
requests & urllib简单介绍
一. requests用法
1.1 文件上传功能
import requests
f = open('favicon.ico', 'rb')
files = { 'file': f }
r = requests.post('http://httpbin.org/post', files=files) print(res.text)
1.headers添加cookie键值对 --> Session
2.RequestsCookieJar对象
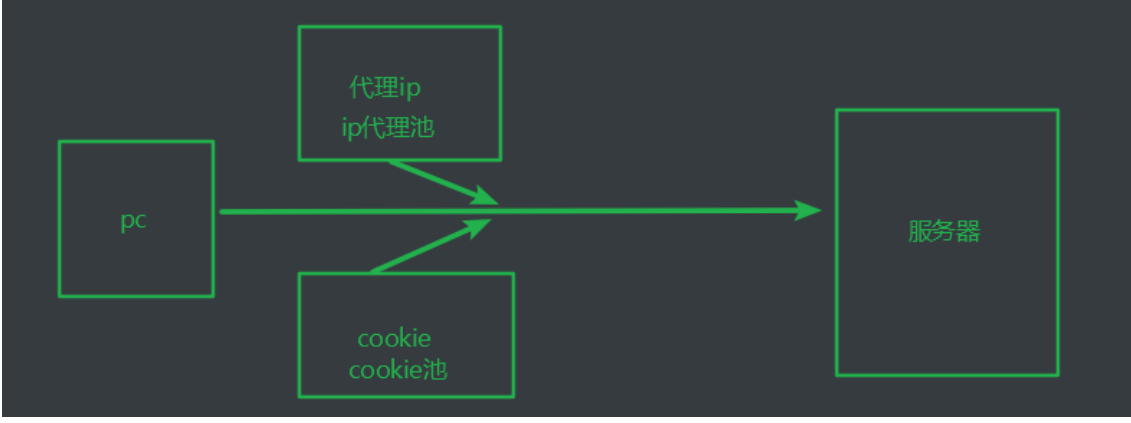
# headers内添加cookie键值对处理cookie
import requests url = 'https://www.baidu.com'
headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36', 'Cookies':'BAIDUID=79A570F8D90B2C45E42D40A3666ADC46:FG=1; BIDUPSID=79A570F8D90B2C45E42D40A3666ADC46; PSTM=1551074009; BD_UPN=12314753; sugstore=0; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; yjs_js_security_passport=10c9ca61409abe70ac5c03db796f78648e697d8f_1563711806_js; COOKIE_SESSION=2860_2_2_7_3_5_0_0_2_4_106_0_3778_177561_116_109_1563714759_15637 14752_1563714643%7C9%23177557_14_1563714643%7C7; delPer=0; BD_HOME=0; H_PS_PSSID=1452_21117_29522_29521_28519_29099_28831_29221' }
res = requests.get(url=url, headers=headers)
res.encoding = 'utf-8'
with open('baidu_cookie.html', 'w', encoding='utf-8') as f:
f.write(res.text)
# RequestsCookieJar对象处理cookie: 用cookie维持百度登陆
import requests cookies = 'BAIDUID=79A570F8D90B2C45E42D40A3666ADC46:FG=1; BIDUPSID=79A570F8D90B2C45E42D40A3666ADC46; PSTM=1551074009; BD_UPN=12314753; sugstore=0; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; yjs_js_security_passport=10c9ca61409abe70ac5c03db796f78648e697d8f_1563711806_js; COOKIE_SESSION=2860_2_2_7_3_5_0_0_2_4_106_0_3778_177561_116_109_1563714759_15637 14752_1563714643%7C9%23177557_14_1563714643%7C7; delPer=0; BD_HOME=0; H_PS_PSSID=1452_21117_29522_29521_28519_29099_28831_29221; BDUSS=lSVnBVVkRVNFpNZ2ZJZ2ZpNFpjblFFSX5EaW9DNzBpcnNkaDZIQVdRd2Z1bHhkRVFBQUFBJCQA AAAAAAAAAAEAAABwfMtW09rQodPjMDgyMGZyZWUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA AAAAAAAAAAAAAAAAAAAAAAAAAB8tNV0fLTVdYX'
jar = requests.cookies.RequestsCookieJar()
headers = { 'User-Agetn': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36' }
for cookie in cookies.split(';'):
key, value = cookie.split('=', 1)
jar.set(key, value)
res = requests.get('http://www.baidu.com', cookies=jar, headers=headers)
print(res.text)
# 响应数据中包含用户名信息, 说明cookie生效
1.3 会话维持与模拟登陆
# HTTP无状态:
使用requests模块中的get()和post()方法请求网页时, 每一次请求都是独立的, 没有连续请求之间 的状态保持, 如果你登陆了淘宝后向查看订单, 那么如果没有状态的维持就无法实现.
# 会话的维持: Session对象
from requests import Session
s = Session()
res = s.get('https://www.baidu.com')
# 人人网登陆案例:
from requests import Session
session = Session()
url = 'http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=2019761744568'
headers = { "USer-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36' }
data = { 'email': '17679962330', 'autoLogin': 'true', 'icode': '', 'origURL': 'http://www.renren.com/home', 'domain': 'renren.com', 'key_id': '1', 'captcha_type': 'web_login', 'password': '6ea935849c9dbfc4ac484718ac8652a14f4b2f60036de7a279e84be08bc54136', 'rkey': '1c7df63368df7ce73c234de26178ec11', 'f': 'http%3A%2F%2Fwww.renren.com%2F972036549%2Fnewsfeed%2Fphoto', }
res = session.post(url=url, data=data, headers=headers)
ret = session.get(url='http://www.renren.com/972036549/profile', headers=headers)
ret.encoding = 'utf-8'
with open('renren.html', 'w', encoding='utf-8') as f:
f.write(ret.text)
1.4 SSL 证书验证
# 1.SSL证书验证
requests提供了证书验证的功能. 当发起HTTP请求时, 模块会检查SSL证书. 但检查的行为可以用verify 参数来控制.
verify = False # 不检查SSL证书
verify = True # 检查SSL证书 、
# 2.异常
如果使用requests模块的SSL验证, 验证不通过会抛出异常, 此时可以将verify参数设置为False
# 3.www.12306.cn的证书验证
# 会抛出异常
import requests
response = requests.get('https://www.12306.cn') print(response.status_code)
# 不抛异常, 但会出现警告
import requests
response = requests.get('https://www.12306.cn', verify=False) print(response.status_code)
# 异常:
SSLError requests.exceptions.SSLError
1.5 代理设置
# 代理:
代理即代理ip 代理ip是指在请求的过程中使用非本机ip进行请求, 避免大数据量频繁请求的过程中出现ip封禁, 限制数据 的爬取.
# 代理ip分类:
1.透明代理ip: 请求时, 服务器知道请求的真实ip, 知道请求使用了代理
2.匿名代理ip: 请求时, 服务器知道请求使用了代理, 但不知道请求的真实ip
3.高匿代理ip: 请求时, 服务器不知道请求使用了代理, 也不知道请求的真实ip
# requests 模块使用代理ip
import requests
url = 'http://www.httpbin.org'
proxies = { 'http': 'http://61.183.176.122:57210' }
res = requests.get(url=url, proxies=proxies)
print(res.text)
1.6 超时设置
# 超时设置: 由于网络状况的不同, 服务器配置差异以及服务器处理并发的能力不同, 有时会出现服务器的响应时间 过长, 甚至无法获取响应而抛出异常. requests模块发送请求可以设置超时时间, 在超时时间内未得到响 应, 便会抛出异常. 一方面, 减少了请求的阻塞时间, 一方面, 可以进行异常处理, 执行相应的操作.
import requests
url = 'https://www.baidu.com'
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36' }
res = requests.get(url=url, headers=headers, timeout=0.001)
# 在0.001秒为得到响 应, 抛出requests.exceptions.ConnectTimeout异常
print(res.text)
1.7 构造Request对象
# 1.Prepared Request
利用 Prepared Request 数据结构构建Request对象. 其构建及使用步骤如下:
from requests import Request, Session
# 构建Request对象
url = '...'
data = {... }
params = {... }
headers = {... }
session = Session()
# 构建post请求:
req_post = Request(method='POST', url=url, headers=headers, data=data)
req_obj_post = session.prepare_request(req_post)
# 构建get请求:
req_get = Request(method='GET', url=url, headers=headers, params=params)
req_obj_get = session.prepare_request(req_get)
# 利用构建的请求对象, 向服务器发送请求
res = session.send(req_obj_post)
res = session.send(req_obj_get)
# 应用:
通过此方法, 我们可以构建一个独立的request对象, 当需要请求的url很多时, 我们
可以为每一个url构建 一个request对象, 将所有request对象置于队列中, 便于调
度.
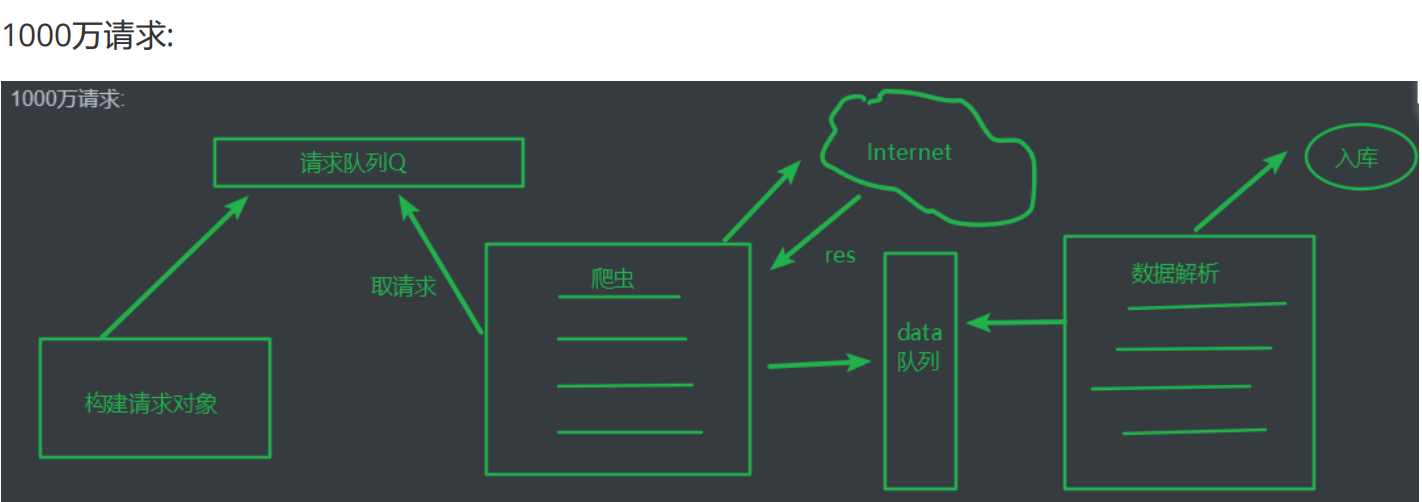
# 构建request对象, 请求糗事百科获取页面
from requests import Request, Session
url = 'https://www.qiushibaike.com/'
headers = { "User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36' }
session = Session()
req_get = Request(url=url, headers=headers, method='GET')
req_get_obj = session.prepare_request(req_get)
res = session.send(req_get_obj)
res.encoding = 'utf-8'
with open('qb_reqobj.html', 'w', encoding='utf-8') as f:
f.write(res.text)
二. urllib简单介绍
# urllib简介:
1.urllib模块是Python的一个请求模块
2.Python2中是urllib和urllib2相结合实现请求的发送. Python3中统一为urllib库
3.urllib是Python内置的请求库, 其包含4个模块:
(1).request模块: 模拟发送请求
(2).error模块: 异常处理模块
(3).parse模块: 工具模块, 提供关于URL的处理方法, 如拆分, 解析, 合并等
(4).robotparser模块: 识别robots协议
# 部分方法使用介绍:
# urlopen方法实现get请求:
from urllib import request
url = 'https://www.python.org'
res = request.urlopen(url)
print(res.read()) with open('python.html', 'w') as f:
f.write(res.read().decode('utf-8'))
# post请求:
import urllib.request import urllib.parse
url='https://fanyi.baidu.com/sug'
postdata=urllib.parse.urlencode({'kw':'boy'}).encode('utf-8')
res = urllib.request.urlopen(url, data=postdata)
print(res.read())
# urlretrive实现下载:
from urllib.request import urlretrieve urlretrieve('https://www.dxsabc.com/api/xiaohua/upload/min_img/20190213/20190213 XTUcIZ99B9.jpg', 'bing.jpg')
数据解析: 从响应数据中获取目标数据
数据解析:
1.正则提取: 根据正则表达式提取信息
2.xpath: 定位节点, 利用方法或属性来提取标签的文本内容, 标签的属性值
3.BS4: 定位, 提取
三. 正则
3.1正则基础语法
# 1.元字符匹配
. 匹配任意字符,除了换行符(重要)
[] 用来表示一组字符,单独列出:[abc] 匹配 'a','b'或'c'
[^...] 匹配除了字符组中字符的所有字符
\d 匹配任意数字,等价于 [0-9].
\D 匹配任意非数字
\w 匹配字母数字及下划线
\W 匹配非字母数字及下划线
\s 匹配任意空白字符,等价于 [\t\n\r\f].
\S 匹配任意非空字符
# 2.字符组: 要求在一个位置匹配的字符可能出现很多种情况, 各种情况组成一个组
[0123456789]: 匹配0到9任意字符
[0-9]: 同上
[a-z]: 匹配a到z的任意小写字母
[A-Z]: 匹配A到Z的任意大写字母
[0-9a-fA-F]: 以上三种的组合, 匹配0-9任意数组或a到f之间任意字母, 不区分大小写 自定义字符组:[a3h5] ---> 代表匹配a, 3, h, 5等字符
# 3.量词:
* 重复零次或更多次
+ 重复一次或更多次
? 非贪婪匹配 {n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
{,m} 重至多m次
# 4.边界修饰符
^ 匹配开始
$ 匹配结尾
# 5.分组(重点, 重点, 重点)
在正则表达式中添加(), 就形成了一个分组, 在re模块中优先匹配显示分组内容
import re
s = "<a href='www.baidu.com'>正则匹配实验</a>"
res = re.findall("href='(.*)'>", s)
print(res)
# 6.贪婪匹配与非贪婪匹配
贪婪匹配是指: 在使用量词: * , + 等时, 尽可能多的匹配内容
非贪婪匹配是指: 使用?对正则表达式进行修饰, 使量词的匹配尽可能少, 如+代表匹配1次或多次, 在?的修 饰下, 只匹配1次.
# 7.匹配模式
re.S 单行模式(重点)
re.M 多行模式
re.I 忽略大小写
import re
s = 'hello2world\nhello3world\nhello4world'
#re.M 多行模式
result0 = re.findall(r'\d.*d', s)
print(result0)
result1 = re.findall(r'\d.*d', s, re.M)
print(result1)
#re.S 单行模式(可以看成将所有的字符串放在一行内匹配包括换行符\n)
result2 = re.findall(r'\d.*d', s, re.S)
print(result2)
result3 = re.findall(r'\d.*?d', s, re.S)
print(result3)
3.2 re模块的使用
# 8.re模块
1.re.findall('正则表达式', '待匹配字符串'): 返回所有满足匹配条件的结果, 以列表形式返回
2.re.search('正则表达式', '带匹配字符串'): 匹配到第一个就返回一个对象, 该对象使用group()进 行取值, 如果未匹配到则返回None
3.re.match('正则表达式', '待匹配字符串'): 只从字符串开始进行匹配, 如果匹配成功返回一个对象, 同样使用group()进行取值, 匹配不成功返回None
4.re.compile('正则表达式'): 将正则表达式编译为对象, 在需要按该正则表达式匹配是可以在直接使用 该对象调用以上方法即可.
Python语言: 解释型语言
先解释在执行: 源代码 --> 简单的翻译 --> 字节码 --> 二进制语言 --> 识别的语言 .pyc文件: 执行过的文件, 生成一个.pyc文件, 再执行时对比.
C: 编译型语言
源代码 ---> 编译 ---> 二进制文件 --> 识别的语言
# 示例:
import re
s = "pythonpython你好吊"
# findall方法演示
res_findall = re.findall(r'p', s)
print('findall匹配结果:', res_findall)
# search方法演示, 不确定是否能匹配出结果, 不可直接使用group进行取值, 需要判断或进行异常处理
res_search = re.search(r"你", s)
if res_search: print('search匹配结果', res_search.group())
else:print('None')
# match方法演示:
res_match_1 = re.match(r'py', s)
res_match_2 = re.match(r'thon', s)
print('res_match_1结果:', res_match_1)
print('res_match_2结果:', res_match_2)
# compile方法演示:
re_obj = re.compile(r'python')
res = re.findall(re_obj,s)
print(res)
3.3 校花网图片爬取与requests实现多页爬取
# 9.案例:利用正则表达式抓取校花网图片
import re '
import requests
# 请求url, 抓取页面
url = 'http://www.xiaohuar.com/hua/'
3.4 包图网图片下载案例
# 案例:包图网图片下载:
import re
import requests
import random
url = 'https://ibaotu.com/sy/17-92085-0-0-0-1.html'
#默写:
1.代理ip的数据构建:
proxies = { 'https': 'http://210.22.5.117:3128', 'http': 'http://210.33.56.12:8899' }
3.在正则表达式中添加(), 就形成了一个分组, 在re模块中优先匹配显示分组内容
import re s = "<a href='www.baidu.com'>正则匹配实验</a>"
res = re.findall("href='(.*)'>", s)
print(res)
5.re.findall('正则表达式', '待匹配字符串'):
返回所有满足匹配条件的结果, 以列表形式返回
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/77020.html

