if (failIndex == failThresholdIndex) {
break;
} else {
failIndex++;
}
}
}
if (exception != null) {
if (failIndex == failThresholdIndex) {
logger.debug(
String.format("The number of BroadcastCluster call failures has reached the threshold %s", failThresholdIndex));
} else {
logger.debug(String.format("The number of BroadcastCluster call failures has not reached the threshold %s, fail size is %s",failIndex));
}
throw exception;
}
return result;
}从这for循环可以看出,就是循环所有的invokers对象,然后一一调用
1.8 AvailableClusterInvoker
1.8.1 使用场景
调用目前可用的实例(只调用一个),如果当前没有可用的实例,则抛出异常。通常用于不需要负载均衡的场景。
1.8.2 源码分析
@Override
public Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance
loadbalance) throws RpcException {
//循环所有的负载列表,isAvailable()是远程调用服务是否存活,如果存活就掉用它,这里没有负载均衡的逻辑
for (Invoker<T> invoker : invokers) {
if (invoker.isAvailable()) {
return invokeWithContext(invoker, invocation);
}
}
throw new RpcException("No provider available in " + invokers);
}循环所有的负载列表,isAvailable()是远程调用服务是否存活,如果存活就掉用它,这里没有负载均衡的逻辑。
下文预告
-
Dubbo的负载均衡策略有哪些及各自特点
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/76699.html

