
1,web应用模式(了解)
-
目的: 知道web开发的两种模式
-
前后端分离:
- 注意点: 业务服务器和静态服务器是分开的


- 注意点: 业务服务器和静态服务器是分开的
-
前后端不分离:
- 注意点: 页面和数据都是有后端处理的
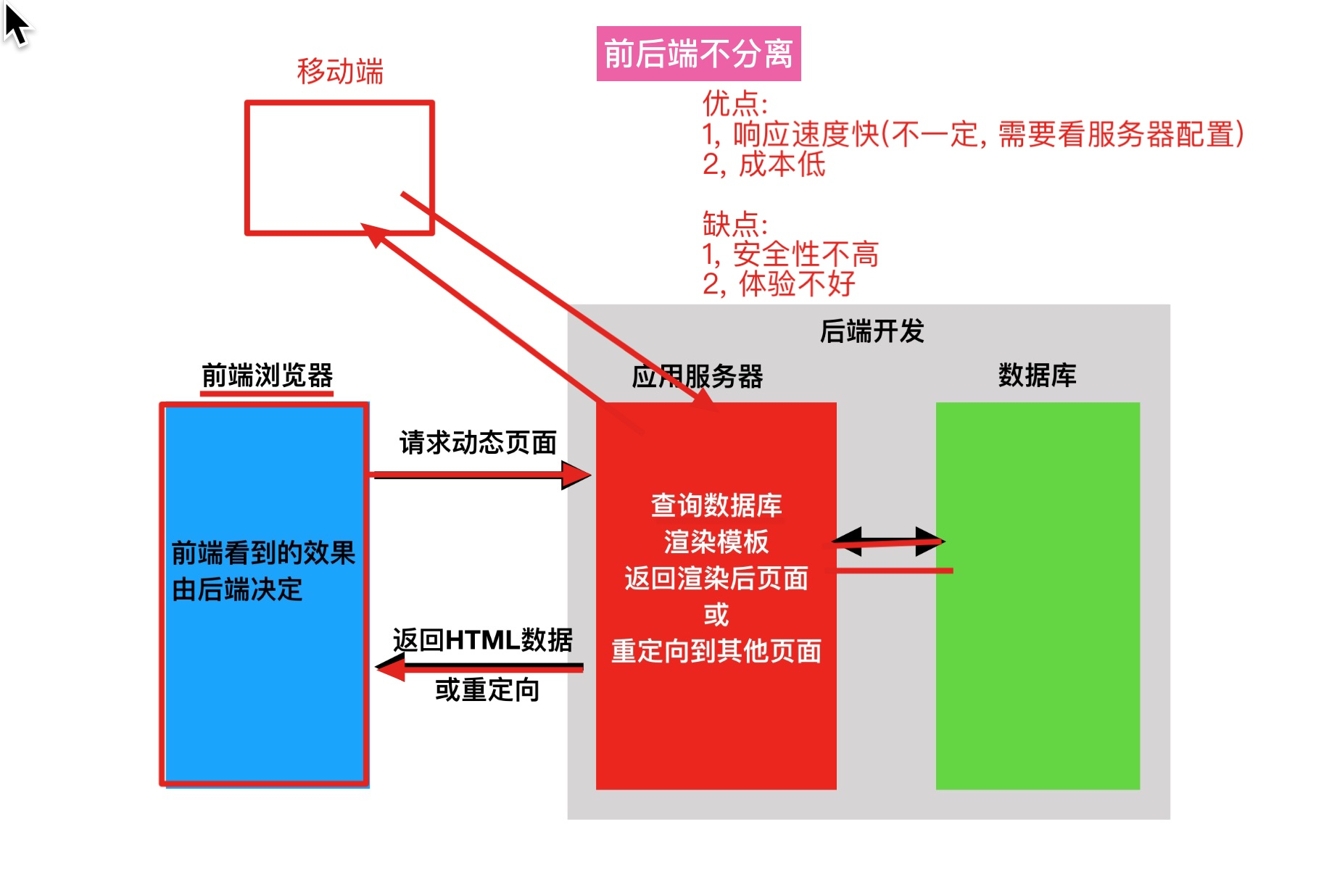
- 注意点: 页面和数据都是有后端处理的
2. restful风格介绍(了解)
- 目的: 知道为什么需要使用restful风格进行开发
- 原因
- 每个后端开发人员可能都有自己的定义方式,风格迥异
- 解决办法:
- resultful
3,restful设计风格(了解)
- 目的: 知道常见的restful风格的标准
- 具体的标准:
- 1, api部署的域名, 主域名或者专有域名
- 2, 版本, 通过url地址或者请求头accept
- 3, 路径, 只能有名词, 不能有动词
- 4, http请求动词, get, post, update, delete
- 5, 状态, 200, 201, 204, 400, 401, 403, 404
- ….
4,restful案例(了解)
-
目的: 可以使用restful风格设计图书增删改查的案例
-
案例:
功能 路径 请求方式 响应状态码 获取所有的书籍 /books get 200 创建书籍 /books post 201 获取单个书籍 /books/{id} get 200 修改书籍 /books/{id} put 201 删除书籍 /books/{id} delete 204
5,数据准备
- 目的: 可以将图书和英雄的信息添加到数据中
- 操作流程:
- 1, 创建项目, 创建booktest子应用
- 2, 在子应用中定义模型类
- 3, 注册子应用, 设置数据库配置
- 4, 创建数据库, 迁移
6,查询所有数据(理解)
- 目的: 可以编写视图查询所有的书籍信息
- 注意点:
- http.JsonResponse(books_list,safe=False)
- safe=False允许非字典数据可以被返回
- http.JsonResponse(books_list,safe=False)
7,创建对象(理解)
- 目的: 可以添加书籍对象到数据库中
- 注意点:
- book = BookInfo.objects.create(**data_dict)
8,获取单个对象(理解)
- 目的: 可以获取指定书籍对象
- 注意点:
- book = BookInfo.objects.get(id=book_id)
9,修改单个对象(理解)
- 目的: 可以修改指定书籍对象
- 注意点:
- BookInfo.objects.filter(id=book_id).update(**data_dict)
10,删除单个对象(理解)
- 目的: 可以删除指定书籍对象
- 注意点:
- BookInfo.objects.get(id=book_id).delete()
11, DRF魅力展示(了解)
-
目的: 体会DRF的强大之处即可
-
操作流程:
-
1, 注册子应用(day01/settings.py)
INSTALLED_APPS = [ ... 'rest_framework' ] -
2, 编写路由(booktest/urls.py)
#1,url部分 from rest_framework.routers import DefaultRouter router = DefaultRouter() router.register('books',views.BookViewSet,base_name="books") urlpatterns += router.urls -
3, 编写序列化器, 视图(booktest/views.py)
from rest_framework import serializers from booktest.models import BookInfo from rest_framework.viewsets import ModelViewSet #2,序列化器 class BookModelSeriralizer(serializers.ModelSerializer): class Meta: model = BookInfo fields = "__all__" #3,视图集 class BookViewSet(ModelViewSet): queryset = BookInfo.objects.all() serializer_class = BookModelSeriralizer
-
12,序列化器概述(了解)
- 目的: 知道序列化器的作用
- DRF:
- 1, 序列化器
- 2, 视图
- 3, 路由
- 序列化器的作用:
- 1, 反序列化: 把json(dict), 转成模型类对象 (校验,入库)
- 2, 序列化: 将模型类对象, 转成json(dict)数据
13,序列化器定义(掌握)
-
目的: 可以定义书籍的序列化器
-
操作流程:
from rest_framework import serializers """ 定义序列化器: 1, 定义类, 继承自Serializer 2, 编写字段名称, 和模型类一样 3, 编写字段类型, 和模型类一样 4, 编写字段选项, 和模型类一样 read_only: 只读 label: 字段说明 序列化器作用: 1, 反序列化: 将json(dict)数据, 转成模型类对象 ①: 校验 ②: 入库 2, 序列化: 将模型类对象, 转成json(dict)数据 """"" #1,定义书籍序列化器 class BookSerializer(serializers.Serializer): id = serializers.IntegerField(read_only=True,label="书籍编号") btitle = serializers.CharField(max_length=20,label="名称") bpub_date = serializers.DateField(label="发布日期") bread = serializers.IntegerField(default=0,label="阅读量") bcomment = serializers.IntegerField(default=0,label="评论量") is_delete = serializers.BooleanField(default=False,label="逻辑删除")
14,序列化器,序列化单个对象(掌握)
-
目的: 可以将单本数据使用序列化器, 转成json(dict)数据
-
操作流程:
from booktest.models import BookInfo from booktest.serializer import BookSerializer #1,获取书籍对象 book = BookInfo.objects.get(id=1) #2,创建序列化器对象, instance=book 表示将哪一本数据进行序列化 serializer = BookSerializer(instance=book) #3,输出序列化之后的结果 serializer.data """ {'id': 1, 'btitle': '射雕英雄传', 'bpub_date': '1980-05-01', 'bread': 12, 'bcomment': 34, 'is_delete': False} """
15,序列化器,序列化列表数据(掌握)
-
目的: 可以使用序列化器,对列表中的多个对象进行序列化
-
操作流程:
from booktest.models import BookInfo from booktest.serializer import BookSerializer #1,查询所有的书籍 books = BookInfo.objects.all() #2,创建序列化器对象,many=True 表示传入的是列表对象(多个数据) serializer = BookSerializer(instance=books,many=True) #3,输出序列化的结果 serializer.data """ [ OrderedDict([('id', 1), ('btitle', '射雕英雄传'), ('bpub_date', '1980-05-01'), ('bread', 12), ('bcomment', 34), ('is_delete', False)]), OrderedDict([('id' ('btitle', '天龙八部'), ('bpub_date', '1986-07-24'), ('bread', 36), ('bcomment', 40), ('is_delete', False)]), OrderedDict([('id', 3), ('btitle', '笑傲江湖'), ('bp, '1995-12-24'), ('bread', 20), ('bcomment', 80), ('is_delete', False)]), OrderedDict([('id', 4), ('btitle', '雪山飞狐'), ('bpub_date', '1987-11-11'), ('bread', 58'bcomment', 24), ('is_delete', False)]), OrderedDict([('id', 6), ('btitle', '金瓶x2'), ('bpub_date', '2019-01-01'), ('bread', 10), ('bcomment', 5), ('is_delete', Fse)]) ] """-
注意点:
- serializer = BookSerializer(instance=books,many=True)
- instance: 需要序列化的对象
- many=True: 默认是None, 如果传入True, 需要序列化的对象是列表
- serializer.data: 表示输出序列化之后的结果
-
16,英雄序列化器关联外键(掌握)
-
目的: 可以将关联英雄的书籍信息, 三种形式表示出来
-
操作流程:
1, 序列化器
-
#2,定义英雄序列化器 class HeroInfoSerializer(serializers.Serializer): """英雄数据序列化器""" GENDER_CHOICES = ( (0, 'male'), (1, 'female') ) id = serializers.IntegerField(label='ID', read_only=True) hname = serializers.CharField(label='名字', max_length=20) hgender = serializers.ChoiceField(choices=GENDER_CHOICES, label='性别', required=False) hcomment = serializers.CharField(label='描述信息', max_length=200, required=False, allow_null=True) #1,添加外键,主键表示 必须提供`queryset` 选项, 或者设置 read_only=`True`. # hbook = serializers.PrimaryKeyRelatedField(queryset=BookInfo.objects.all()) # hbook = serializers.PrimaryKeyRelatedField(read_only=True) #2,添加外键, 来自于关联模型类, __str__的返回值 # hbook = serializers.StringRelatedField(read_only=True) #3,添加外键,关联另外一个序列化器 hbook = BookSerializer(read_only=True) -
2, 类视图
""" ===============3, 英雄序列化器, 关联外键 ================= """"" from booktest.models import HeroInfo from booktest.serializer import HeroInfoSerializer #1,获取单个英雄 hero = HeroInfo.objects.get(id=1) #2,创建英雄序列化器 serializer = HeroInfoSerializer(instance=hero) #3,输出结果 serializer.data
-
17,书籍序列化器,关联many(掌握)
-
目的: 可以在序列化书籍的时候, 展示英雄的信息
-
操作流程:
#1,定义书籍序列化器 class BookSerializer(serializers.Serializer): ... #1,关联英雄字段, 在一方中,输出多方内容的时候加上many=True # heroinfo_set = serializers.PrimaryKeyRelatedField(read_only=True,many=True) heroinfo_set = serializers.StringRelatedField(read_only=True,many=True)
18,反序列化-字段类型校验
-
目的: 可以使用序列化器,对数据进行校验操作
-
操作流程:
from booktest.serializer import BookSerializer #1,准备字典数据 data_dict = { "btitle":"金瓶x-插画版", "bpub_date":"2019-01-01", "bread":15, "bcomment":25 } #2,创建序列化器对象 serializer = BookSerializer(data=data_dict) #3,校验, raise_exception=True, 校验不通过,抛出异常信息 # serializer.is_valid() serializer.is_valid(raise_exception=True)
19,反序列化-字段选项校验
-
目的: 可以使用序列化器,对数据进行选项约束校验
-
操作流程:
-
1, 序列化器
-
min_value=0
-
max_value=50
-
约束演示
class BookSerializer(serializers.Serializer): ... bread = serializers.IntegerField(default=0,min_value=0,label="阅读量") bcomment = serializers.IntegerField(default=0,max_value=50,label="评论量") is_delete = serializers.BooleanField(default=False,label="逻辑删除") -
-
2, 类视图
from booktest.serializer import BookSerializer #1,准备字典数据 data_dict = { "btitle":"金瓶x", "bpub_date":"2019-01-01", "bread":15, "bcomment":99 } #2,创建序列化器对象 serializer = BookSerializer(data=data_dict) #3,校验 # serializer.is_valid() serializer.is_valid(raise_exception=True)
-
20,反序列化-单字段校验
-
目的: 可以编写单字段校验方法, 对btitle进行校验
-
操作流程:
-
1, 序列化器
class BookSerializer(serializers.Serializer): ... #3, 单字段校验, 方法; 需求: 添加的书籍必须包含'金瓶' def validate_btitle(self, value): print("value = {}".format(value)) #1,判断传入的value中是否包含金瓶 if "金瓶" not in value: raise serializers.ValidationError("书名必须包含金瓶") #2,返回结果 return value -
2, 类视图
from booktest.serializer import BookSerializer #1,准备字典数据 data_dict = { "btitle":"金瓶x", "bpub_date":"2019-01-01", "bread":15, "bcomment":5 } #2,创建序列化器对象 serializer = BookSerializer(data=data_dict) #3,校验 # serializer.is_valid() serializer.is_valid(raise_exception=True)
-
-
注意点:
- 单字段校验方法
- def validate_字段名(self,value):
- pass
- def validate_字段名(self,value):
- 如果校验不通过,直接抛出异常即可
- 单字段校验方法
21,反序列化-多字段校验
-
目的: 可以编写多字段校验方法, 对阅读量和评论量进行判断
-
操作流程:
-
1, 序列化器
class BookSerializer(serializers.Serializer): ... #4,多字段校验, 方法; 添加书籍的时候,评论量不能大于阅读量 def validate(self, attrs): """ :param attrs: 外界传入的需要校验的字典 :return: """ #1,判断评论量和阅读量的关系 if attrs["bread"] < attrs["bcomment"]: raise serializers.ValidationError("评论量不能大于阅读量") #2,返回结果 return attrs -
2, 类视图
""" ===============7, 反序列化-多字段校验 ================= """"" from booktest.serializer import BookSerializer #1,准备字典数据 data_dict = { "btitle":"金瓶xxx", "bpub_date":"2019-01-01", "bread":33, "bcomment":22 } #2,创建序列化器对象 serializer = BookSerializer(data=data_dict) #3,校验 # serializer.is_valid() serializer.is_valid(raise_exception=True)
-
22,反序列化-自定义校验(理解)
-
目的: 可以自定义方法,对日期进行校验
-
操作流程:
-
1, 序列化器
#需求: 添加的书籍的日期不能小于2015年 def check_bpub_date(date): print("date = {}".format(date)) if date.year < 2015: raise serializers.ValidationError("日期不能小于2015年") return date #1,定义书籍序列化器 class BookSerializer(serializers.Serializer): ... bpub_date = serializers.DateField(label="发布日期",validators=[check_bpub_date]) -
2, 类视图
""" ===============8, 反序列化-自定义校验 ================= """"" from booktest.serializer import BookSerializer #1,准备字典数据 data_dict = { "btitle":"金瓶xxx", "bpub_date":"2011-11-01", "bread":11, "bcomment":5 } #2,创建序列化器对象 serializer = BookSerializer(data=data_dict) #3,校验 # serializer.is_valid() serializer.is_valid(raise_exception=True)
-
23,反序列化-数据入库create(掌握)
-
目的: 可以将书籍对象保存到数据库中
-
操作流程:
-
1, 序列化器
class BookSerializer(serializers.Serializer): ... #5,重写create方法,实现数据入库 def create(self, validated_data): # print("validated_data = {}".format(validated_data)) #1,创建book对象,入库 book = BookInfo.objects.create(**validated_data) #2,返回响应 return book -
2, 类视图
from booktest.serializer import BookSerializer #1,准备字典数据 data_dict = { "btitle":"金瓶xxx-精装版", "bpub_date":"2015-11-01", "bread":11, "bcomment":5 } #2,创建序列化器对象 serializer = BookSerializer(data=data_dict) #3,校验 # serializer.is_valid() serializer.is_valid(raise_exception=True) #4,入库 serializer.save() -
注意点:
![- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cN0RHng3-1643016498926)(04_笔记.assets/image-20191217154212337.png)]](https://blog-1305504063.cos.ap-beijing.myqcloud.com/02572f8c-9571-11ed-8895-5cea1d84200c.png)
-
24,反序列化-数据更新update(掌握)
-
目的: 可以重写update方法, 更新数据库中指定的书籍
-
操作流程:
-
1, 序列化器
class BookSerializer(serializers.Serializer): ... #6,重写update方法,实现数据更新 def update(self, instance, validated_data): """ :param instance: 需要更新的对象 :param validated_data: 验证成功之后的数据 :return: """ #1,更新数据 instance.btitle = validated_data["btitle"] instance.bpub_date = validated_data["bpub_date"] instance.bread = validated_data["bread"] instance.bcomment = validated_data["bcomment"] instance.save() #2,返回数据 book = BookInfo.objects.get(id=instance.id) return book -
2, 类视图
from booktest.serializer import BookSerializer from booktest.models import BookInfo #1,准备字典数据 book = BookInfo.objects.get(id=8) data_dict = { "btitle":"金瓶xxx-连环画", "bpub_date":"2019-11-11", "bread":30, "bcomment":20 } #2,创建序列化器对象 serializer = BookSerializer(instance=book,data=data_dict) #3,校验 # serializer.is_valid() serializer.is_valid(raise_exception=True) #4,入库 serializer.save() -
注意点:
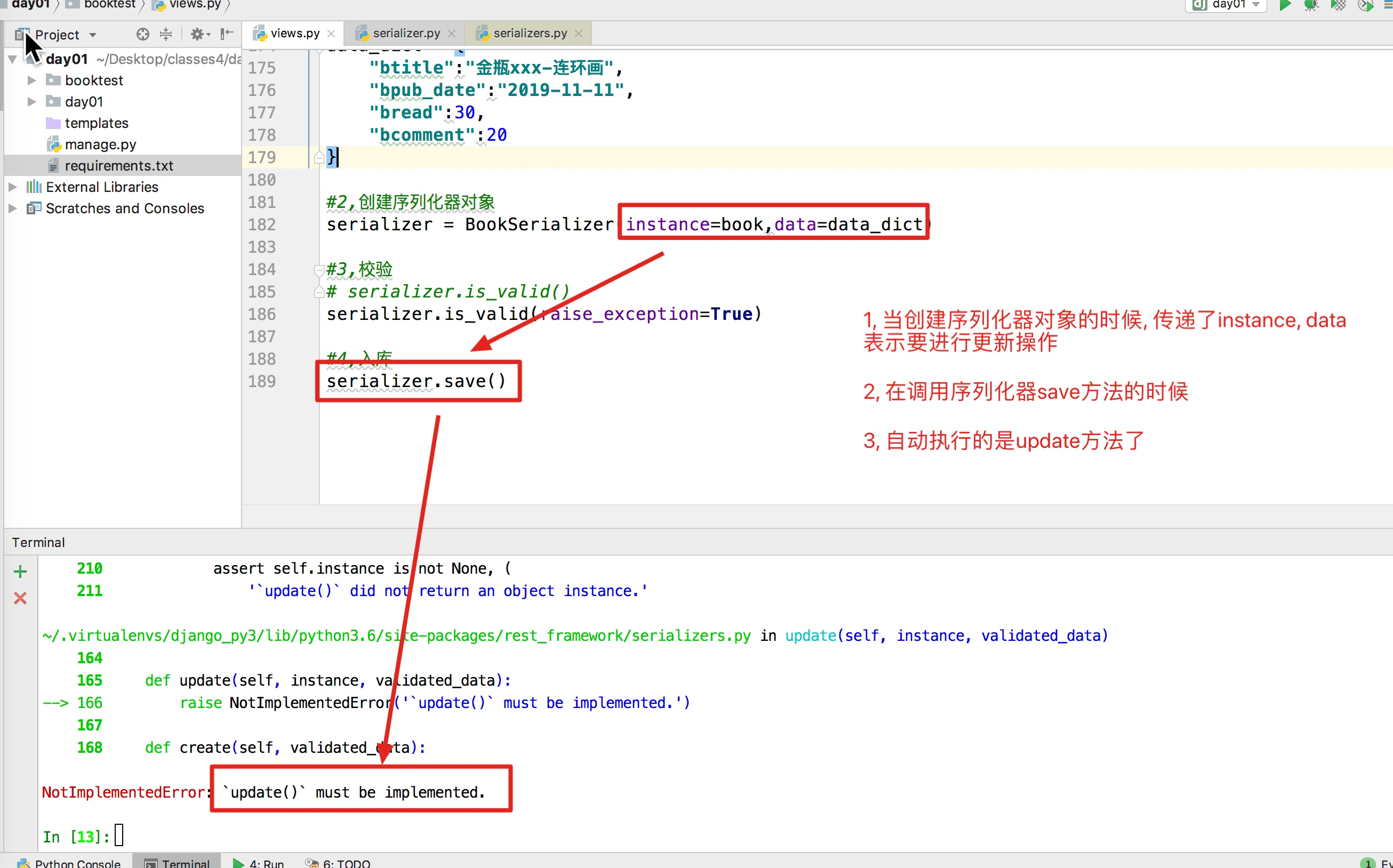
-
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/77086.html

