
在SQL语句之间加上explain之后在执行就可以看到分析SQL相关信息:
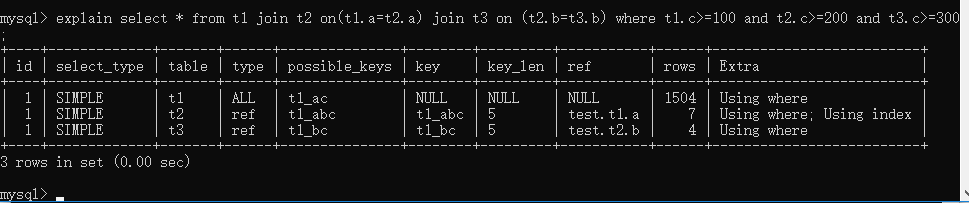
根据上图所示对每一列都进行分析
id:select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序
- id相同,执行顺序由上至下
- id不同,如果是子查询,id的序列号会递增,id值越大优先级越高,越先被执行
- id有相同也有不同,id如果相同,可以认为是一组,从上往下顺序执行;在所有组中,id值越大,优先级越高,越先执行
- id为null的记录,union 或者union all查询结果会放到临时表中,看到表名格式为<union1,2>
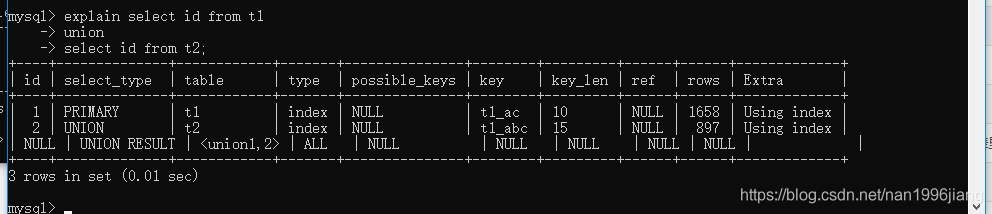

select_type:表示select的类型,常见有如下几种:
| 类型 | 说明 |
|---|---|
| SIMPLE | 简单表不使用表连接和子查询 |
| PRIMARY | 主查询,即外层的查询 |
| DERIVED | 在from列表中包含的子查询被标记为derived(衍生),mysql或递归执行这些子查询,把结果放在临时表里 |
| SUBQUERY | 子查询中的第一个 |
| UNION | UNION中的第二个或者后面的查询语句 |
| UNION RESULT | 从union表获取结果的select |
table:输出查询语句的表名称或者表别名
type:表示MySQL在表种找到所需要行的方式或者叫做访问类型,从上到下性能由差到好
| ALL | 全表扫描 |
|---|---|
| index | 走索引的全表扫描 |
| range | 命中where自居的范围索引扫描 |
| index_merge | 索引合并 |
| ref ;eq_ref | 非唯一性索引扫描,返回匹配某个单独值的所有行。;一性索引扫描,对于每个索引键,表中只有一条记录与之匹配 |
| const;system | 常量扫描表示通过索引一次就找到了,单表最多有一个匹配 |

possible_keys:表查询可能使用到的索引
key:实际使用的索引
key_len:使用索引字段的长度
ref:使用哪一列与key一起从表种选择
rows:扫描行数量
Extra:执行情况的说明和描述,不适合在其他列中展示但是对执行计划重要的额外信息
主要有如下几种:
| Using index(索引覆盖) | 表示索引覆盖,不会回表查询 |
|---|---|
| Using where(索引回表) | 表示进行了回表操作 |
| Using index condition(索引下推) | 表示进行了ICP优化 |
| Using fiesort | 表示mysql需额外排序操作,不能通过索引顺序达到排序效果 |
| Using temporary | 使用临时表保存中间结果,也就是说mysql在对查询结果排序时使用了临时表,常见于order by 和 group by |
| Using join buffer | 使用join查询的时候会用到 |
| Impossible WHERE | where子句的值总是false,不能用来获取任何数据 |

你知道的越多不知道的越多
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/77231.html

