
一. Redis 入门
Redis 是一个开源的使用ANSI C 语言编写、支持网络、可基于内存亦持久化的日志型、key-value 数据库、并提供多种语言的Api
1. redis 安装在磁盘中
2. redis 的数据存储到内存中
3. redis 是一种键值对(key-value) 高性能缓存数据库。
4. 支持 String、 List 、 Hash、 Set、 Zset
redis 解决了什么问题
二. redis 特性
1) 速度快
2) 键值对的数据结构服务器
3) 丰富的功能
4) 简单稳定
5) 持久化
6) 主从复制
7) 高可用和分布式转移
8) 客户端语言多
三. 使用场景
1 . 缓存数据库
2. 排行榜
3. 计数器使用
4. 消息队列
5. 社交网络
四. redis 配置 启动 操作 关闭
redis-server 启动redis
redis-cli redis 命令行客户端
redis-benchmark 基准测试工具
redis-check-aof AOF 持久化文件检测和修复工具
redis-check-dump RDB 持久化 文件检测和修复工具
redis-sentinel 启动哨兵
redis-trib cluster 集群测试工具
五. 重大版本
1. 版本号第二位为奇数, 为非稳定版 (2.7 2.9, 3.1 )
2. 第二位为偶数 为非稳定版(2.6, 2.8. 3.0 )
3. 当前奇数版是下一稳定版本的开发版本 如2.9 是 3.0 的开发版
数据结构— 字符串(String)
字符串类型: 实际上可以是字符串(包含XML ,JSON )
还有 数字(整形浮点数), 二进制 (图片 音频 视频) ,最大不能超过 512MB
设置命令:
set age 23 ex 10 // 10 秒后过期 px ,10000 毫秒过期
setnx name test // 不存在键name时,返回1 设置成功, 存在的话失败0
set age 25 xx // 存在键age时, 返回1 成功
执行命令: get age // 存在则返回value, 不存在返回nil
批量设置: mset country china city bejing
批量获取: mget contry city address // 返回china beijing, address 为nil
常用名命令- 字符串(计数)
incr age // 必须为整数自动加1, 非整数返回错误 无age 键 从0 自增返回1
decr age // 整数age 减 1
incrby age 2 // 整数age + 2
decrby age 2 // 整数age -2
incrby score 1.1 // 浮点数score + 1.1
常用命令 – 字符串(追加)
append追加命令:
set name hello;
append name world // 追加成功
字符串长度
set hello"世界";
strlen hello 结果6 每个中文占三个字节
截取字符串
set name helloworld;
getrange name 2 4 // 返回 lio
数据结构 – Hash(哈希)
1.哈希 hash 是一个 string 类型的field 和 value 的映射表 ,hash 特别适应于 存储对象
操作指令:hmset user:1 name qiqi age 18
哈希hash 是一个string 类型得field 和 value 的映射表,hash特适合用于存储对象
命令 hset key field value
设值: hset user:1 name laoqi
取值: hget user:1 name
删值: hdel user:1 age
计算个数:hset user:1 name james; hset user:1 age 23;
hlen user:1 //返回2,user:1有两个属性值
批量设值:hmset user:2 name james age 23 sex boy //返回OK
批量取值:hmget user:2 name age sex //返回三行:james 23 boy
判断field是否存在:hexists user:2 name //若存在返回1,不存在返回0
获取所有field: hkeys user:2 // 返回name age sex三个field
获取user:2所有value:hvals user:2 // 返回james 23 boy
获取user:2所有field与value:hgetall user:2 //name age sex james 23 boy值
增加1:hincrby user:2 age 1 //age+1
hincrbyfloat user:2 age 2 //浮点型加2
三种方案实现用户信息存储优点
- 原生:
set user:1:name laoqi;
set user:1:age 23;
set user:1:sex boy;
优点:简单直观 每个键对应一个值
缺点: 键数过多,占用内存多,用户信息过于分散,不用于生产环境
- 将对象序列化存入redis
set user:1 serialize(userInfo);
优点:编程简单,若使用序列化合理内存使用率高
缺点:序列化与反序列化有一定开销,更新属性时需要把 userInfo全取出来进行反序列化,更新后再序列化到redis
- 使用hash 类型
hmset user:1 name james age 23 sex boy
优点:简单直观,使用合理可减少内存空间消耗
缺点:要控制ziplist与hashtable两种编码转换,且 hashtable会消耗更多内存erialize(userInfo);
数据结构 – 列表< list >
用来存储多个有序的字符串,一个列表最多可存2的32次方减1个元素
因为有序,可以通过索引下标获取元素或某个范围内元素列表,列表元素可以重复。
添加命令:
rpush james c b a //从右向左插入cba, 返回值3
lrange james 0 -1 //从左到右获取列表所有元素 返回 c b a
lpush key c b a //从左向右插入cba
linsert james before b teacher //在b之前插入teacher, after为之后,使用lrange james 0 -1 查看:c teacher b a
查找命令:
lrange key start end //索引下标特点:从左到右为0到N-1
lindex james -1 //返回最右末尾a,-2返回b
llen james //返回当前列表长度
lpop james //把最左边的第一个元素c删除
rpop james //把最右边的元素a删除
数据结构 – 集合< set >
用户标签,社交,查询有共同兴趣爱好的人,智能推荐
保存多元素,与列表不一样的是不允许有重复元素,且集合是无序,一个集合最多可存2的32次方减1个元素,除了支持增删改查,还支持集合交集、并集、差集;
集全<set>命令:
exists user //检查user键值是否存在
sadd user a b c //向user插入3个元素,返回3
sadd user a b //若再加入相同的元素,则重复无效,返回0
smembers user //获取user的所有元素,返回结果无序
srem user a //返回1,删除a元素
scard user //返回2,计算元素个数
Redis 全局命令
1.查看所有键:
keys * set school enjoy
set hello world
keys *ool -----> school
2.键总数 :
dbsize
//2个键,如果存在大量键,线上禁止使用此指令
3.检查键是否存在:
exists key //存在返回1,不存在返回0
4,键过期:
expire key seconds //set name test expire name 10,表示10秒过期
ttl key // 查看剩余的过期时间
5,键的数据结构类型:
type key //返回string,键不存在返回none
redis 数据库管理
redis 数据库管理方式
默认支持16个数据库;可以理解为一个命名空间
跟关系型数据库不一样的点
redis不支持自定义数据库名词
每个数据库不能单独设置授权
每个数据库之间并不是完全隔离的。 可以通过flushall命令清空redis实例面的所有数据库中的数据
缓存雪崩
前提:为节约内存,Redis一般会做定期清除操作,
1,当查询 key=james的值,此时Redis没有数据
2,如果有5000个用户并发来查询key=james,全到Mysql里去查, Mysql会挂掉;
缓存穿透
前提:黑客模拟一个不存在的订单号xxxx
1,Redis中无此值
2,Mysql中也无此值, 但一直被查询
解决方案:
1,对订单表所有数据查询出来放到布隆过滤器, 经过布隆过滤器处理的数据很小(只存0或1)
2,每次查订单表前,先到过滤器里查询当前订单号状态是0还是1, 0的话代表数据库没有数据
Redis持久化机制
redis是一个支持持久化的内存数据库,也就是说redis需要经常将内存中的数据同步到磁盘来保证持久化,持久化可以避免因进程退出而造成数据丢失
RDB持久化方式
RDB持久化把当前进程数据生成快照(.rdb)文件保存到硬盘的过程,有手动触发和自动触发
手动触发有save和bgsave两命令
save命令:阻塞当前Redis,直到RDB持久化过程完成为止,若内存实例比较大会造成长时间阻塞,线上环境不建议用它
bgsave命令:redis进程执行fork操作创建子进程,
由子线程完成持久化,阻塞时间很短(微秒级),是save的优化,在执行redis-cli shutdown关闭redis服务时,
如果没有开启AOF持久化,自动执行bgsave;
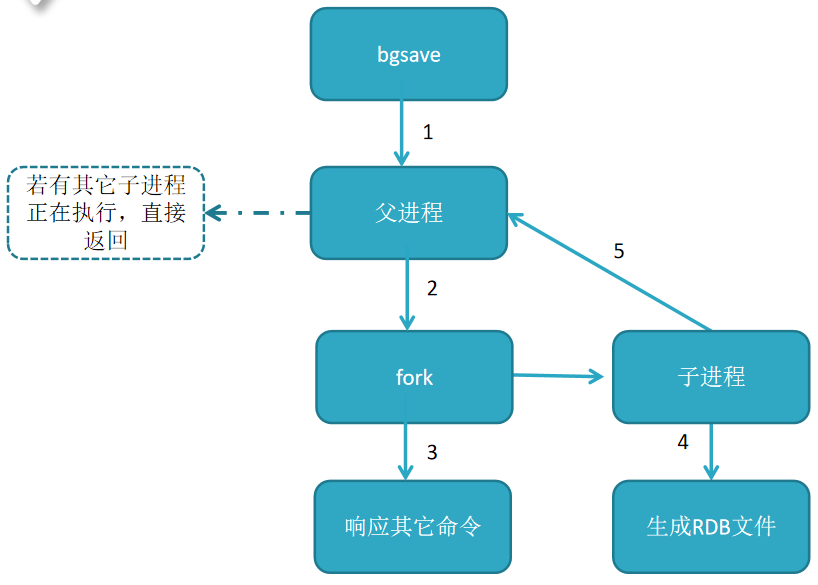
RDB文件的操作
命令:config set dir /usr/local //设置rdb文件保存路径
备份:bgsave //将dump.rdb保存到usr/local下
恢复:将dump.rdb放到redis安装目录与redis.conf同级目录,重启redis即可
优点:1.压缩后的二进制文,适用于备份、全量复制,用于灾难恢复
2.加载RDB恢复数据远快于AOF方式
缺点:1.无法做到实时持久化,每次都要创建子进程,频繁操作成本过高
2.保存后的二进制文件,存在老版本不兼容新版本rdb文件的问题
AOF 持久化
针对RDB不适合实时持久化,redis提供了AOF持久化方式来解决
开启:redis.conf设置:appendonly yes (默认不开启,为no)
默认文件名:appendfilename "appendonly.aof"
AOF持久化流程:
流程说明:
1,所有的写入命令(set hset)会append追加到aof_buf缓冲区中
2,AOF缓冲区向硬盘做sync同步
3,随着AOF文件越来越大,需定期对AOF文件rewrite重写,达到压缩
4,当redis服务重启,可load加载AOF文件进行恢复
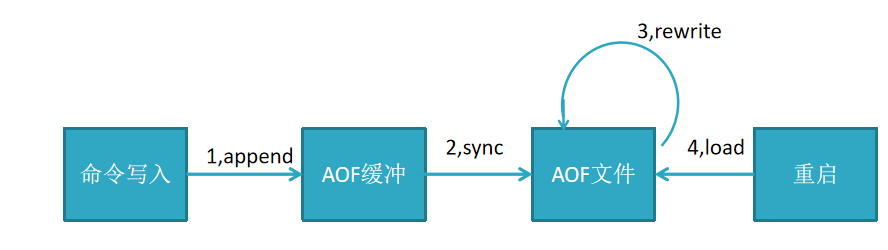
命令写入(append), 文件同步(sync), 文件重写(BGREWRITEAOF), 重启加载(load)
AOF 的配置详情
appendonly yes //启用aof持久化方式
# appendfsync always //每收到写命令就立即强制写入磁盘,最慢的,但是保证完全的持久化,不推荐使用
appendfsync everysec
//每秒强制写入磁盘一次,性能和持久化方面做了折中,推荐
no-appendfsync-on-rewrite yes
//正在导出rdb快照的过程中,要不要停止同步aof
auto-aof-rewrite-percentage 100
//aof文件大小比起上次重写时的大小,增长率100%时,重写
auto-aof-rewrite-min-size 64mb
//aof文件,至少超过64M时,重写
AOF 如何恢复
- 设置appendonly yes;
- 将appendonly.aof放到dir参数指定的目录;
- 启动Redis,Redis会自动加载appendonly.aof文件。
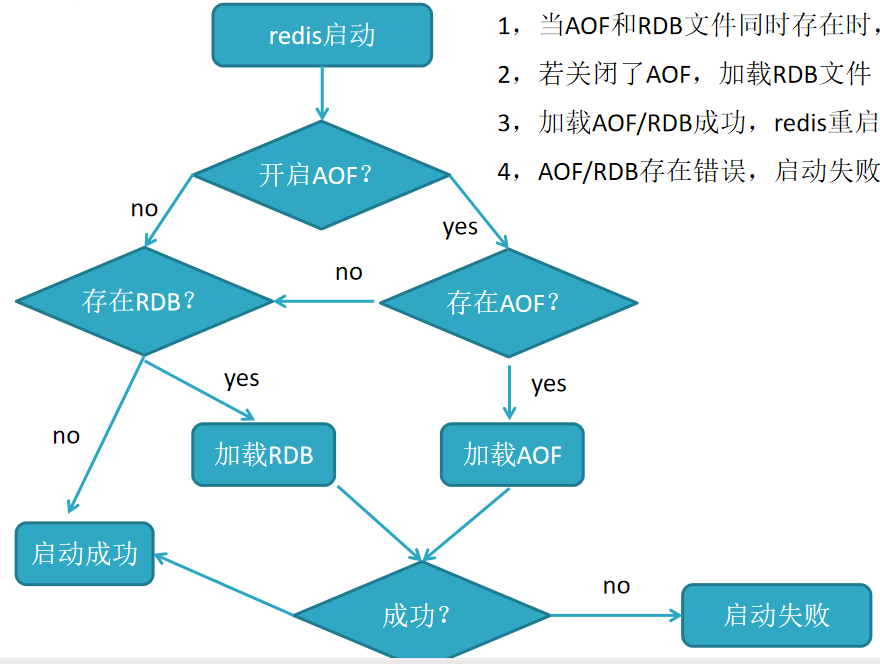
redis重启时加载AOF与RDB的顺序
1,当AOF和RDB文件同时存在时,优先加载
2,若关闭了AOF,加载RDB文件
3,加载AOF/RDB成功,redis重启成功
4,AOF/RDB存在错误,启动失败打印错误信息
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/77115.html

