
31、百万级或千万级以上的数据,该如何删除
- 如果是频繁更新的业务表,应该在使用时间少的时候进行删除,删除的时候可以分批次删除,减少大事务的产生导致业务更新出问题
- 也可以先删除索引,在删除无用数据最后在重建索引
32、什么是最左前缀原则?什么是最左匹配原则?
- 最左前缀原则,就是最左优先,在创建多列索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边。
- 创建联合索引的时候,例如(a,b,c),相当于创建了(a),(a,b)和(a,b,c)三个索引,这就是最左匹配原则
33、覆盖索引、索引回表以级索引下推
CREATE TABLE `t` (
`id` int(11) NOT NULL,
'name' varchar(128) NOT NULL,
'address' varchar(128) NOT NULL,
'age' int NOT NULL DEFAULT 0,
PRIMARY KEY (`id`),
KEY `idx_nameAge`(`name`,'age'),
KEY 'idx_address'('address')
) ENGINE=InnoDB;
- 索引覆盖查询的时候,根据非聚簇索引查出
select id,name from t where name = 'nj';
- 索引回表:根据二级索引查不出所有数据需要回主键索引叶子节点查所有数据
select * from t where name 'nj';
- 索引下推:对查出的结果进行过滤减少回表次数
select * from t where name like '张%' and age =10;
34、B+树在满足聚簇索引和覆盖索引的时候不需要回表查询数据
- InnoDB中,只有主键是聚簇索引,如果没有主键,则挑选一个唯一键建立聚簇索引。如果没有唯一键,则隐式的生成一个键来建立聚簇索引。
- 当查询使用聚簇索引时,对应的叶子节点可以获取到整行数据,因此不需要在回表查询。
35、从锁的类别角度讲,MySQL都有哪些锁呢?
//共享锁
select * from table where ? lock in share mode;
//排它锁
select * from table where ? for update;
- 共享锁(S):又称读锁。 允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
- 排他锁(X):又称写锁。 允许获取排他锁X的事务更新数据,阻止其他事务取得相同的数据集共享读锁S和排他写锁X。若事务T对数据对象A加上X锁,事务T可以读A也可以修改A,其他事务不能再对A加任何锁,直到T释放A上的锁。
排他锁指的是一个事务在一行数据加上排他锁后,其他事务不能再在其上加其他的锁。加过排他锁的数据行在其他事务种是不能修改数据的,也不能通过for update和lock in share mode锁的方式查询数据,但可以直接通过select …from…查询数据,因为普通查询没有任何锁机制。
为了允许行锁和表锁共存,实现多粒度锁机制,InnoDB还有两种内部使用的意向锁(Intention Locks),这两种意向锁都是表锁。 - 意向共享锁(IS):事务打算给数据行共享锁,事务在给一个数据行加共享锁前必须先取得该表的IS锁。
- 意向排它锁(IX):事务打算给数据行加排他锁,事务在给一个数据行加排他锁前必须先取得该表的IX锁。
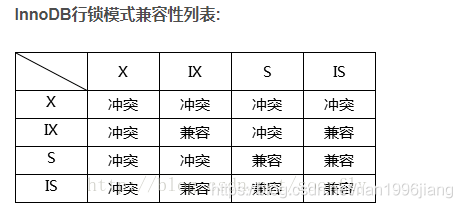

36、MySQL中InnoDB当中的行锁如何实现实现
- for update 可以根据条件来完成行锁锁定,并且 id 是有索引键的列,如果 id 不是索引键那么InnoDB将实行表锁。
select id,name,address,age from t where id = 1 for update;
select * from t where id = 1 lock in share mode;
37、什么是视图?为什么要使用视图?
- 视图时一个虚拟的表,是一个表中的数据经过筛选后显示方式,视图由一个预定义的查询select语句组成。
- 为了提高复杂SQL语句的复用性和表操作的安全性,MySQL数据库管理系统提供了视图特性。
38、视图的特点以级使用场景
视图特点:
- 视图的列可以来自不同的表,是表的抽象和在逻辑意义上建立的新关系。
- 视图是由基本表(实表)产生的表(虚表)。
- 视图的建立和删除不影响基本表。
- 对视图内容的更新(添加,删除和修改)直接影响基本表。
- 当视图来自多个基本表时,不允许添加和删除数据。
视图用途:简化sql查询,提高开发效率,兼容老的表结构。
视图使用场景:
- 重用SQL语句;
- 简化复杂的SQL操作。
- 使用表的组成部分而不是整个表;
- 保护数据
- 更改数据格式和表示。视图可返回与底层表的表示和格式不同的数据。
39、视图的优缺点
- 查询简单化。视图能简化用户的操作
- 数据安全性。视图使用户能以多种角度看待同一数据,能够对机密数据提供安全保护
- 逻辑数据独立性。视图对重构数据库提供了一定程度的逻辑独立性
40、count(1)、count(*) 与 count(列名) 的区别?
- count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL
- count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL
- count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。

41、什么是触发器?触发器的使用场景都有什么
可以对某个表添加触发器,某个操作之后触发触发器操作。
- 可以通过数据库中的相关表实现级联更改;
- 实时监控某张表中的某个字段的更改而需要做出相应的处理;
42、MySQL的6种类触发器
- Before Insert
- After Insert
- Before Update
- After Update
- Before Delete
- After Delete
43、MySQL 约束有哪几种?
- NOT NULL:该字段不能为NULL
- UNIQUE:该字段具有唯一性约束,一个表允许有多个UNIQUE;
- PRIMARY KEY:约束该字段唯一不可重复,一个表只允许有一个主键;
- FOREIGN KEY: 用于预防破坏表之间连接的动作,也能防止非法数据插入外键。
- CHECK: 用于控制字段的值范围。
44、varchar(字段大小值)的含义?
- 该字段最多存放设置的字段大小值;
- 该字段存储值固定字符串所占的空间一样,设置字段大小值越大,后者在排序时会消耗更多内存。
45、delete、drop和truncate 删除表的对比
| delete | drop | truncate | |
|---|---|---|---|
| 类型 | DML | DDL | DDL |
| 是否可回滚 | 可以 | 不可以 | 不可以 |
| 删除内容 | 根据条件删除数据,表结构还存在 | 从数据库删除表,所有数据行以级索引和权限也被删除 | 重建表,删除所有数据保留表结构 |
| 删除速度 | 谨慎使用容易造成大事务,一般在业务低峰期进行 | 删除速度最快 | 删除速度快 |
46、UNION 与UNION ALL的区别
- UNION:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;
- UNION ALL:对两个结果集进行并集操作,包括重复行,不进行排序;
47、主键使用自增ID还是UUID,为什么?
如果是单机的话使用自增id,如果是分布式系统优先考虑UUID,可参考雪花算法。
- 自增ID:数据存储空间小,查询效率高。但是如果数据量过大,会超出自增长的值范围,多库合并,也有可能有问题。
- UUID:适合大量数据的插入和更新操作,但是它无序的,插入数据效率慢,占用空间大。
48、MySQL的自增主键id值用完了该如何呢?
49、MySQL字段为什么要求定义字段非空?
- 因为null值可能会比原有字段占用更多字节,也有可能会导致查询的时候索引失效
50、MySQL数据库cpu突然飙升,该如何排查问题呢?
- 使用top命令查看是mysqld导致还是其他原因;
- 如果是mysqld导致的,show processlist,查看session情况,确定是不是有消耗资源的sql在运行。
- 找出消耗高的 sql,看看执行计划是否准确, 索引是否缺失,数据量是否太大。
- kill 掉这些线程(同时观察 cpu 使用率是否下降);
- 进行相应的调整(比如说加索引、改 sql、改内存参数);
- 还有肯能是sql消耗资源并不大,而是在某一时间大量session连接进来导致CPU飙升。
你知道的越多你不知道的越多
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/77239.html

